https://ift.tt/3oBQR37 Part 2 — Log Replication Introduction Raft is a consensus algorithm built to orchestrate replicas in a distributed...
Part 2 — Log Replication
Introduction
Raft is a consensus algorithm built to orchestrate replicas in a distributed fashion. Designed with understandability in mind, Raft has only a few moving parts and is easy to implement. In the last article, I talked about the basics of Raft and explained the leader-election mechanism. In this post, we are going to focus on another important issue — log replication.
Fundamentals
Raft is essentially a bunch of replicated state machines. Whenever a request is received by the leader node, it is appended to the log for durability. The same log is replicated across multiple machines for redundancy.
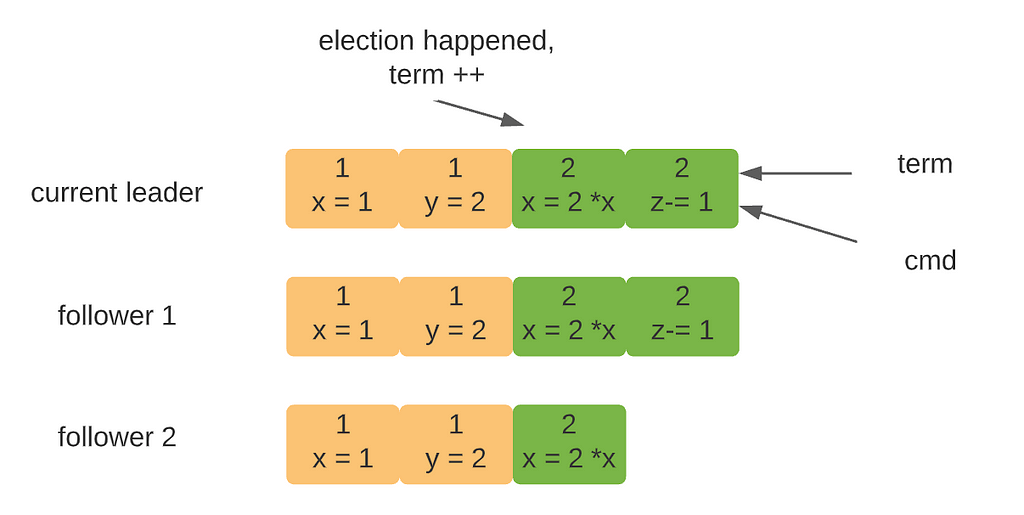
For instance, in figure 1, the current leader has four entries in its log. Follower 1 is fully in sync, but follower 2 is missing the latest entry. If you don’t understand what Term is in fig 0, check out my previous article.
RPC for log replication
Designed for understandability, Raft only uses two RPC calls for all communications:
AppendEntry: This RPC is initiated by the leader and carries the latest commands received. It also serves as the heartbeat message. When a follower gets this message, the election timer is reset. The AppendEntry message is a struct like this (I’m using Golang here)
It’s okay if you don’t understand the meaning of each field. We are going to examine them one by one.
RequestVote: This RPC is used for leader election, which is covered by the last post. I’m going to skip it since we care only about log replication.
Log Replication Details
Let’s start with a vanilla log replication algorithm. Whenever a request is received by the leader, it forwards the log entry to all followers and waits for the majority to acknowledge it.
Problem 1: Log ordering
The vanilla algorithm sends out messages to the followers as soon as they arrive. To do so, it only needs two fields in the message — leaderID and Entry. One major issue is that the log order cannot be preserved because of potential message delays. Consider the scenario in figure 1.
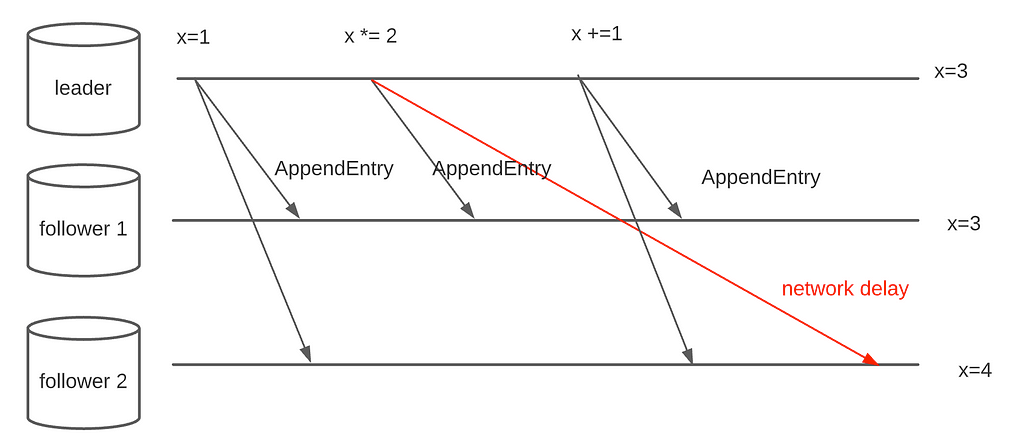
Raft uses two additional fields to ensure the integrity of the log — PrevLogIndex and PrevLogTerm. When a new entry is sent out, the leader also sends out the index and term number of the entry before. The receiver makes sure its latest entry has the identical index and term before appending the new request to its local log.
