https://ift.tt/3pzONb5 Shrinking the impact of extreme points with boosting Image by enviromantic on iStock All code lives here: Thym...
Shrinking the impact of extreme points with boosting

All code lives here: ThymeBoost Github
Introduction
A common task when dealing with time series data is to identify and handle outliers. It is important to be aware of these data points since they can have a large amount of influence on any analysis. There are many ways to identify and handle these data points, but today we will take a look at how you can manage them with ThymeBoost.
If this is the first time you are hearing about ThymeBoost, I encourage you to check out a previous article walking through the framework. At a bird’s eye view, ThymeBoost takes traditional time series decomposition and combines it with gradient boosting. It attempts to take as many positives from each methodology as possible, while leaving behind many of the negative aspects.
The package is under constant development so even if you have it installed there is a 100% chance that there is a new version on pip!
Before we get to the outlier handling, a quick disclaimer: ThymeBoost is still early on in development so use at your own risk! Additionally, outlier detection is not the main focus of ThymeBoost, it is just a nice feature. There exist many more-robust methods for outlier detection and handling.
With that, let’s get to the example…
A simple example
We will simulate a simple series composed of trend, seasonality, and little noise:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
#Here we will just create a random series with seasonality and a slight trend
seasonality = ((np.cos(np.arange(1, 101))*10 + 50))
np.random.seed(100)
true = np.linspace(-1, 1, 100)
noise = np.random.normal(0, 1, 100)
y = true + seasonality + noise
plt.plot(y)
plt.show()
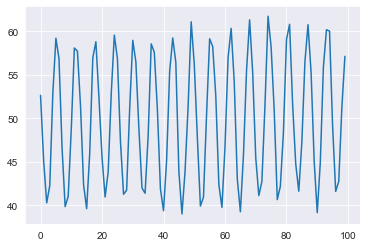
The added noise gives a few points a bit more of a spike, but overall nothing sticks out too much here. Let’s hand this data over to ThymeBoost to see what it thinks of the series.
from ThymeBoost import ThymeBoost as tb
boosted_model = tb.ThymeBoost()
output = boosted_model.detect_outliers(y,
trend_estimator='linear',
seasonal_estimator='fourier',
seasonal_period=25,
global_cost='maicc',
fit_type='global')
boosted_model.plot_results(output)
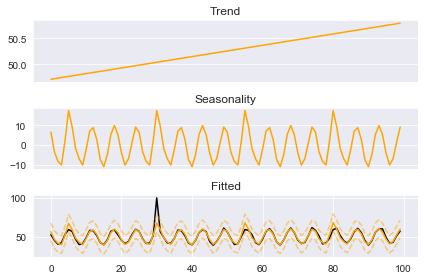
boosted_model.plot_components(output)
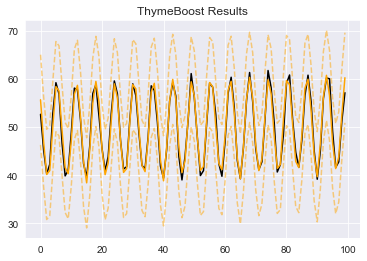
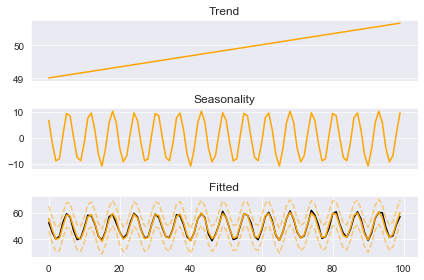
Here we use the ‘detect_outliers’ method rather than a standard fit. This method acts the same as the ‘fit’ method except it will test for points laying outside of the error bounds. These error bounds will only be consistent for simple linear trend estimators. If you were to pass a smoother like ‘ses’ (simple exponential smoothing) as the trend then these bounds will be quite wonky! Since we are using a simple linear trend we are safe to proceed and take a look at the ‘outliers’ column the method added to the output DataFrame:
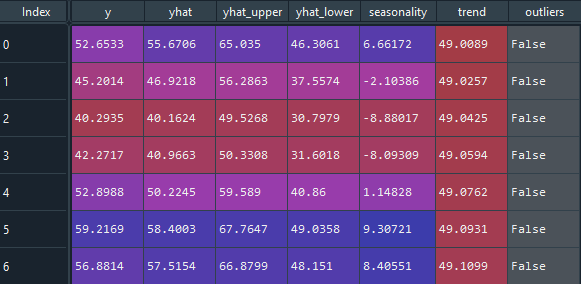
It seems ThymeBoost agrees with our earlier observation: the series is quite well behaved and contains no outliers. Let’s add one!
y[30] = 100
plt.plot(y)
plt.show()
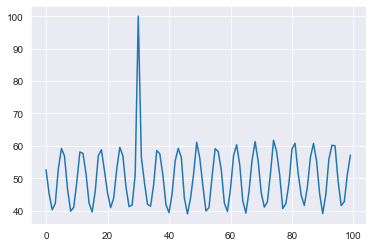
Now that we have a clear outlier let’s see what happens when we give it to ThymeBoost.
boosted_model = tb.ThymeBoost()
output = boosted_model.detect_outliers(y,
trend_estimator='linear',
seasonal_estimator='fourier',
seasonal_period=25,
global_cost='maicc',
fit_type='global')
boosted_model.plot_results(output)
boosted_model.plot_components(output)
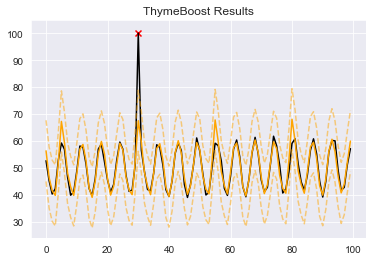
The first thing to notice is that the ‘plot_results’ plot now has a red ‘X’ where the outlier is. If your output contains the outliers column then that will be used in the plotting. The next major observation is that our seasonal component is significantly altered by the presence of this outlier. The question is:
What do we do now?
