https://ift.tt/3m0AYBV statsforecast makes forecasting with statistical models fast and easy By Nixtla Team . TL;DR In this post we int...
statsforecast makes forecasting with statistical models fast and easy
By Nixtla Team.
TL;DR
In this post we introduce statsforecast, an open-source framework that makes the implementation of statistical models in forecasting tasks fast and easy. statsforecast is able to handle thousands of time series and is efficient both time and memory wise. With this library you can easily create benchmarks on which to build more complex models; it can also allows you to run your own models in a parallel fashion. In this post we also offer a guide on how to use “Forecast Value Added” for benchmarking different models and assessing competing models.
Introduction
In this post, we will talk about using statistical models in forecasting tasks. In particular, we introduce statsforecast. This Python library allows fitting statistical models in a simple and computationally efficient way for hundreds of thousands of time series so that you can benchmark your own models quickly. Throughout this post, we will show how to use the library to calculate the Forecast Value Added of some models with respect to a benchmark model. This methodology allows us to select the best model among a variety.
Motivation
Deep learning and Machine Learning models have demonstrated state-of-the-art performance in time series forecasting tasks. However, it is helpful to have a battery of simpler models to benchmark and validate the value that those models add.
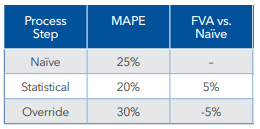
In business problems, metrics such as Forecast Value Added (FVA) are usually used to compare the value-added of more complex models against more straightforward techniques to implement and explain to decision-makers. FVA is calculated by subtracting the loss of a benchmark model from the loss of a more complex one. In the following example, three models were fitted: Naive, Statistical, and Override. The first column shows the Mean Average Percentage Error (MAPE) of these three models. The FVA vs. Naive column displays in the second row the difference between the Naive's MAPE and the Statistical's MAPE, which is positive; that means that the Statistical adds value to the process. Likewise, the third row shows the difference between the Naive's MAPE and the Override's MAPE; the result is negative, so the model Override doesn't add any value.
A wide range of statistical base models is included in statsforecast that can be used for decision making or as benchmarks for implementing more complete models. Also included are models for specific tasks, such as forecasting sparse (or intermittent) time-series, i.e., time series with a high percentage of zero values, such as sales. These models exist in implementations for the R programming language but not for Python.
statsforecast
To make benchmarking easier, we created statsforecast, which is a framework to help you forecast time series using statistical models. You just need to give it a model you want to use and let statsforecast do the rest.
Included models
- ADIDA: Temporal aggregation is used for reducing the presence of zero observations, thus mitigating the undesirable effect of the variance observed in the intervals. ADIDA uses equally sized time buckets to perform non-overlapping temporal aggregation and predict the demand over a pre-specified lead-time. The time bucket is set equal to the mean inter-demand interval. SES is used to obtain the forecasts.
- Croston Classic: The method proposed by Croston to forecast series that display intermittent demand. The method decomposes the original series into the non-zero demand size and the inter-demand intervals and models them using Simple Exponential Smoothing with a predefined parameter.
- Croston SBA: SBA stands for Syntetos-Boylan Approximation. A variant of Croston’s method that utilizes a debiasing factor.
- Croston Optimized: Like Croston, but this model optimizes the Simple Exponential Smoothing for both the non-zero demand size and the inter-demand intervals.
- Historic average: Simple average of the time series.
- iMAPA: iMAPA stands for Intermittent Multiple Aggregation Prediction Algorithm. Another way for implementing temporal aggregation in demand forecasting. However, in contrast to ADIDA that considers a single aggregation level, iMAPA considers multiple ones, aiming at capturing different dynamics of the data. Thus, iMAPA proceeds by averaging the derived point forecasts, generated using SES.
- Naive: Uses the last value of the time series as forecast. The simplest model for time series forecasting.
- Random Walk with Drift: Projects the historic trend from the last observed value.
