https://ift.tt/VOlDNI0 Preparing for SQL interview questions? You're smart to practice. SQL shows up in many data job interview, and fo...
Preparing for SQL interview questions? You're smart to practice. SQL shows up in many data job interview, and for good reason — one analysis of 200 data analyst job postings found that SQL was explicitly required in 90% of them.
This guide is built specifically for data roles. We've compiled 60 SQL interview questions and answers that reflect what actually gets asked in technical interviews for data analysts, data scientists, and data engineers. Every answer is short and direct — no filler paragraphs, just the information you need. You'll find code examples, diagrams for visual concepts, and questions organized across three levels: beginner, intermediate, and advanced, plus a dedicated section for data engineering interviews.
If you want structured practice before your interview, Dataquest's SQL Skill Path covers everything from first queries to window functions through hands-on coding — not video lectures.
Table of Contents
- Beginner SQL Interview Questions (1–15)
- Intermediate SQL Interview Questions (16–30)
- Advanced SQL Interview Questions (31–45)
- SQL Interview Questions for Data Engineers (46–55)
- Bonus Quick-Fire Questions (56–60)
- Resources for SQL Interview Prep
- FAQ
Beginner SQL Interview Questions
These cover the fundamentals that every SQL interview touches on. If you're new to SQL, start here, and practice writing these queries by hand, not just reading them. Dataquest's Introduction to SQL and Databases course lets you practice all of these concepts interactively.
1. What are the main types of SQL commands?
SQL commands fall into four categories:
- DDL (Data Definition Language): CREATE, ALTER, DROP, TRUNCATE — define database structure
- DML (Data Manipulation Language): SELECT, INSERT, UPDATE, DELETE — work with data
- DCL (Data Control Language): GRANT, REVOKE — manage permissions
- TCL (Transaction Control Language): COMMIT, ROLLBACK, SAVEPOINT — control transactions
2. What's the difference between a PRIMARY KEY and a UNIQUE constraint?
Both enforce uniqueness, but a PRIMARY KEY also requires NOT NULL and you can only have one per table. A table can have multiple UNIQUE constraints, and UNIQUE columns can contain NULL values (in most databases, at least one).
3. What is a foreign key?
A foreign key is a column in one table that references the primary key of another table. It enforces referential integrity, you can't insert a value into the foreign key column unless that value exists in the referenced table.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id)
);4. Write a query to find all employees hired after 2023, sorted by salary descending.
SELECT employee_id, name, salary, hire_date
FROM employees
WHERE hire_date > '2023-12-31'
ORDER BY salary DESC;5. What's the difference between WHERE and HAVING?
WHERE filters individual rows before grouping. HAVING filters groups after GROUP BY and works with aggregate functions.
SELECT department, COUNT(*) AS headcount
FROM employees
WHERE hire_date > '2024-01-01'
GROUP BY department
HAVING COUNT(*) > 5;6. Explain the difference between INNER JOIN and LEFT JOIN.

INNER JOIN returns only rows with matches in both tables. LEFT JOIN returns all rows from the left table, plus matches from the right, with NULLs where there's no match.
-- Returns only customers who have orders
SELECT c.name, o.order_id
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id;
-- Returns ALL customers, even those with no orders
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;For hands-on practice with all join types, work through Dataquest's Combining Tables in SQL course.
7. Write a query using GROUP BY and an aggregate function.
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;8. What does NULL = NULL return?
It returns NULL (which evaluates as false in a WHERE clause), not true. NULL represents an unknown value, and two unknowns aren't considered equal. Use IS NULL or IS NOT NULL to test for NULLs.
9. What's the difference between DELETE, TRUNCATE, and DROP?
In many database, DELETE removes specific rows (can use WHERE), logs each row, and can be rolled back. TRUNCATE removes all rows at once without row-level logging — faster, but no WHERE clause. DROP removes the entire table and its structure from the database.
10. What's the difference between UNION and UNION ALL?
UNION combines result sets and removes duplicates. UNION ALL combines result sets and keeps duplicates. UNION ALL is faster because it skips the deduplication step.