As mentioned previously, there are numerous ways to proceed. You may want to replace outliers with the mean of the series or the upper-bound of the fitted values or do nothing! Let’s see some natural ways ThymeBoost can handle it.
Handling Outliers Using the Outlier Column
We have a column of each observation tagged as either an outlier or not. Let’s use that to fix our seasonality:
weights = np.invert(output['outliers'].values) * 1
All we do here is take our series and convert it to an array, flip the boolean with ‘invert’ and multiply by 1 to convert from True/False to 0/1 ints. The outcome is an array where the outlier data point is 0 and all other points are 1. With that in hand, we can do a normal fit but pass this array as the ‘seasonality_weights’ argument which will gives the outlier 0 influence when calculating seasonality. Note: These weights must be passed as an array and used with ‘fourier’ seasonality.
output = boosted_model.fit(y,
trend_estimator='linear',
seasonal_estimator='fourier',
seasonal_period=25,
global_cost='maicc',
fit_type='global',
seasonality_weights=weights)
boosted_model.plot_results(output)
boosted_model.plot_components(output)
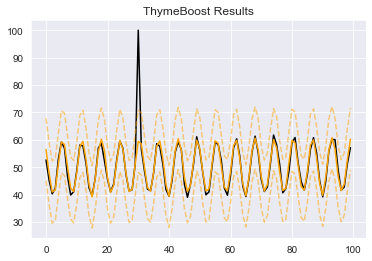
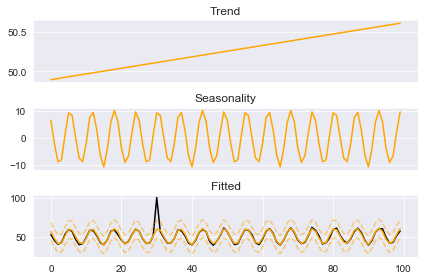
Notice the red ‘X’ is now gone because we just used the standard fit method but now our seasonal component appears fixed. The large spike in our fitted seasonality, which was an artifact of the outlier, has been erased. This is even clearer when we take a look at those seasonal components:
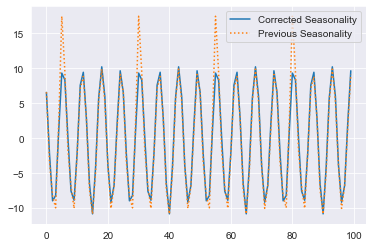
We passed the weights as 0/1 however we could use any weights we want. But, these weights are still arbitrary. What if we wanted weights that are dynamically assigned by how far away they are from ‘normal’?
Is that possible?
Yes, let’s take a look.
Handling Outliers Using the Regularize Argument
Instead of passing an array of weights we could alternatively pass a string: ‘regularize’. ThymeBoost will now use a weighting scheme which will penalize higher error data points when approximating seasonality. This weighting, combined with multiple rounds of boosting, provides a similar treatment as a Iteratively Reweighted Least Squares method.
output = boosted_model.fit(y,
trend_estimator='linear',
seasonal_estimator='fourier',
seasonal_period=25,
global_cost='maicc',
fit_type='global',
seasonality_weights='regularize')
boosted_model.plot_components(output)
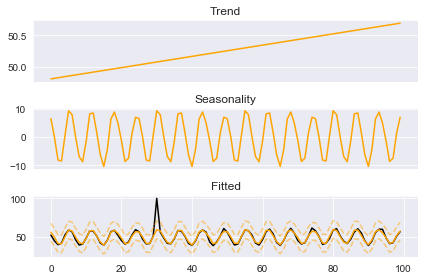
Once again, we see that the spikes have been cleansed from our approximated seasonal component. This method can penalize points too much. In fact, if we take a closer look at this seasonal component that is exactly what happens in this case.
Conclusion
ThymeBoost can detect and, quite naturally, handle outliers depending on their effect on our analysis. In this example, the only real effect of the outlier was the seasonal component being altered which can be fixed by dealing with the seasonal component directly. As mentioned previously, there are other far more robust methods for detecting and dealing with outliers. You may even want to do nothing to outliers! There really is no simple answer, but hopefully ThymeBoost can provide useful insights.
Another Disclaimer: this package is still in early development. The sheer number of possible configurations makes debugging an involved procedure, so use at your own risk. But please, play around and open any issues you encounter on GitHub!
Time Series Outlier Detection with ThymeBoost was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3Dwx8pI
via RiYo Analytics








No comments