https://ift.tt/3nSW8TT Data Domains and Data Products Practical guidance from the field All clients I work with are either interested in ...
Data Domains and Data Products
Practical guidance from the field
All clients I work with are either interested in or planning their next generation of a modern data platform. In this transition, data mesh architecture is gaining a lot of traction. At the same time there are concerns about interpreting this concept: practical guidance is missing.
About data mesh
Data mesh advocates treating data as a product, pushing ownership deeper into to the producing teams. The theory behind this is that ownership is better aligned with data creation, which brings more visibility and quality to the data. This “shift left” of responsibilities addresses the data explosion, which has overwhelmed central data teams tasked to cleanse, harmonize, and integrate data for the larger good. The delegation of responsibilities for specific data sets to domains means that enterprises are split into mini enterprises, each taking the responsibly for building abstractions, serving data, maintaining associated metadata, improving data quality, applying life cycle management, performing code control and so on. Especially traditional large-scale enterprises struggle with this modern approach because data is often shared between domains, or one domain might be dependent on another domain for its data. This makes implementation difficult, so let me project my view and share some practical guidance.
Guidance
Standardization and clear principles are key to make your implementation a success. Data products, for example, shouldn’t become subject of experimentation. Nor should they trigger a proliferation of standards, file types, protocol formats, and so on. Therefore, I recommend any organization to adopt the following eighteen principles:
1. Clearly define your domain boundaries
Everybody uses their own definition of domain, sub-domain, or bounded context. This fuzziness is a problem. Without clear guidance domains become too inter-connected, ownership becomes subject of interpretation and complexity will be pushed into domains by other domains.
My recommendation for domain management is to make clear and strict boundaries. Each domain boundary must be distinct and explicit. Business concerns, processes, the solution area, and data that belong together must stay together and be maintained and managed within the domain. Ideally, each domain belongs to one Agile or DevOps team, because when there is one team, the number of coupling points are manageable and easily understood by all team members. Within a domain, tight coupling is allowed; however, when crossing the boundaries, all interfaces to other domains must be decoupled using interoperability standards. This is where data products come into the picture.
Having said that, for data management I encourage you to make your domains concrete. You could, for example, use a repository that list out all data domains, including naming and applicability of each domain. You could use this same repository to describe team organization, usage and sharing, and physical manifestation: list of applications and databases.
2. Be concrete on your data products and interoperability standards
The next recommendation is to define what data products are. This starts by clearly defining your different type of data products, e.g., batch-, API-, and event-oriented. Be in all times specific on what a data product looks like. For example, batch data products are defined as parquet files and always must include a YML file for metadata, which includes these X attributes. I don’t believe in, for example, reports and dashboards being data products, since they address specific customer needs and therefore are tightly coupled to the underlying use case.
3. No raw data!
Data product is the opposite of raw data, because exposing raw data requires rework by all consuming-domains. So, in every case you should encapsulate legacy- or complex systems and hide away technical application data. This principle you can also apply for external data providers. Ask your partners to conform to your standard or apply mediation via an additional domain: a consuming team acts as a provider by abstracting complexity and guaranteeing stable and safe consumption.
4. Define patterns for overlapping domains
Like I said, things get complicated for data that is shared across domains. For the granularity and logically segmenting your data domains you can leverage the guidance from Domain Data Stores:
Decomposing domains is especially important when domains are larger, or when domains require generic — repeatable — integration logic. In such situations it could help to have a generic domain that provides integration logic in a way that allows other subdomains to standardize and benefit from it. A ground rule is to keep the shared model between subdomains small and always aligned with the ubiquitous language.
