https://ift.tt/pJHYlo6 Building an image classifier the practical way (based on a true story) Photo by Elena Mozhvilo on Unsplash Mos...
Building an image classifier the practical way (based on a true story)

Most practitioners first learn deep learning through the lens of image classification. If you’ve taken a programming course, then consider this to be the equivalent of the “hello world” exercise they give you at the start. While many experts say image classification is solved (and there may be some truth in that), there’s a lot of nuance and craft you can learn from this type of problem. With that being said, over the next couple of editions, I’ll share how I build, evaluate and analyze these models through the form of a story. Initially, I considered consolidating everything into a single article. But to spare you from reading my response to Tolstoy’s “War and peace”, I’ve broken it down into pieces. Note: All the code used in this pose can be found here.
So you think you can classify?
To motivate this problem, let’s consider that you’ve been hired as a Computer Vision (CV) engineer at Petpoo Inc, a pet shampoo company. Now you can ask me why in the world would a pet shampoo company need a CV engineer. Even more importantly, why for all the gold on earth would they call themselves Petpoo? I will answer the first question below, but I honestly don’t know the answer to the second.
On your first day, your manager meets you and walks you through your project.
“Hi INSERT_YOUR_NAME_HERE! We’re thrilled to have you here. Petpoo is scaling up and one of the most requested features from our customers is custom shampoo recommendations for their pets. Our customers are social media savvy and want their petfluencers to have the best perm in reels and selfies that they share. They also don’t have time to fill out lengthy questionnaires because they’re busy teaching their pawed companions the perfect duck face. So we’re building a solution to recognize pets based on their pictures. Once we know what kind of breed a pet is, we can recommend custom shampoos from our product lines that will make the pet and its owner happy.
Since a majority of our customers have cats or dogs, we’d like you to build the image classifier to recognize if a pet is a cat or a dog. For starters, let’s keep it at this level. Based on the traction we receive after launch, we can add more features to the solution. Good luck, we’re all counting on you.”
You ask, “What data do we have for prototyping?”.
“Good question. You can start with this dataset”, he replies.
“How are we going to evaluate performance?”, you question.
“For the prototype, use your best judgment.”, he responds and marches off.
Ok, so you need to build an image classifier to distinguish between cats and dogs. You have a dataset to start with and have to figure out how to evaluate the prototype.
You decide to look at the data first. After all, if the data is bad, no amount of machine learning shampoo can save it.
At first glance, this looks like properly processed data that you can start playing with right away. There are nearly 7500 images in total, so that should be sufficient for fine-tuning. The dataset has classification labels for specific pet breeds so you’ll need to modify it so that each image is associated with a cat or dog label instead. Ok, a simple function to do that and we’re all set.

