https://ift.tt/Wa8H90F Background of anonymization and how to build an anonymizer Photo by Markus Spiske on Unsplash With various reg...
Background of anonymization and how to build an anonymizer

With various regulations following the enforcement of GDPR in Europe, properly handling sensitive information, specifically Personally Identifiable Information(PII) became a requirement for many companies. In this article, we discuss what PII is and how we can anonymize PII in unstructured data — text in particular. We’ll also demonstrate an example implementation of a text anonymizer using Microsoft Presidio, an open-source library that provides fast PII identification and anonymization modules. This article is divided into the following sections:
- Background: Privacy and Anonymization
- Existing Anonymization Techniques
- Customize PII anonymizer with Microsoft Presidio
- Conclusions, Links, and References
Jump to any section that you find most interesting!
Background
Data protection and privacy preservation techniques have been researched and applied as early as the 1850s, when the US Census Bureau started to remove personal data from the publicly available census data about US citizens. Since the early use of simple techniques such as adding random noise or aggregation, various models have been proposed and improved. Privacy is a basic human right. According to the dictionary definition, it is
the ability of an individual or group to seclude themselves or information about themselves, and thereby express themselves selectively.
What personal information is considered sensitive information that could link to an individual’s privacy being impaired? The European Union introduced the toughest privacy and security law General Data Protection Regulation (GDPR) in 2018. GDPR defines personal data as
“Any information that relates to an individual who can be directly or indirectly identified. Names and email addresses are obviously personal data. Location information, ethnicity, gender, biometric data, religious beliefs, web cookies, and political opinions can also be personal data.”
Depending on whether a piece of information can be used directly or indirectly to re-identify an individual, one can categorize the information mentioned above into direct-identifiers and quasi-identifiers.¹
- Direct-identifiers: A (set of) variable(s) unique for an individual (a name, address, phone number, or bank account) that may be used to directly identify the subject.
- Quasi-identifiers: Information (such as gender, nationality, or city of residence) that in isolation does not enable re-identification, but may do so when combined with other quasi-identifiers and background knowledge.
Existing Anonymization Techniques
The data protection regulations put companies and individuals in a constant struggle between utilizing data for insights and preserving privacy. However, anonymization techniques can be applied to datasets so that it is impossible to identify specific individuals. In this way, these datasets will no longer be within the scope of data protection regulations.
Anonymizing Structured Data
When it comes to anonymizing structured data, there are established mathematical models of privacy such as K-anonymity or differential privacy.
K-anonymity was introduced in 1998 by Pierangela Samarati and Latanya Sweeney². A masked dataset has k-anonymity property if in the dataset each information that a person contains, cannot be distinguished from at least k-1 other individuals. Two methods can be used to achieve k-anonymity. One is suppression, completely removing an attribute’s value from a dataset; another one is generalization, replacing a specific value of an attribute with a more general one.
L-diversity was a further extension of k-anonymity. If we put sets of rows in a dataset that have identical quasi-identifiers together, there are at least l distinct values for each sensitive attribute, then we can say that this dataset has l-diversity.
Differential privacy was introduced by Cynthia Dwork from Microsoft Research in 2006.³ It is a property that a process or algorithm satisfies if the output of it will be roughly the same, whether or not one individual contributes his or her data. In other words, by merely observing the output of a differentially private analysis, one cannot say for certain if a particular individual is in the dataset or not. With differential privacy, we can learn useful information about a population, without knowing information about an individual.
Algorithms that calculate the statistics about a dataset such as mean, variance, or perform certain aggregations can be viewed to be differentially private. It can also be achieved by adding noise to the data. Differential privacy uses a parameter epsilon to regulate the trade-off between privacy and the usefulness of the dataset.
There are also some well-known techniques to be applied in a structured database for anonymization:
- Masking: removing, encrypting, or obscuring the private identifiers
- Pseudonymization: Replace the private identifiers with pseudonyms or false values
- Generalization: Replacing a specific identifier value with a more general one
- Swapping: Shuffling the attribute values of the dataset so that they are different from the original one
- Perturbation: Changing the data by introducing random noises or using random methods
Anonymizing Unstructured data
The process of anonymizing unstructured data, such as text or images, is a more challenging task. It entails detecting where the sensitive information is present in the unstructured data and then applying anonymization techniques to it. Because of the nature of the unstructured data, directly using simple rule-based models might not have a very good performance. Exceptions are cases like email or phone numbers, which can be quite effectively detected and anonymized by pattern-based methods (such as RegEx). Other challenges include the types of identifiers varying from country to country. So it is hard to design a one-fits-all system that can be applied in all use cases. Typical types of identifiers include what were mentioned in the above sections — name, email, driver's license, etc. Besides those, one could find an exhaustive list here about types of sensitive information.
Apart from rule-based methods, Natural Language Processing (NLP) techniques have been applied to text anonymization as well. In particular, techniques used for Named Entity Recognition (NER) tasks. It is a type of sequence labeling task. The label in this case indicates if a token (like a word) corresponds to a named entity, such as PERSON, LOCATION, or DATE.