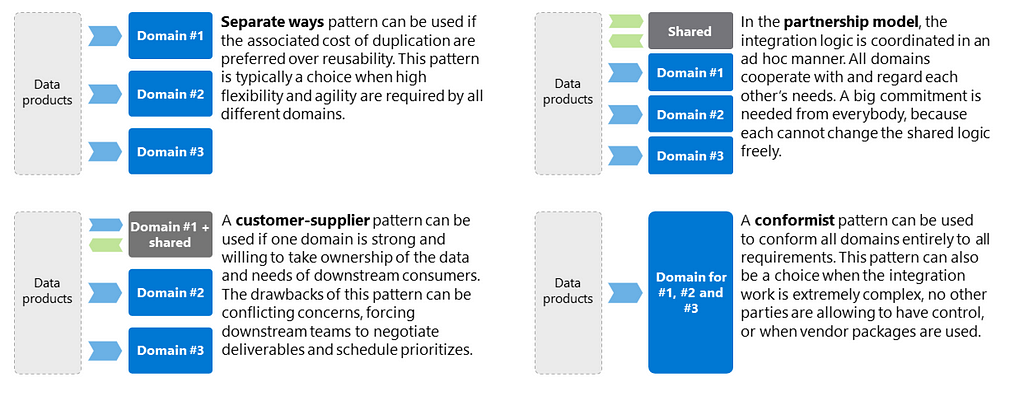
For overlapping data requirements, you can use different patterns from domain-driven design. Here is a short summary of the patterns:
- Separate ways, as a design pattern, can be used if the associated cost of duplication is preferred over reusability. This pattern is typically a choice when reusability is sacrificed for higher flexibility and agility.
- A customer-supplier pattern can be used if one domain is strong and willing to take ownership of the data and needs of downstream consumers. The drawbacks of this pattern can be conflicting concerns, forcing downstream teams to negotiate deliverables and schedule priorities.
- In the partnership model, the integration logic is coordinated in an ad hoc manner within a newly created domain. All teams cooperate with and regard each other’s needs. A big commitment is needed from everybody because each cannot change the shared logic freely.
- A conformist pattern can be used to conform all domains to all requirements. This pattern can be a choice 1) when the integration work is extremely complex 2) no other parties are allowed to have control 3) or when vendor packages are used.
In all cases your domains must adhere to your interoperability standards. Thus, a partnership domain that produces new data for other domains must expose their data products like any other domain.
5. A data product contains data, which is made available for broad consumption.
It is high likely that the same data will be used repeatedly by different domain teams. This also means your teams shouldn’t conform their data products to specific needs of data consumers. On the other hand, data products evolve based on user feedback and generate relevant work for them, so it can be tempting for teams to incorporate consuming specific requirements. You should be very careful here! If consumers push consumer-specific business logic into all data products, it forces changes to be simultaneously carried out over all data products. This could trigger intense sprint goal cross coordination and backlog negotiation between all team members. My recommendation would be to introduce some dispute management: a governance body that oversees that data products aren’t created consumer specific. This body can step in to guide domain teams, organize walk-in and knowledge sharing sessions, provide practical feedback and resolve issues between teams.
6. Create specific guidance on missing values, defaults, and data types
I’ve experienced hot debates on how missing and defaulted data must be interpreted. For example, data is truly missing and cannot be derived, but the operational still expects a mandatory data value to be provided by an employee. If no guidance is provided, a sprawl of descriptions and guidance will be created. Some might consistently provide incorrect values, others might provide random values, while others might provide no guidance at all. The same applies for detailed local reference values and data types. Therefore, you may want to introduce guidance on data that must be defaulted and formatted consistently throughout the entire dataset. This also implies the same decimal precision, notations, and grammar, addressing that data consumers don’t have to apply (complex) application logic to get correct data. You could set these principles system- or domain-oriented, but I also see large enterprise providing generic guidance on what data formats and types must be used within all data products.
7. Data products are semantically consistent across all delivery methods: batch, event-driven, and API-based
To me this sounds obvious, but I still see companies today making separate guidance for batch-, event- and API-oriented data. Since the origin of data is the same for all distribution patterns, I encourage you to make all guidance consistent for all patterns. You can ask all your domains to use a single data catalogue for describing all terms and definitions. This single source becomes the baseline for linkage (mapping) to all different data products.
8. Data products inherit the ubiquitous language
It is essential to understand the context of how the data has been created. This is where the ubiquitous language is used for: a constructed, formalized language, agreed upon by stakeholders and designers, to serve the needs of our design. The ubiquitous language should be aligned with the domain: business functions and goals. I see some companies requiring domains to use human-friendly column names in the language of the domain. To me this isn’t essential, as long the mapping from the physical data model to the business data model is provided.
9. Data product attributes are atomic
Data product attributes are atomic, must represent the lowest level of granularity and have precise meaning or precise semantics. These data attributes in an ideal state are linked one-to-one to the items within your data catalogue. The benefit here is that data consumers aren’t forced to split or concatenate data.