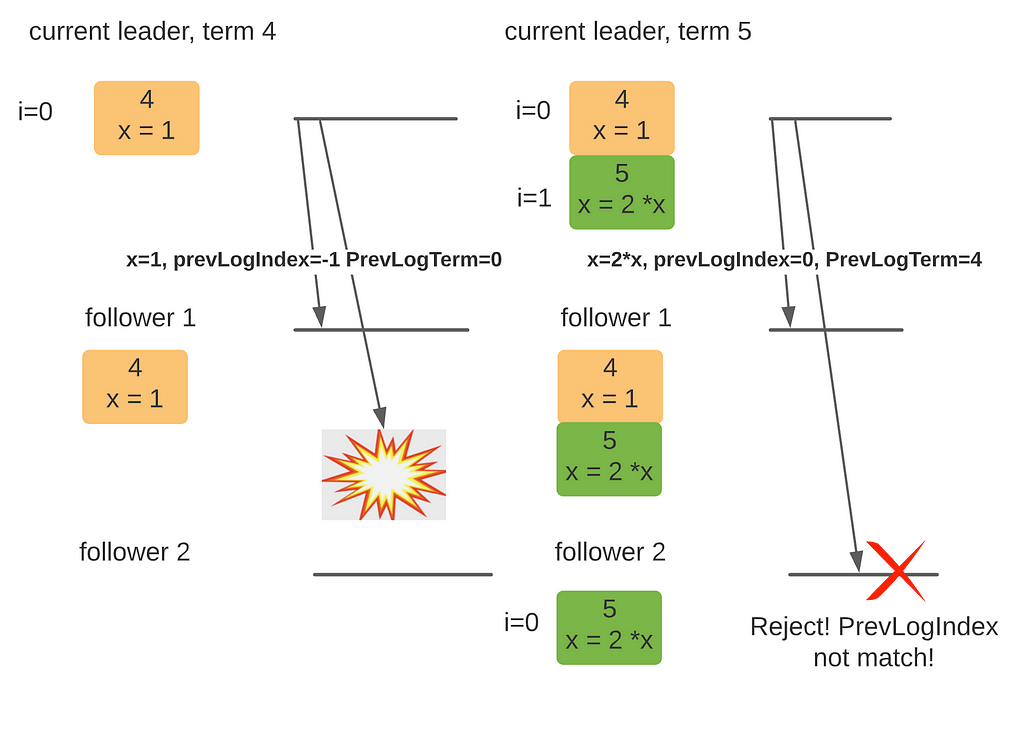
With these two additional parameters, we can achieve something awesome:
- Given an index of the log, if the entries from two logs (on two different machines) share the same term, they are identical
- If two entries in different logs have the same index and term, all preceding entries are identical
The first property is easy to prove. Assume the claim is wrong. If there exist two distinct entries with the same term, one of them must be received by the leader later than the other. Since the log is append-only, one of the entries will have a larger PrevLogIndex. However, if they show up in the same index in two different logs, they must have the same PrevLogIndex. (otherwise, the receiver rejects it) Contradiction!!
The second claim can be proved by induction:

Together, these two guarantees consist of the Log Matching Property of Raft.