- Seasonal Exponential Smoothing: Adjusts a Simple Exponential Smoothing model for each seasonal period.
- Seasonal Naive: Like Naive, but this time the forecasts of the model are equal to the last known observation of the same period in order for it to capture possible weekly seasonal variations.
- Seasonal Window Average: Uses the last window (defined by the user) to calculate an average for each seasonal period.
- SES: SES stands for Simple Exponential Smoothing. This model recursively weights the most recent observations in the time series. Useful for time series with no trend.
- TSB: TSB stands for Teunter-Syntetos-Babai. A modification to Croston’s method that replaces the inter-demand intervals component with the demand probability.
- Window Average: Uses the last window (defined by the user) to calculate an average.
Usage
To create an ample set of benchmarks you can install statsforecast which is available in PyPI (pip install statsforecast).
Libraries
Data
In this example, we use the M4 time series competition data. The objective of the competition was to validate models for different frequencies and seasonalities data. The dataset was originally released publicly and it was released with a completely open-access license. To download the data we used nixtlats. In this example, we use Daily time series.
Initially, the data don’t contain the actual dates of each observation, so the following line creates a datestamp for each time series.
The function M4.load returns train + test data, so we need to separate them.
This is the required input format.
- an index named unique_id that identifies each time series. In this example, we have 4,227 time series.
- a ds column with the dates.
- a y column with the values.
Training
We now define the statistical models we will use. We must define a list of functions. If the model has additional parameters, besides the forecast horizon, it must be included as a tuple with the model and the additional parameters.
Now we define our trainer, StatsForecast, where we define the models we want to use, the frequency of the data, and the number of cores used to parallelize the training job.
In this way adjusting these models and generating forecasts is as simple as the following lines. The main class is StatsForecast; it receives four parameters:
- df: A pandas dataframe with time series in long format.
- models: A list of models to fit each time series.
- freq: Frequency of the time series.
- n_jobs: Number of cores to be used in the fitting process. The default is 1 job. To compute the process in parallel you can use the cpu_count() function from multiprocessing.