SELECT name FROM customers
UNION ALL
SELECT name FROM suppliers;11. Name the common SQL constraints and what they do.
NOT NULL prevents empty values. UNIQUE ensures all values in a column are distinct. PRIMARY KEY combines NOT NULL + UNIQUE (one per table). FOREIGN KEY links to another table's primary key. CHECK validates values against a condition. DEFAULT assigns a value when none is provided.
12. What is an index and why would you use one?
An index is a data structure that speeds up row lookups, like a book's index. It makes reads faster but slows down writes (INSERT, UPDATE, DELETE) because the index must be maintained. Use indexes on columns you frequently filter, join, or sort on.
13. Write a query to find beverages with fruit_pct between 35 and 40.
SELECT *
FROM beverages
WHERE fruit_pct BETWEEN 35 AND 40;14. Write a query to find beverages where the contributor has only one name (no space).
SELECT *
FROM beverages
WHERE contributed_by NOT LIKE '% %';15. In what order does SQL actually execute a query's clauses?
Not the order you write them. The execution order is:
- FROM (and JOINs)
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
This is why you can't use a column alias from SELECT in your WHERE clause — WHERE runs first.
Intermediate SQL Interview Questions
These questions go deeper into joins, subqueries, and database design. If you're comfortable with the basics, this is where most data analyst interviews spend their time. Dataquest's SQL Subqueries course is a good companion for this section.
16. Given these tables, write a query to find alumni who scored above 16 on their calculus exam.
alumni: student_id, name, surname, birth_date, faculty
evaluation: student_id, class_id, exam_date, grade
curricula: class_id, class_name, professor_id, semester
SELECT a.name, a.surname, a.birth_date, a.faculty
FROM alumni a
INNER JOIN evaluation e ON a.student_id = e.student_id
INNER JOIN curricula c ON e.class_id = c.class_id
WHERE c.class_name = 'calculus' AND e.grade > 16;17. When would you use a subquery instead of a JOIN?
Use a subquery when you need a single value for comparison (like a threshold), when the logic is cleaner as a nested question, or when you're filtering based on an aggregate. Use a JOIN when you need columns from both tables in the output.
18. What's the difference between a correlated and non-correlated subquery?
A non-correlated subquery runs once independently. A correlated subquery references the outer query and re-runs for each outer row — it's slower but necessary when the inner query depends on the current row.
-- Correlated: employees earning above their department's average
SELECT name, salary, department_id
FROM employees e
WHERE salary > (
SELECT AVG(salary) FROM employees
WHERE department_id = e.department_id
);19. What is a CTE and when would you use one?
A Common Table Expression is a named temporary result set defined with WITH. It exists only for the duration of the query. Use CTEs to break complex logic into readable steps, avoid repeating the same subquery, or write recursive queries.
WITH high_earners AS (
SELECT department_id, AVG(salary) AS avg_sal
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 80000
)
SELECT d.name, h.avg_sal
FROM high_earners h
JOIN departments d ON h.department_id = d.id;20. Write a query using CASE for conditional logic.
SELECT name, salary,
CASE
WHEN salary > 120000 THEN 'Senior'
WHEN salary > 70000 THEN 'Mid'
ELSE 'Junior'
END AS level
FROM employees;21. What is normalization? Explain 1NF through 3NF briefly.
Normalization reduces data redundancy by organizing tables around dependencies. For a deeper walkthrough with examples, see our guide to SQL normalization.
1NF: Every column holds atomic (single) values. No repeating groups.
2NF: Meets 1NF, plus every non-key column depends on the entire primary key (no partial dependencies).
3NF: Meets 2NF, plus no non-key column depends on another non-key column (no transitive dependencies).
22. Write a query to find the average fruit_pct by contributor, sorted ascending.
SELECT contributed_by, AVG(fruit_pct) AS avg_fruit
FROM beverages
GROUP BY contributed_by
ORDER BY avg_fruit;23. What is a stored procedure?
