https://ift.tt/L15CHEG Data Lineage is Broken — Here Are 5 Ways to Fix It Data lineage should be less like a treasure map and more like Go...
Data Lineage is Broken — Here Are 5 Ways to Fix It
Data lineage should be less like a treasure map and more like Google Maps

Data lineage isn’t new, but automation has finally made it accessible and scalable — to a certain extent.
In the old days (way back in the mid-2010s), lineage happened through a lot of manual work. This involved identifying data assets, tracking them to their ingestion sources, documenting those sources, mapping the path of data as it moved through various pipelines and stages of transformation, and pinpointing where the data was served up in dashboards and reports. This traditional method of documenting lineage was time-intensive and nearly impossible to maintain.
Today, automation and ML have made it possible for vendors to begin offering data lineage solutions at scale. And data lineage should absolutely be a part of the modern data stack — but if lineage isn’t done right, these new versions may be little more than eye candy.
So it’s time to dive deeper. Let’s explore how the current conversation around data lineage is broken, and how companies looking for meaningful business value can fix it.
What is data lineage? And why does it matter?
First, a quick refresher. Data lineage is a type of metadata that traces relationships between upstream and downstream dependencies in your data pipelines. Lineage is all about mapping: where your data comes from, how it changes as it moves throughout your pipelines, and where it’s surfaced to your end consumers.
As data stacks grow more complex, mapping lineage becomes more challenging. But when done right, data lineage is incredibly useful. Lineage helps data teams:
- Understand how changes to specific assets will impact downstream dependencies, so they don’t have to work blindly and risk unwelcome surprises for unknown stakeholders.
- Troubleshoot the root cause of data issues faster when they do occur, by making it easy to see at-a-glance what upstream errors may have caused a report to break.
- Communicate the impact of broken data to consumers who rely on downstream reports and tables — proactively keeping them in the loop when data may be inaccurate and notifying them when any issues have been resolved.
Unfortunately, some new approaches to data lineage focus more on attractive graphs than compiling a rich, useful map. Unlike the end-to-end lineage achieved through data observability, these surface-level approaches don’t provide the robust functionality and comprehensive, field-level coverage required to deliver the full value that lineage can provide.