Problem 2: Followers with conflicting entries
If the leader log is the only authority in the cluster, it will overwrite any conflict that a follower has. Is it possible to lose some log entries? Consider the following case:
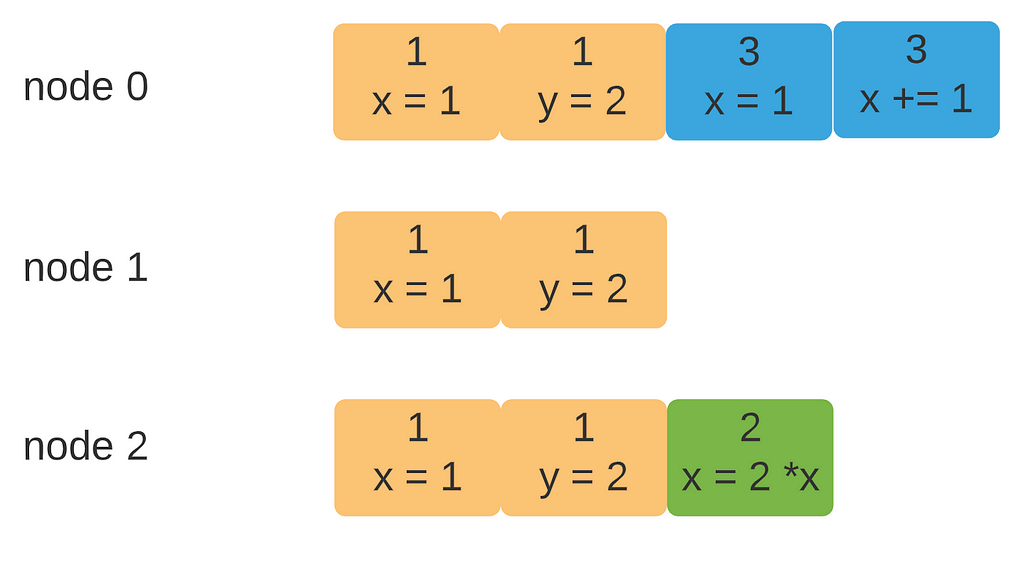
Before diving into the problem, I want to convince you that the above scenarios can indeed happen. Logs are in sync before index 2. From there onward, the following could happen to create these logs:
1) node 2 becomes the leader (votes from itself, 1 and 0) with term 2
2) node 2 receives a request from the client but failed to sync with other nodes
3) node 0 becomes the leader (vote from 1 and itself) with term 3
4) node 0 receives requests from the client. but failed to sync
Now, if node 0 regains contact with node 2, it will try to replicate its log, as depicted in figure 5
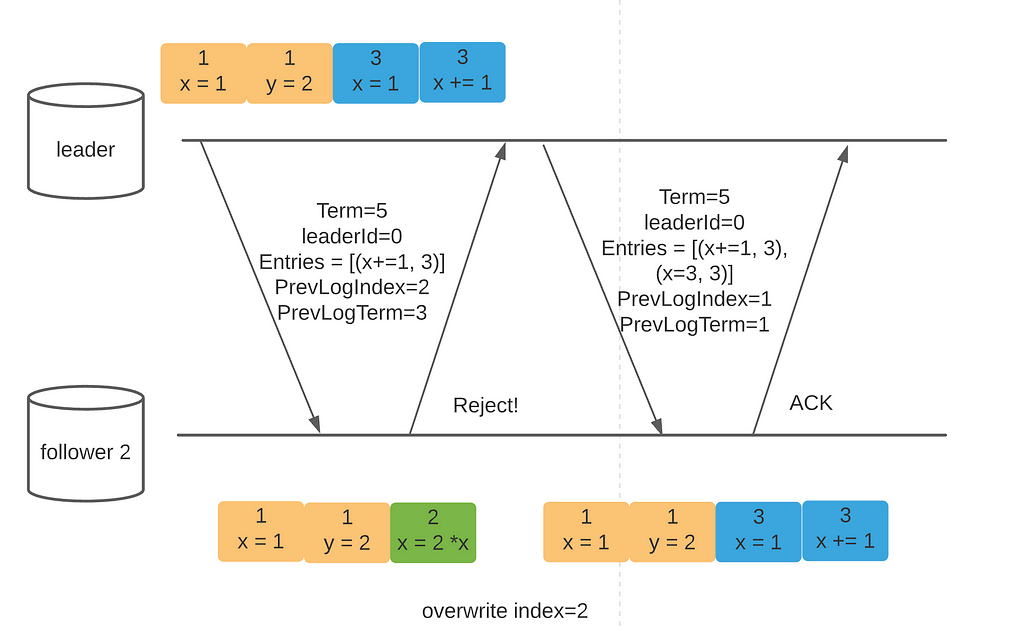
As you can see, the green entry indeed gets dropped. With the current design, this problem is unavoidable. However, a key observation here is that the green entry isn’t replicated on the majority (at least two nodes). If it is, it will never get dropped for the following reasons:
- if an entry is replicated on the majority, at least N/2 + 1 nodes have it
- for a node without the entry to win the election, it needs N/2 votes from other nodes (candidate always votes for itself)
- Since the candidate doesn’t have the entry, the N/2 + 1 nodes with the entry won’t vote for it (election restriction explained in part 1)
- It won’t get enough votes to win the election
This is the second key feature of Raft — Log Completeness Property. If an entry is replicated on the majority, it will always show up in the future leader logs, regardless of which node it might be. If not replicated on the majority, an entry could be dropped if leadership changes.