A stored procedure is a precompiled set of SQL statements saved in the database. It can accept parameters, contain logic, and return results. Use stored procedures to centralize business logic, reduce network traffic, and improve performance through plan caching.
24. What's the difference between EXISTS and IN?
Both check for matching rows, but EXISTS stops at the first match and handles NULLs safely. IN compares against a list and can return unexpected results if the subquery contains NULLs. For large subqueries, EXISTS is generally faster.
25. When would you use a self-join?
When a table has a hierarchical or comparative relationship with itself. Classic example: finding each employee's manager, where both are rows in the same table.
SELECT e.name AS employee, m.name AS manager
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;26. What are the ACID properties?
Atomicity: A transaction fully completes or fully rolls back — no partial state.
Consistency: A transaction takes the database from one valid state to another.
Isolation: Concurrent transactions don't interfere with each other.
Durability: Once committed, changes survive system failures.
27. What's the difference between a clustered and non-clustered index?
In systems like SQL Server, a clustered index physically sorts and stores table rows in the order of the index key — a table can only have one. A non-clustered index is a separate structure with pointers back to the data rows — a table can have many.
This distinction doesn't apply to every database. PostgreSQL, for example, doesn't have clustered indexes in the SQL Server sense — all indexes are secondary structures that point to heap-stored rows. PostgreSQL does have a CLUSTER command that physically reorders a table once, but it's not maintained automatically on future inserts.
The concept still matters in interviews because the underlying question is the same: how does the database find your data, and when does physical row order help performance?
28. How would you find duplicate rows in a table?
SELECT email, COUNT(*) AS cnt
FROM users
GROUP BY email
HAVING COUNT(*) > 1;29. Write a query to find the 3rd highest salary.
SELECT DISTINCT salary
FROM employees
ORDER BY salary DESC
LIMIT 1 OFFSET 2;Or with a subquery approach:
SELECT MAX(salary) FROM employees
WHERE salary < (
SELECT MAX(salary) FROM employees
WHERE salary < (SELECT MAX(salary) FROM employees)
);30. What's the difference between a view and a materialized view?
A view is a stored query that runs fresh every time you reference it — no data stored. A materialized view stores the query results physically and must be refreshed to pick up changes. Use materialized views when the underlying query is expensive and the data doesn't change frequently.
Dataquest's Customers and Products Analysis project lets you practice multi-table joins and subqueries on a realistic business dataset.
Advanced SQL Interview Questions
These questions are common in data engineer interviews and senior analyst roles. They test your ability to write performant queries and reason about systems. If window functions are new to you, Dataquest's Window Functions in SQL course covers all of this with hands-on practice.
31. Explain ROW_NUMBER, RANK, and DENSE_RANK.
All three are window functions that assign a number to each row within a partition. They differ in how they handle ties:
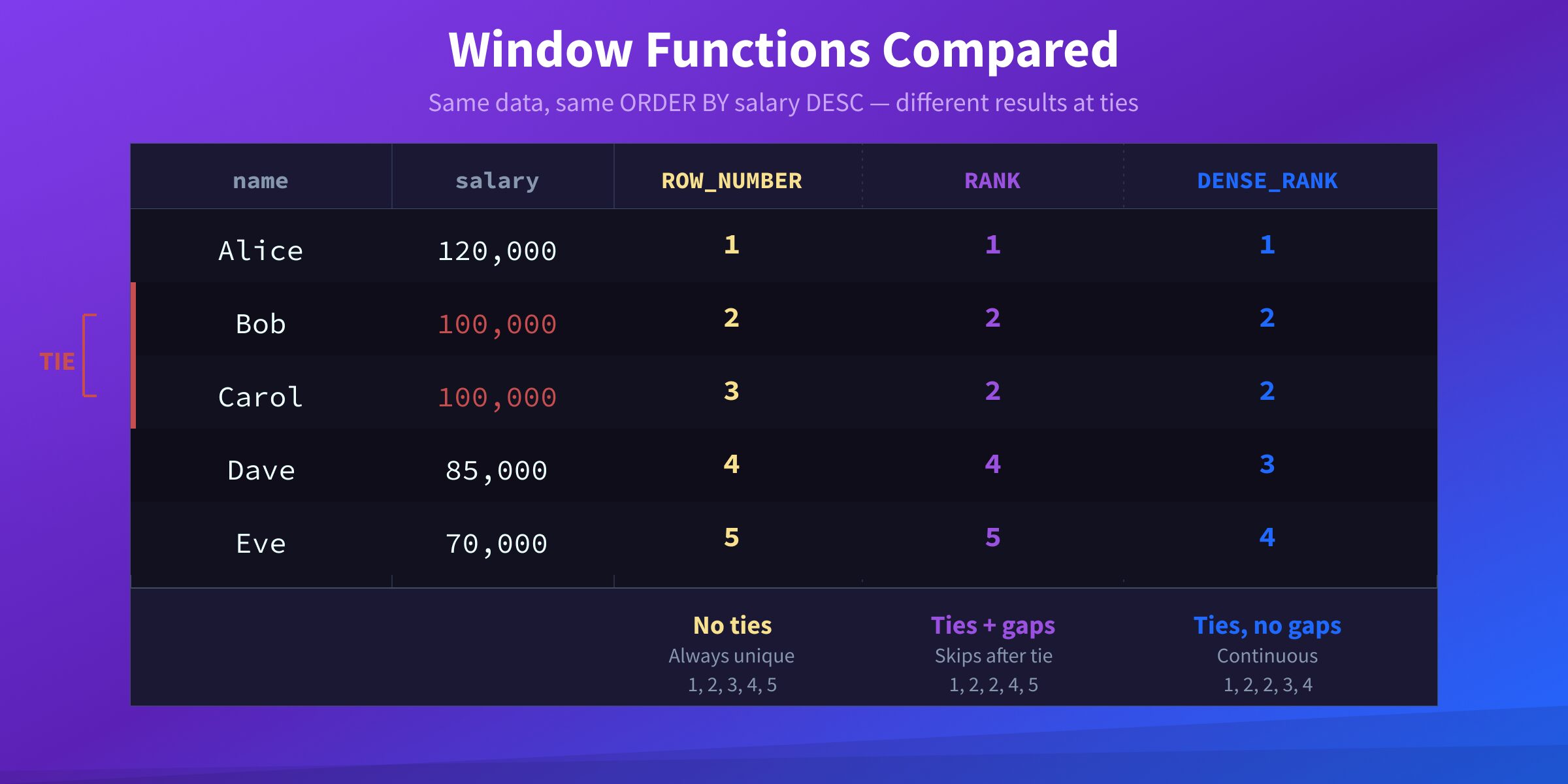
SELECT name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
RANK() OVER (ORDER BY salary DESC) AS rnk,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rnk
FROM employees;32. Write a running total query.
SELECT order_date, amount,
SUM(amount) OVER (ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_total
FROM orders;33. What do LAG and LEAD do?
LAG looks at a value from a previous row. LEAD looks at the next row. Both avoid self-joins for row-to-row comparisons.
SELECT order_date, amount,
amount - LAG(amount) OVER (ORDER BY order_date) AS daily_change
FROM orders;34. What is a recursive CTE?
A CTE that references itself to process hierarchical data (org charts, folder trees, category hierarchies). It has two parts: an anchor member (base case) and a recursive member that joins back to the CTE.
WITH RECURSIVE org AS (
SELECT employee_id, name, manager_id, 1 AS depth
FROM employees WHERE manager_id IS NULL
UNION ALL
SELECT e.employee_id, e.name, e.manager_id, o.depth + 1
FROM employees e
JOIN org o ON e.manager_id = o.employee_id
)
SELECT * FROM org;35. How would you optimize a slow query?