10. Data products remain compatible from the moment created
Data products remain stable and are decoupled from the operational/transactional application. This implies schema drift detection, so no disruptive changes. It also implies versioning and, in some cases, independent pipelines to run in parallel, giving your data consumers time to migrate from one version to another.
11. Abstract volatile reference data to less granular value ranges
You might want to provide guidance on how complex reference values are mapped to more abstract data product-friendly reference values. This guidance also requires a nuance for agility mismatches: 1) if the pace of change is high on the consuming side, your guiding principle must be that complex mapping tables are maintained on the consuming side. 2) if the pace of change is on the providing side, the guiding principle is that data product owners are asked to abstract or roll up detailed local reference values to more generic consumer agnostic reference values. This also implies that the consumer might perform additional work, e.g., mapping the more generic reference values to a consuming-specific reference values.
12. Optimized (transformed) for readability: complex application models are abstracted away.
Analytical models that are constantly retrained, constantly read large volumes of data. This read aspect impacts applications and database designs because we need to optimize for data readability. Again, you can introduce principles for optimization and readability of data. For example, asking domains to define sub-products: data which is logically organized around subject areas. Resource-oriented architecture (ROA) can be a great inspiration. Guidance will also include that too heavily normalized or too technical physical models must be translated into a more reusable and logically ordered datasets. Complex application logic must be abstracted, and data must be sourced with an adequate level of granularity to serve as many consumers as possible. This could also mean that cross-references and foreign-key relationships must be integer and consistent throughout the entire dataset and with all other datasets from the same data product provider. Consuming domains shouldn’t have to manipulate keys for joining different datasets!
13. Data products are directly captured from the source
Domains shouldn’t be allowed to encapsulate data from other domains with different data owners, because that would obfuscate data ownership. Therefore, data products must be directly created from the domain (source) of origin.
14. Newly created data means new data products
Any data, that is created because of a business transformation (semantical change using business logic) and distributed, is considered as new and leads new data and data ownership. Therefore, you want to enforce the same data distribution principles. This means newly created data that is subject of sharing must follow the same principles as outlined in this blogpost.
Another concern is traceability: knowing what happens with the data. To mitigate the risks of transparency, ask data consumers to catalog their acquisitions and the sequences of actions and transformations they apply to the data. This lineage metadata should be published centrally.
15. Encapsulate metadata for security
For data security, which includes fine-grained consumption, you need to define a data filtering approach: reserved column names, encapsulated metadata, product metadata, etc. For example, I see companies using reserved column names in their data products. If such a reserved column name is present in any of these datasets, it can be used for fine-grained filtering. Consequently, access can be permitted on only non-sensitive data or data can be filtered. A virtual view, for example, can be created for a consumer. Same holds for classifications or tags.
16. You may want to introduce some enterprise consistency
Some will argue this guidance doesn’t contribute to a true data mesh implementation, but I see companies which value some enterprise consistency. I do want to stress out that you shouldn’t build an enterprise canonical data model, like seen in most enterprise data warehouse architectures. Introducing some enterprise consistency might help in a large-scale organization in which many domains rely on the same reference values. Therefore, you can consider introducing guidance for including enterprise reference values. For example, currency codes, country codes, product codes, client segmentation codes, and so on. If applicable, you can ask your data product owners to map their local reference values to values from the enterprise lists.
The same guidance you might give for master identification numbers, which link mastered data and data from the local systems together. These data elements are critical for tracking down what data has been mastered and what belongs together, so you might ask your local domains to include these master identifiers within their data products.
Lastly, only if enterprise data is very stable and it truly matters, consider using this guidance. The list of enterprise data elements is limited. It’s a dozen, not hundreds.
17. Addressing time-variant and non-volatile concerns
I see companies addressing the time variant and nonvolatile concerns by prescribing how data products must be delivered and are consumed downstream. For example, products after they arrive are versioned, compared, forked into read-optimized file formats, and transformed into slowly changing dimensions preserving all historical data from previous data products. In all cases data remains domain-oriented, so no cross-cutting integration is allowed to be applied before any consumption takes place.
18. Use data product blueprints
What is the strategy for creating data products? Should it be facilitated with a platform, or must domains cater for their own needs? My view is that the creation is an interactive process, which can be best facilitated. If you work distributed and strive for domain autonomy you can strike a balance by designing and providing blueprints with the most essential services required for integrating and serving data out to different domains, while giving autonomy for data product optimization. Your blueprint can be instantiated for every domain or a set of domains sharing some cohesion. The model below is a reference model for allowing scalable data product creation.