Let’s explore signals that lineage may be broken, and ways data teams can find a better approach.
- Focus on quality over quantity through lineage
Modern companies are hungry to become data-driven, but collecting more data isn’t always what’s best for the business. Data that isn’t relevant or useful for analytics can just become noise. Amassing the biggest troves of data doesn’t automatically translate to more value — but it does guarantee higher storage and maintenance costs.
That’s why big data is getting smaller. Gartner predicts that 70% of organizations will shift their focus from big data to small and wide data over the next few years, adopting an approach that reduces dependencies while facilitating more powerful analytics and AI.
Lineage should play a key role in these decisions. Rather than simply using automation to capture and produce surface-level graphs of data, lineage solutions should include pertinent information such as which assets are being used and by whom. With this fuller picture of data usage, teams can begin to get a better understanding of what data is most valuable to their organization. Outdated tables or assets that are no longer being used can be deprecated to avoid potential issues and confusion downstream, and help the business focus on data quality over quantity.
- Surface what matters through field-level data lineage
Petr Janda recently published an article about how data teams need to treat lineage more like maps — specifically, like Google Maps. He argues that lineage should be able to facilitate a query to find what you’re looking for, rather than relying on complex visuals that are difficult to navigate through. For example, you should be able to look for a grocery store when you need a grocery store, without your view being cluttered by the surrounding coffee shops and gas stations that you don’t actually care about. “In today’s tools, data lineage potential is untapped,” Petr writes. “Except for a few filters, the lineage experiences are not designed to find things; they are designed to show things. That’s a big difference.”
We couldn’t agree more. Data teams don’t need to see everything about their data — they need to be able to find what matters to solve a problem or answer a question.
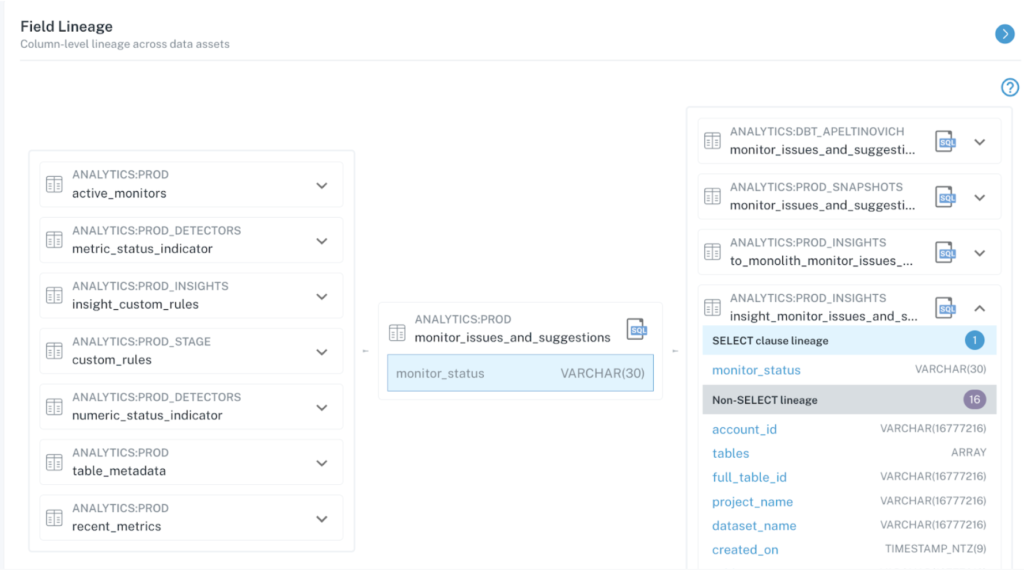
This is why field-level lineage is essential. While table-level lineage has been the norm for several years, when data engineers want to understand exactly why or how their pipelines break, they need more granularity. Field-level lineage helps teams zero in on the impact of specific code, operational, and data changes on downstream fields and reports.
When data breaks, field-level lineage can surface the most critical and widely used downstream reports that are impacted. And that same lineage reduces time-to-resolution by allowing data teams to quickly trace back to the root cause of data issues.
- Organize data lineage for clearer interpretation
Data lineage can follow in the footsteps of Google Maps in another way: by making it easy and clear to interpret the structure and symbols used in lineage.
Just as Google Maps uses consistent icons and colors to indicate types of businesses (like gas stations and grocery stores), lineage should apply clear naming conventions and colors for the data it’s describing, down to the logos used for the different tools that make up our data pipelines.
As data systems grow increasingly complex, organizing lineage for clear interpretation will help teams get the most value out of their lineage as quickly as possible.
- Include the right context in data lineage
While amassing more data for data’s sake may not help meet your business needs, collecting and organizing more metadata — with the right business context — is probably a good idea. Data lineage that includes rich, contextual metadata is incredibly useful because it helps teams troubleshoot faster and understand how potential schema changes will affect downstream reports and stakeholders.
With the right metadata for a given data asset included in the lineage itself, you can get the answers you need to make informed decisions:
- Who owns this data asset?
- Where does this asset live?
- What data does it contain?
- Is it relevant and important to stakeholders?
- Who is relying on this asset when I’m making a change to it?
When this kind of contextual information about how data assets are used within your business is surfaced and searchable through robust data lineage, incident management becomes easier. You can resolve data downtime faster, and communicate the status of impacted data assets to the relevant stakeholders in your organization.
- Scale data lineage to meet the needs of the business
Ultimately, data lineage has to be rich, useful, and scaleable in order to be valuable. Otherwise, it’s just eye candy that looks nice in executive presentations but doesn’t do much to actually help teams prevent data incidents or resolve them faster when they do occur.
We mentioned earlier that lineage has become the hot new layer in the data stack because of automation. And it’s true that automation solves half of this problem: it can help lineage scale to accommodate new data sources, new pipelines, and more complex transformations.
The other half? Making lineage useful by integrating metadata about all your data assets and pipelines in one cohesive view.
Again, consider maps. A map isn’t useful if it only shows a portion of what exists in the real world. Without comprehensive coverage, you can’t rely on a map to find everything you need or to navigate from point A to point B. The same is true for data lineage.
Lineage must scale through automation without skimping on coverage. Every ingestor, every pipeline, every layer of the stack, and every report must be accounted for, down to the field level — while being rich and discoverable so teams can find exactly what they’re looking for, with a clear organization that makes information easy to interpret, and the right contextual metadata to help teams make swift decisions.
Like we said: lineage is challenging. But when done right, it’s also incredibly powerful.
Bottom line: if data lineage isn’t useful, it doesn’t matter
Even though it seems like data lineage is everywhere right now, keep in mind that we’re also in the early days of automated lineage. Solutions will continue to be refined and improved, and as long as you’re armed with the knowledge of what high-quality lineage should look like, it will be exciting to see where the industry is headed.
Our hope? Lineage will become less about attractive graphs and more about powerful functionality, like the next Google Maps.
What do you think? Reach out to Barr Moses or Glen Willis on the Monte Carlo team. We’re all ears.
Data Lineage is Broken — Here Are 5 Ways to Fix It was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/kven9C1
via RiYo Analytics







No comments