Start by running EXPLAIN (or EXPLAIN ANALYZE) to see the execution plan. Common fixes:
- Add indexes on columns used in WHERE, JOIN, and ORDER BY
- Replace
SELECT *with specific columns - Use WHERE filters to reduce rows early
- Prefer EXISTS over IN for large subqueries
- Pre-aggregate before joining when possible
- Check for missing statistics or outdated index maintenance
36. What is an execution plan?
A report showing how the database engine will (or did) execute your query, which indexes it uses, join strategies, estimated row counts, and where time is spent. In PostgreSQL, use EXPLAIN ANALYZE. In SQL Server, use "Show Execution Plan." Reading execution plans is how you diagnose slow queries.
37. What's the difference between horizontal and vertical partitioning?
Horizontal partitioning splits rows across partitions (e.g., orders by year — 2024 data in one partition, 2025 in another). Queries targeting one year only scan that partition. Vertical partitioning splits columns — storing rarely-used large columns (like BLOBs) separately from frequently-queried columns.
38. What is a deadlock and how do you handle it?
A deadlock occurs when two transactions are each waiting for a lock the other holds — neither can proceed. Most databases detect deadlocks automatically and kill one transaction. To prevent them: keep transactions short, access tables in a consistent order, and use appropriate isolation levels.
39. Name the SQL transaction isolation levels.
Read Uncommitted: Can read uncommitted changes (dirty reads possible).
Read Committed: Only reads committed data. Prevents dirty reads.
Repeatable Read: Locks read rows until transaction ends. Prevents non-repeatable reads.
Serializable: Full isolation — transactions execute as if serial. Prevents phantom reads but has the most performance overhead.
40. What is an anti-join?
An anti-join finds rows in one table that have no match in another. It's commonly written as a LEFT JOIN with a WHERE ... IS NULL filter.
-- Find customers who have never placed an order
SELECT c.customer_id, c.name
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_id IS NULL;41. What is a MERGE statement?
MERGE (also called UPSERT) combines INSERT, UPDATE, and DELETE into one statement. It compares a source table against a target and acts based on whether rows match. Not all databases support MERGE — PostgreSQL uses INSERT ... ON CONFLICT instead, and MySQL uses INSERT ... ON DUPLICATE KEY UPDATE. The syntax below follows the SQL Server / Oracle standard:
-- SQL Server / Oracle syntax
MERGE INTO target_table t
USING source_table s ON t.id = s.id
WHEN MATCHED THEN UPDATE SET t.value = s.value
WHEN NOT MATCHED THEN INSERT (id, value) VALUES (s.id, s.value);In PostgreSQL, the equivalent pattern looks like:
-- PostgreSQL syntax
INSERT INTO target_table (id, value)
SELECT id, value FROM source_table
ON CONFLICT (id) DO UPDATE SET value = EXCLUDED.value;42. What are the risks of dynamic SQL?
Dynamic SQL is built and executed at runtime. It's flexible (you can parameterize table names, columns, or conditions) but carries risks: SQL injection if inputs aren't sanitized, harder to debug, and may miss out on cached execution plans. Always use parameterized queries or prepared statements rather than string concatenation.
43. How would you sessionize events using a 30-minute inactivity window?
Use LAG to find the time gap between consecutive events per user, then flag new sessions and assign session IDs with a cumulative SUM.
WITH gaps AS (
SELECT user_id, event_time,
CASE WHEN event_time - LAG(event_time) OVER
(PARTITION BY user_id ORDER BY event_time) > INTERVAL '30 minutes'
THEN 1 ELSE 0
END AS new_session
FROM events
)
SELECT *, SUM(new_session) OVER
(PARTITION BY user_id ORDER BY event_time) AS session_id
FROM gaps;44. How would you calculate Day-1 and Day-7 retention?
Join the users table to activity, comparing signup date against activity dates.
SELECT
signup_date,
COUNT(DISTINCT u.user_id) AS cohort_size,
COUNT(DISTINCT CASE WHEN a.activity_date = u.signup_date + 1
THEN a.user_id END) AS d1_retained,
COUNT(DISTINCT CASE WHEN a.activity_date = u.signup_date + 7
THEN a.user_id END) AS d7_retained
FROM users u
LEFT JOIN activity a ON u.user_id = a.user_id
GROUP BY signup_date;45. What is the purpose of an index, and when can it hurt performance?