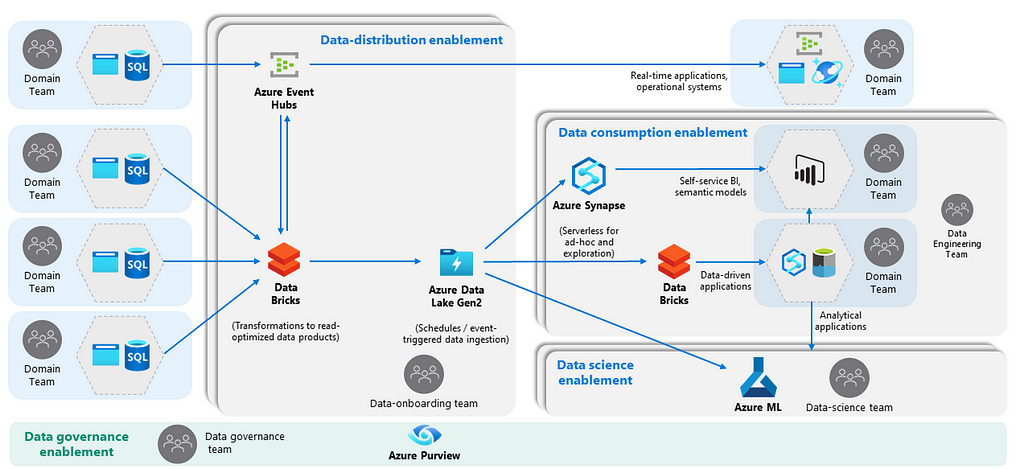
If done correctly these blueprints can be designed in such a way that lineage is automatically pushed down into the catalogue. For the level of granularity of combining services, different mesh topologies can be used. Some companies value efficient compute resource usage or see data gravity issues for large data consumers and prefer a single platform while still isolating domains via different containers. Other companies use the harmonized mesh approach and allow domains within an organization to operate their own platform whilst adhering to common policies and standards, like in the model see above. Some embrace capability duplication for ensuring complete segregation. This is likely to increase costs, but also a matter of taste.
Difficulties
Building data products by domains is a promising concept that gains a lot of attention these days. It tries to address some scalability problems, but enterprises need to be aware of the pitfalls. Building proper data abstractions is not for the faint-hearted. It is technically difficult and should be facilitated very well. The following check list ensures better data ownership, data usability and data platform usage:
- Define data interoperability standards, such as protocols, file formats and data types.
- Define required metadata: schema, classifications, business terms, attribute relationships, etc.
- Define data filtering approach: reserved column names, encapsulated metadata, etc.
- Determine level of granularity of partitioning for domains, applications, components, etc.
- Setup conditions for onboarding new data: data quality criteria, structure of data, external data, etc.
- Define data product guidance for grouping of data, reference data, data types, etc.
- Define requirements contract or data sharing repository.
- Define governance roles, such as data owner, application owner, data steward, data user, platform owner, etc.
- Establish capabilities for lineage ingestion + define procedure for lineage delivery + unique hash key for data lineage.
- Define lineage level of granularity to be either application-, table-, column-level for each domain.
- Determine classifications, tags, scanning rules
- Define conditions for data consumption, for example via secure views, secure layer, ETL, etc.
- How to organize data lake using containers, folders, sub-folders, etc.
- Define data profiling and life cycle management criteria, e.g., move after 7 years, etc.
- Define enterprise reference data for key identifiers, enrichment process, etc.
- Define approach for log and historical data processing for transactional data, master data and reference data
- Define a process for redeliveries and reconciliation: data versioning
- Align with Enterprise Architecture on technology choices: what services are allowed by what domains; what services are reserved for platform teams only.
Finally, a distributed architecture also distributes the management and ownership throughout your organization. Your teams become end-to-end responsible. Make conscious choices and be very detailed about what to expect. Be precise on what activities remains central and what is expected from your teams.
If this is content you like, I engage you to have a look at the book Data Management at Scale.
Data domains and data products was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3CFiNqM
via RiYo Analytics








No comments