So a cat image will have the label “True” while a dog image will have the label “False”.
Before starting your experiments, you split the data into training and validation sets. You’re smart enough to know that simplicity is always better than sophistication. So, as a first step, you take a well known deep learning model, a ResNet-18 as a baseline. You then turn off all the fancy knobs like schedulers, data augmentation, pretrained weights, and regularization, and pass a batch of data through it. When you check the predictions of the model, you see something like this:
(TensorBase([0.0056, 0.9944]), TensorBase(1.))
Good, the probabilities add up to 1. That means that the basic setup is ok. Feeling confident, you train the model for a few epochs and watch what happens. The loss seems to decrease, but for such a simple problem with such a clean dataset, the accuracy is underwhelming.
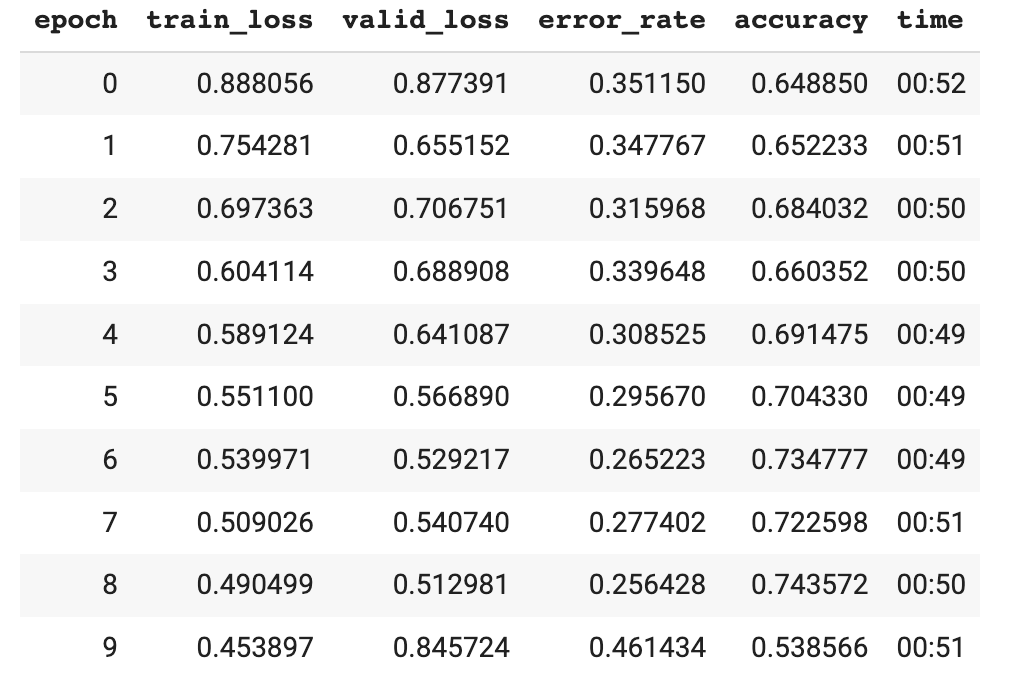
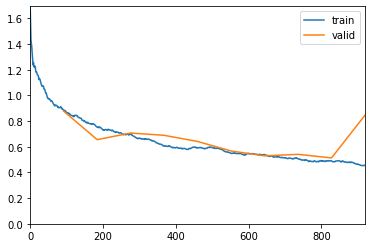
Wanting to make a good first impression, you visualize the examples that were misclassified and also plot the confusion matrix.
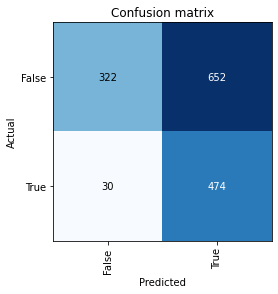