An index speeds up reads by letting the database jump to the right rows instead of scanning every page. But indexes slow down writes (every INSERT/UPDATE/DELETE must also update the index), consume storage, and can be counterproductive on low-cardinality columns or small tables where a full scan is faster.
For advanced practice with window functions and analytical queries, try Dataquest's SQL Window Functions for Northwind Traders guided project.
SQL Interview Questions for Data Engineers (46–55)
Data engineer interviews test SQL in the context of pipelines, data modeling, and scale. These questions go beyond writing correct queries — they test whether you can build systems that run reliably on millions of rows. If you're targeting a DE role, Dataquest's Data Engineer Career Path covers these patterns end to end.
46. What is partition pruning, and why does it matter?
Partition pruning is when the query engine skips entire partitions that don't match your WHERE filter. If a table is partitioned by order_date and your query filters WHERE order_date = '2026-03-27', the engine reads only that one partition instead of scanning the full table. This can turn a minutes-long query into a seconds-long one on large datasets. To benefit from it, always filter on the partition column and avoid wrapping it in functions (e.g., WHERE YEAR(order_date) = 2026 may prevent pruning).
47. What is a star schema and how does it differ from a snowflake schema?
A star schema has a central fact table connected directly to dimension tables — simple, fast queries, some redundancy. A snowflake schema normalizes the dimensions into sub-tables — less redundancy, more joins. Star schemas are more common in analytics because query performance matters more than storage savings.
48. What is a surrogate key and why do data engineers use them?
A surrogate key is a system-generated identifier (usually an auto-incrementing integer or UUID) that replaces natural business keys. Data engineers use them because natural keys can change, be composite, or come from unreliable source systems. Surrogate keys provide a stable, performant join key across the warehouse.
49. How would you design an incremental data load?
Track which rows are new or changed since the last load using a watermark column (like updated_at). On each run, extract only rows where updated_at > last_run_timestamp, then MERGE or INSERT into the target table. This avoids reprocessing the entire dataset every time.
MERGE INTO target t
USING staging s ON t.id = s.id
WHEN MATCHED AND s.updated_at > t.updated_at
THEN UPDATE SET t.value = s.value, t.updated_at = s.updated_at
WHEN NOT MATCHED
THEN INSERT (id, value, updated_at) VALUES (s.id, s.value, s.updated_at);50. What are slowly changing dimensions (SCD Type 2)?
SCD Type 2 tracks historical changes to dimension rows by creating a new row for each change instead of overwriting. Each row has effective_start_date, effective_end_date, and an is_current flag. This lets you answer questions like "What was this customer's address when they placed this order last year?"
51. What is data skew and how does it affect query performance?
Data skew happens when data is unevenly distributed across partitions, one partition has millions of rows while others have thousands. This causes one node to do most of the work while others sit idle. Fix it by choosing better partition keys, salting join keys, or pre-aggregating before joining.
52. What's the difference between a staging table and a production table?
A staging table holds raw, unvalidated data landed from a source system. A production (or mart) table holds cleaned, transformed, business-ready data. Staging tables are temporary or truncated on each load; production tables are the source of truth for reporting and analytics.
53. How would you detect and handle duplicate records in a pipeline?
Use ROW_NUMBER partitioned by the natural key, ordered by a freshness column (like updated_at DESC), then keep only row_num = 1. Run this deduplication step as part of your transformation layer before loading into production tables.
WITH deduped AS (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY updated_at DESC
) AS rn
FROM staging_customers
)
SELECT * FROM deduped WHERE rn = 1;54. How would you make an incremental SQL model idempotent?
An idempotent model produces the same result whether you run it once or five times for the same time window. The key is to DELETE-then-INSERT (or MERGE) for the target partition rather than just appending. First delete all rows in the target where the partition key falls within the current batch window, then insert the fresh results. This way, re-runs don't create duplicates.