With the Log Completeness Property, it is important not to acknowledge client requests before the majority has it.
Problem 3: When to commit?
Finally, we arrive at the last issue — when to commit an entry? First of all, what is commit and why commit? Raft is a low-level consensus algorithm used by upper-level applications like key-value stores (e.g. something like ZooKeeper). When an entry is safely replicated by Raft, we want to make sure the client can see it via the application. Hence, Raft needs to decide when to tell the upper-level application an entry is ready for use (a partially replicated entry, as the last entry in the leader’s log should not be visible!).
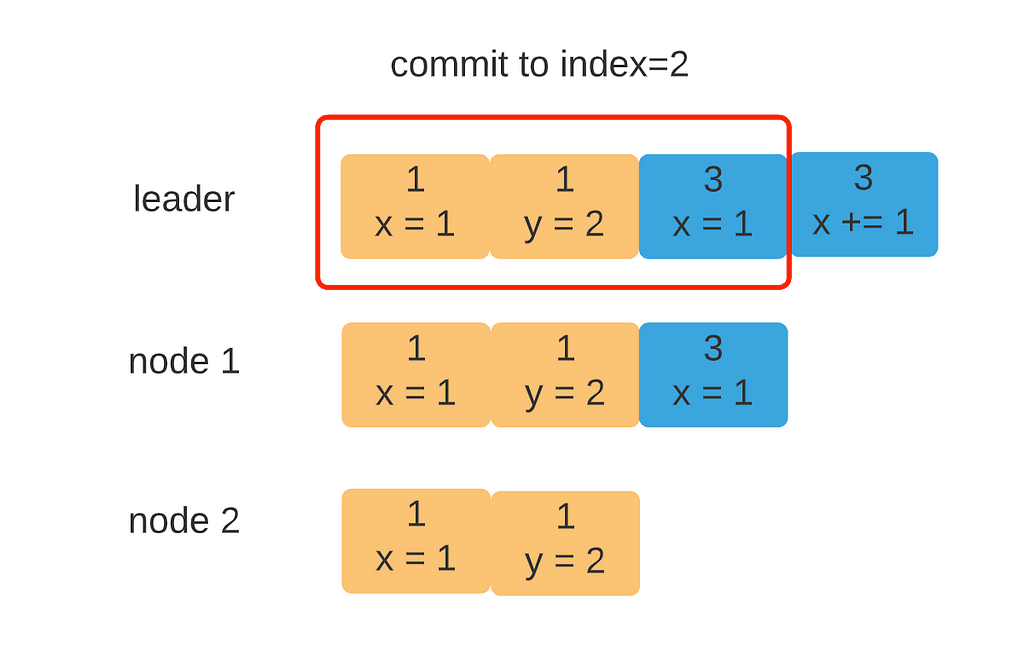
So far our vanilla algorithm does not carry any information regarding the commit index. Because the data flow is a one-way street, flowing from the leader to the followers, the nodes won’t know if an entry is replicated on the majority.
To address this issue, we can add yet another field to the AppendEntry message called LeaderCommit. The leader increases the commit index if an entry is received by the majority. Below is the actual code that keeps track of the commit index used by the leader node.
Summary
In this article, we started with a vanilla log replication algorithm(broadcasting entries without any additional bookkeeping) and evolved it to the full-fledged version by considering various corner cases. The most important RPC in log replication is the AppendEntry RPC, which uses a struct with four fields:
- Term: very important for log replication and leader election
- LeaderId: show the identity of the candidate.
- Entries: a list of entries that the leader wishes to replicate.
- PrevLogIndex: the index of the log entry right before Entries[0]. Used to ensure Log Completeness and Log Match Properties
- PrevLogTerm: the term of the log entry right before Entries[0]. Used to ensure Log Completeness and Log Match Properties
- LeaderCommit: important for upper-level applications. Only committed entries can be applied to the application and visible to the clients.
Raft Algorithm Explained 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3lNrGsx
via RiYo Analytics

No comments