Hmmm, it seems like a whole bunch of dogs are being confused as cats by the model. Strange. Very strange.
You reason that this is because there are insufficient training examples for training from scratch. So you decide to use a technique that has served you well in your career — transfer learning.
After initializing the Resnet-18 with pretrained weights, you repeat the same experiment, keeping everything else intact. The results from this run look awesome. Almost zero errors and wonderful training curves.
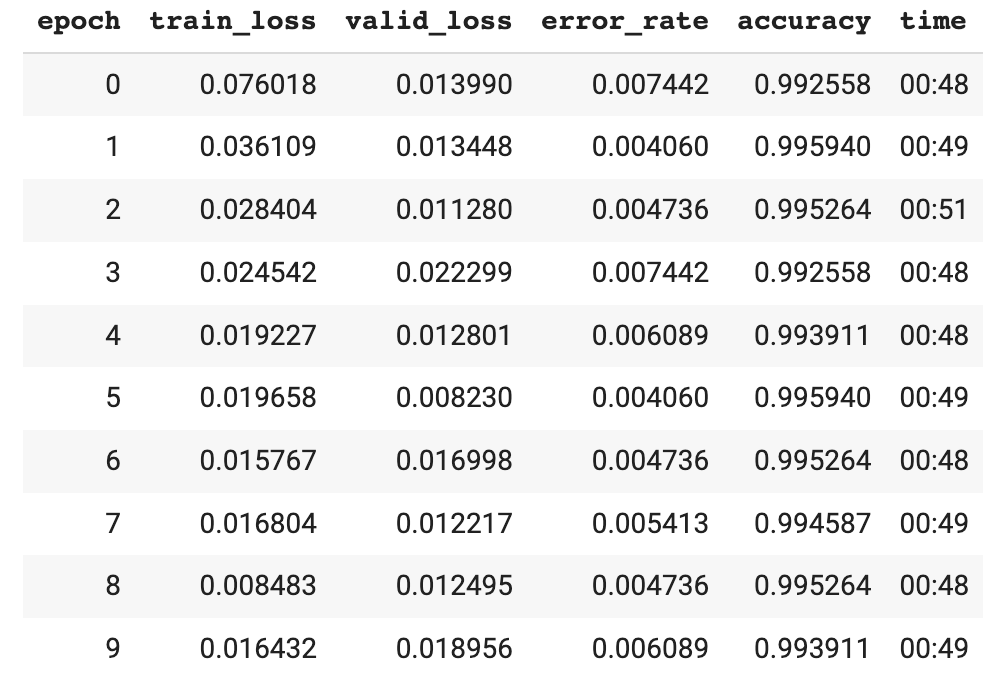
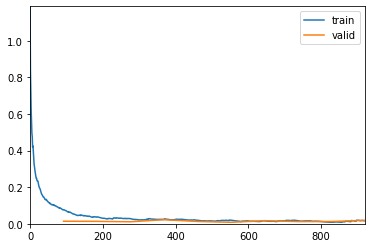
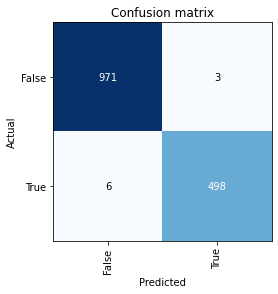
You repeat the same visualization as before and find that only a handful of dogs are being confused with cats.

Happy that your new job is off to a good start, you save all your work and go home in the evening.
Later, much later. 1:30 am… You wake up startled as beads of sweat trickle down your forehead.
You’ve missed a very important detail while setting up the experiment. Accuracy might not be a good metric for this problem at all.
Why?
On the next day, you rush to work and check if your intuition was right. While you inspected sample images and calculated the total size of the dataset, in your rush to get results quickly, you forgot to check how many cat and dog images there were. The dataset was originally designed to classify different breeds of dogs and cats. It may have been balanced (similar number of examples for each class) for that task.
You never checked if it had a similar number of images for cats vs dogs. Feverishly typing on your keyboard, the deafening silence that follows the clackety-clack of the keys confirms your suspicions.
Cats: 2400 or 32.4% of the total data
Dogs: 4990 or 67.6% of the total data
That explains why the first model you trained sucked. The data imbalance confused the model. There were more than double the number of dogs as there were cats in the dataset. The model couldn’t gather enough information to distinguish cats and dogs because most of the images it saw were dogs. But why did the second model you trained work almost flawlessly? You initialized it with weights that were trained on 1.2+ million images many of which were of dogs and cats.
Problem solved! No worries right? Not exactly. Transfer learning (what you did for the second model) doesn’t always work. Transfer learning might fail when there’s a domain mismatch between the pretraining dataset (what the model was originally trained on) and the target dataset (what you are training it on). You got lucky because the pretraining dataset had a similar distribution to the pets dataset you were working with (phew!).
Here’s the next mistake — Defaulting to accuracy as a metric. Look at the confusion matrices side by side. On the left, you have your original experiment, and on the right, you have the transfer learning experiment. For reference, the rows are the ground truth. The first row corresponds to actual images of dogs, and the second row corresponds to actual images of cats. The first column represents what the model *thinks* are dogs and the second column represents what the model considers to be cats.