-- Delete the window being reprocessed
DELETE FROM analytics.daily_revenue
WHERE revenue_date = '2026-03-27';
-- Reinsert the freshly computed data
INSERT INTO analytics.daily_revenue
SELECT order_date AS revenue_date, SUM(amount) AS total
FROM orders
WHERE order_date = '2026-03-27'
GROUP BY order_date;55. How would you handle late-arriving data in a warehouse table?
Late-arriving data means a record shows up after the batch for its time period has already been processed. Common approaches: use MERGE/UPSERT to update or insert based on the natural key, partition tables by ingestion date (not event date) so late records land without rewriting old partitions, or maintain a separate corrections table that gets reconciled on the next run. Always store the original event timestamp alongside the load timestamp so downstream queries can distinguish late arrivals from on-time data.
Bonus Quick-Fire Questions (56–60)
56. What does COALESCE do?
Returns the first non-NULL value from a list of expressions. Useful for providing defaults: COALESCE(phone, email, 'No contact').
57. What is a cross join?
Returns the Cartesian product — every row from table A paired with every row from table B. Use it intentionally for generating combinations (dates × products), not accidentally.
58. What's the difference between COUNT(*) and COUNT(column)?
COUNT(*) counts all rows including NULLs. COUNT(column) counts only non-NULL values in that column.
59. What does the DISTINCT keyword do?
DISTINCT removes duplicate rows from a result set. It applies to the entire row, not just the first column.
60. How would you remove duplicate rows and keep only the latest?
WITH ranked AS (
SELECT *, ROW_NUMBER() OVER
(PARTITION BY email ORDER BY updated_at DESC) AS rn
FROM users
)
DELETE FROM ranked WHERE rn > 1;Note: The exact delete syntax varies by database. The pattern is the same: rank duplicates with ROW_NUMBER(), keep rn = 1, and delete the rest from the base table.
Resources for SQL Interview Prep
Practice platforms:
- Dataquest SQL Skill Path — interactive courses from fundamentals to window functions, with guided projects
- DataLemur — free SQL practice questions from real FAANG interviews
- LeetCode SQL 50 — curated problem set organized by concept
- HackerRank SQL — challenges ranked by difficulty
Quick reference:
FAQ
How many SQL questions are typically asked in a technical interview?
Phone screens usually include 2–3 conceptual questions.
On-site or take-home rounds typically involve 4–6 hands-on query problems.
Data engineering roles tend to include more SQL questions than general backend positions.
How should I prepare for a SQL interview?
Preparation should focus on practical application, not passive review.
- Practice on real databases. Reading answers isn’t enough. Write queries against actual tables. Dataquest’s SQL Skill Path provides a live coding environment where you practice on real datasets from day one.
- Narrate your thinking. In live coding rounds, interviewers want to hear your reasoning — not just see correct output. Practice saying what you’re doing as you write: “First I’ll join these two tables, then aggregate by department…”
- Study for your specific role. SQL interviews are not one-size-fits-all:
- Data analyst: Focus on JOINs, GROUP BY, subqueries, NULL handling, and increasingly, window functions.
- Data scientist: Add experiment analysis, feature extraction using CASE statements, and time-series query patterns.
- Data engineer: Go deeper into optimization, indexing, schema design, incremental loads, and data quality checks.
What SQL topics should I study first?
Start with JOINs, GROUP BY with aggregation, subqueries, and NULL handling — these appear in almost every interview.
For data analyst roles, add window functions.
For data engineer roles, include query optimization and indexing concepts.
Do I need to memorize SQL syntax for interviews?
No.
Interviewers care more about your logic and problem-solving approach than perfect syntax recall.
Most interviews accept standard ANSI SQL and won’t penalize minor syntax differences between systems like PostgreSQL and MySQL — unless the role requires deep specialization in a specific database.
Are window functions asked in SQL interviews?
Yes — especially for data analyst and data engineer roles.
The most commonly tested functions include ROW_NUMBER, RANK, and running totals using SUM() OVER().
If you’re applying for a data-focused role, window functions should be part of your preparation.
from Dataquest https://ift.tt/2gVfadp
via RiYo Analytics








No comments