Forecast Value Added
In this example, we’ll use the historic_average model as a benchmark; this is on of the simpler model among the fitted ones (it only takes the mean value of the time series as forecast).
As the table shows, the Forecast Value Added against the historic_average model is positive for the majority of the models.
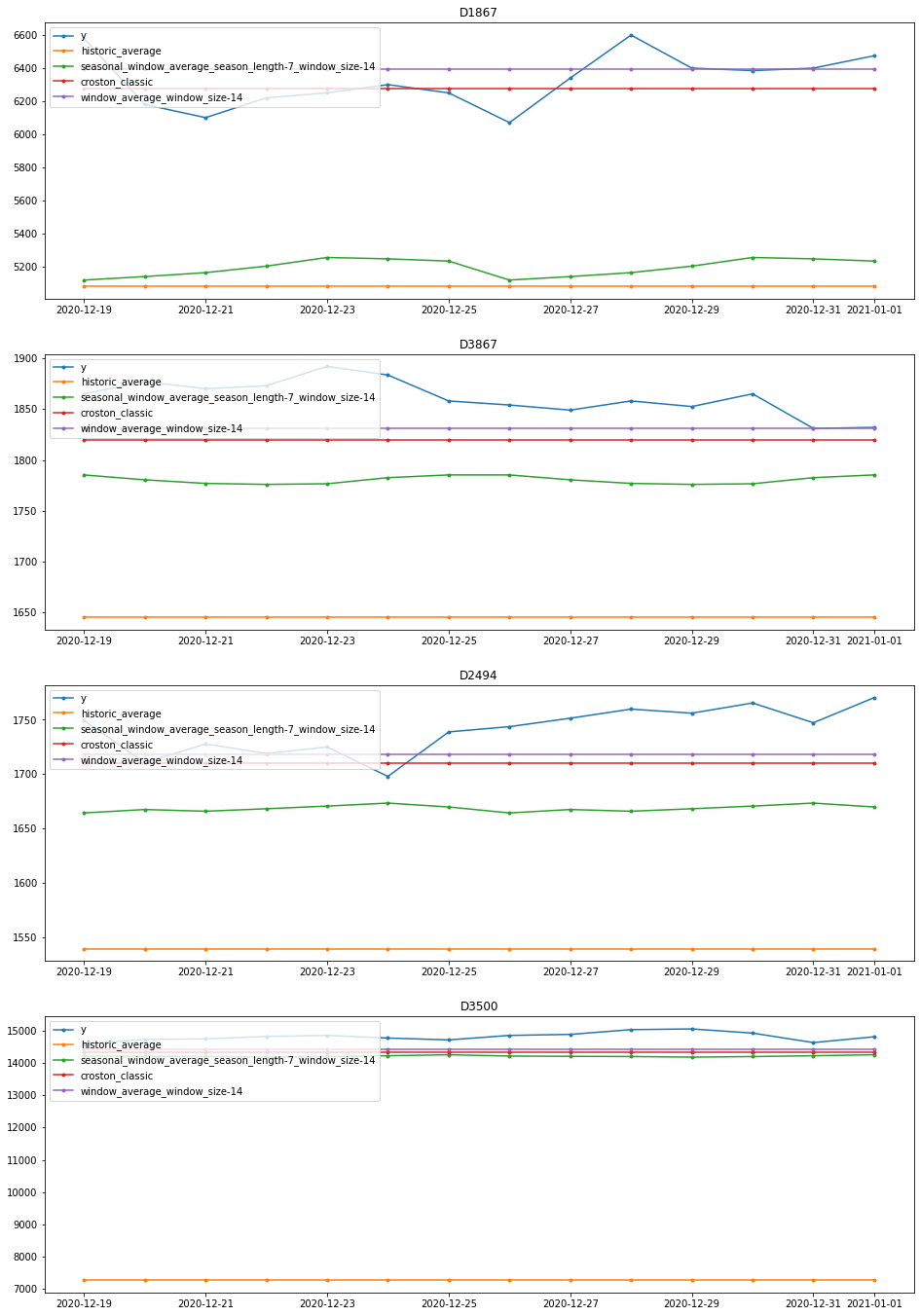
Visualization
In this section we present visual examples of the forecasts generated.
Create your own model
Additionally, you can use the full power ofStatsForecast to parallelize your own model. You just need to define a function with mandatory parameters y, the target time series, and h, the horizon to forecast; in addition, you can add more optional parameters. The function's output must be a numpy array of size h. In the following example, we'll fit a linear regression against time; this is a very basic model but it is useful to explain how to get the full potential of statsforecast.
A more complicated example with extra parameters would be a Lasso regression as follows,
Instead of passing the model, you just need to pass a tuple with the function and the parameter you want to use,
Finally, you can train both models and a historic_average model (for benchmarking purposes) at the same time defining the models list as follows,
Now we can calculate the FVA for the linear and lasso regression based on the historic average model.
So, the table shows a positive FVA for both models; we can also see that the regularization provided by the Ridge regression improves the FVA.
Conclusion
In this post, we introduce statsforecast, a library written in python to quickly fit statistical models. As we saw, in the practice of time series forecasting it is very useful to first fit a simple model, as a benchmark. This benchmark model allows to build more complex models and also to show that its complexity brings value to the process through the FVA.
Statsforecast allows you to create benchmark models in a simple way; moreover, it allows you to fit your own models efficiently by fitting in parallel.
WIP and Next Steps
statsforecast is a work in progress. In the next releases we plan to include:
- Automated backtesting.
- Ensembles (such as fforma).
- More statistical models with exogenous variables.
If you’re interested you can learn more in the following resources:
- GitHub repo: https://github.com/Nixtla/statsforecast
- Documentation: https://nixtla.github.io/statsforecast/
Time Series Forecasting with Statistical Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3350Wxo
via RiYo Analytics








No comments