If you looked at the raw accuracy numbers, you’d have seen a score of 86% accuracy without transfer learning and a score of 99.7% with transfer learning. Not too bad right?
However, in the confusion matrix on the left, you can see that 44 dogs were classified as cats by the model, and 162 cats were classified as dogs. That’s a huge problem you’d have missed by blindly relying on accuracy alone. Why does this happen?
Imagine a worst-case scenario where you only had 90 dog images and 10 cat images and no access to pretrained weights. If you guessed dog as the answer for all 100 images, you’d have an accuracy of 90%. You’d also have a completely useless model.
Thus, on another occasion, using accuracy as a metric would have hidden this fundamental flaw in your model until it was too late. I mean, what if chihuahua totting socialite Haris Pilton had used this, found it useless, and then condemned the product on her social media channels?
As you thank your lucky stars and consolidate results from transfer learning, your manager comes by. “Hey there! How’s your work coming along?”, he asks. “Good, I think I’ve got something.”, you reply nervously. You show him your work with transfer learning and the 0.003 error rate. He is floored. “How soon can we build a demo for this?”, he asks. “I can start putting one together this week”, you respond.
“Our marketing team has connections with top influencers like Haris Pilton, and we’d like for them to try this out and give us feedback.”, he grins. “Umm… Ok”, you gulp as you think back to your gaffe. “Alright, let’s aim for the end of next week. Chop Chop!”, he says, patting you on the shoulder, walking away with delight.
The scribble of pen on paper is punctuated by pregnant pauses. Even though you’re working on designing the app, your thoughts are elsewhere. What should I have used to evaluate the model? How could I have balanced this wonky dataset? Why did I miss these basic steps?
Over the next few days, you build a simple app interface to test the model and see how it works on images from the real world. After all, what’s the point of training a model if you can’t use it for practical applications?
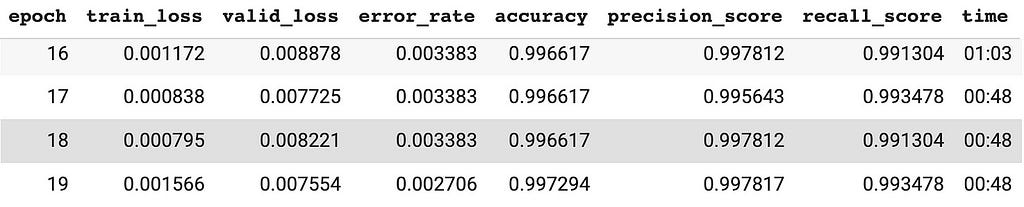
Happy with the initial prototype, you divert your attention to the pressing questions in the back of your head. Opening up a reference textbook, you look through F1-score, ROC, precision, and recall, and all those ideas come flooding back. You rerun the experiments, but in addition to measuring accuracy, you also measure precision and recall. The results make way more sense now — The precision and recall numbers are low for the model without transfer learning while the accuracy hides these flaws. On the other hand, precision and recall are really high for the transfer learned model.

You decide to write a checklist of how one should train a model and evaluate it — just in case you or someone else on your team needs a reference in the future.
But before you can start, your manager comes by. You show him the app-in-progress and he’s delighted. “This is great! Our marketing team spoke to some of the influencers, and they’d like the app to be even more customized — recommendations per breed. I tried talking them out of it, but they’ve committed to having that ready when the influencers visit HQ by the end of next week. Think you have that ready by then? I understand this is going to take some hardcore engineering.”, he says apologetically. “Granular classification? By the end of next week? That’s a tough ask. Can I have another pair of hands to work with me on this?”, you ask surprised by the sudden change in requirements and the receding timeline. “Umm…”, he pauses…
(The conclusion of this series will drop sometime in 2023 — It’s still in pre-production)
Here are my questions for you:
How would you handle this new task? What do you think the best approach is given these constraints? What should you be mindful of?
There are no right answers, only tradeoffs. Drop me a note with your ideas or leave a comment in this post.
Dataset details:
Oxford Pets dataset — The dataset is available to download for commercial/research purposes under a Creative Commons Attribution-ShareAlike 4.0 International License. The copyright remains with the original owners of the images.
“Practically” Building an Image Classifier was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/practically-building-an-image-classifier-531443b3b483?source=rss----7f60cf5620c9---4
via RiYo Analytics






No comments