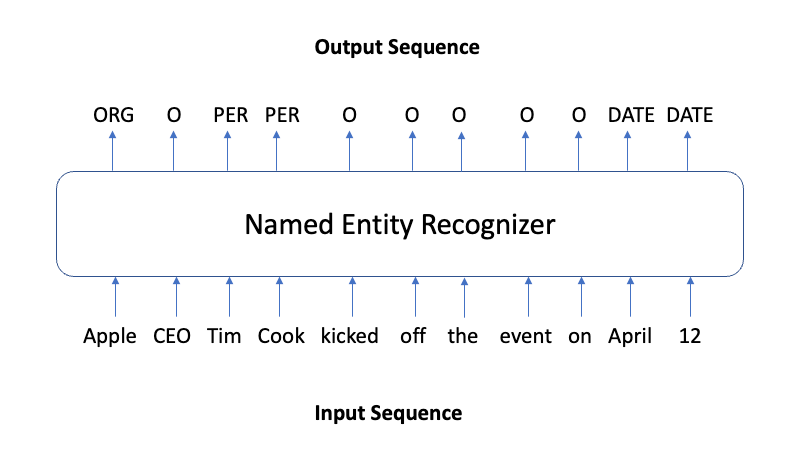
Several neural models have achieved state-of-the-art performance on NER tasks on datasets with general named entities. When they are trained on medical domain data that contains various types of personal information, they are shown to achieve state-of-the-art performance on those data as well. These model architectures include Recurrent Neural Networks with character embeddings⁴ or Bidirectional Transformers⁵. SpaCy also has a NER model. It is a RoBERTa language model fine-tuned on the Ontonotes dataset with 18 named entity categories, such as PERSON, GPE, CARDINAL, LOCATION, etc (see the full list of entity types here). Another tool to use out-of-the-box is Presidio. It’s an anonymization SDK developed by Microsoft that relies on rule-based and NER-based models to detect and mask PII. The list of supported entities can be found here.
What happens after recognizing the PII?
One approach is to replace the identifier with a dummy value. For example, if a person’s name or phone number is recognized in a sentence like “My name is Amy and my number is 85562333”, then the anonymized text can be “My name is <PERSON_NAME> and my number is <PHONE_NUMBER>”. It is simple and straightforward but there is some disadvantage to this method. We lose important information when using one value for all the same entity types. In this example, we would not know what is the gender of the person. Depending on the use of the anonymized text, it can be desirable to keep such information. Or when it comes to addresses, one would like to preserve the geographical distribution to a certain level.
Another method is to replace the detected entity with a surrogate value. It can be either randomly sampled from a pre-determined list for each entity type, or according to some rule. There also are Python packages such as Faker that can generate synthetic addresses or names to use as the surrogate value.
Customize PII anonymizer with Microsoft Presidio
When we apply PII anonymization to real-world applications, there might be different business requirements that make it challenging to use pretrained models directly. Imagine for example that a company in Norway reaches out to you and wants you to develop a text anonymizer for them. They want it to support anonymizing PII in both English and Norwegian text. Apart from the common PII entities, you would also need to detect Norwegian National ID numbers that follow certain checksum rules. A pre-trained NER model is great, but you can’t easily add new entity types without using extra labeled data to finetune the model to achieve good performance. Hence, it is nice to have a tool that could leverage the pretrained model and is easy to customize and extend the functionality.
Microsoft Presidio is an open-source SDK that does exactly this. According to them,
Presidio embraces extensibility and customisability to specific business needs, allowing organizations to preserve privacy in a simpler way by democratizing de-identification technologies and introducing transparency in decisions.
It has two major parts — the Analyzer and the Anonymizer. The Analyzer is a Python-based service for detecting PII entities in text. It leverages Named Entity Recognition, regular expressions, rule-based logic, and checksum with the relevant context in multiple languages. For example, it uses pre-defined Regex pattern-based recognizers for email and IP addresses, and the SpaCy natural language processing model for building a recognizer for named entities.
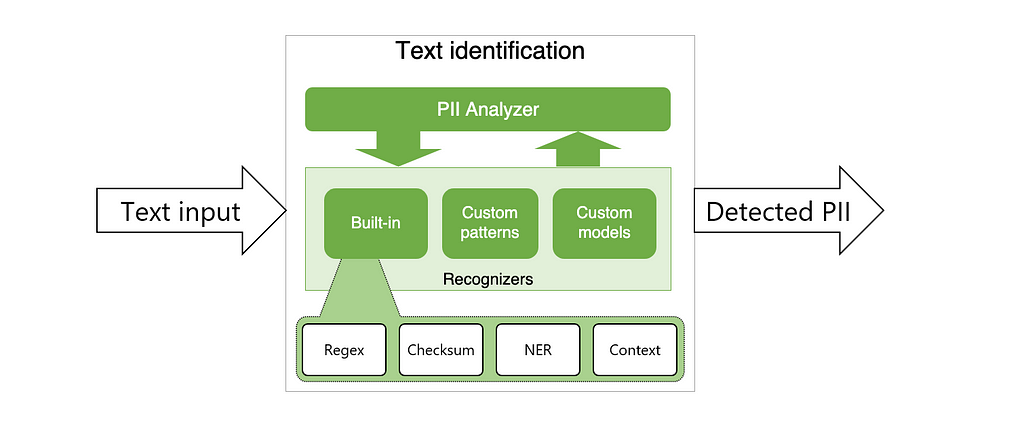
The Anonymizer is also a python based service. It anonymizes the detected PII entities with desired values by applying certain operators such as replace, mask, and redact. By default, it replaces the detect PII by its entity type such as <EMAIL> or <PHONE_NUMBER> directly in the text. But one can customize it, providing different anonymizing logic for the different types of entities.
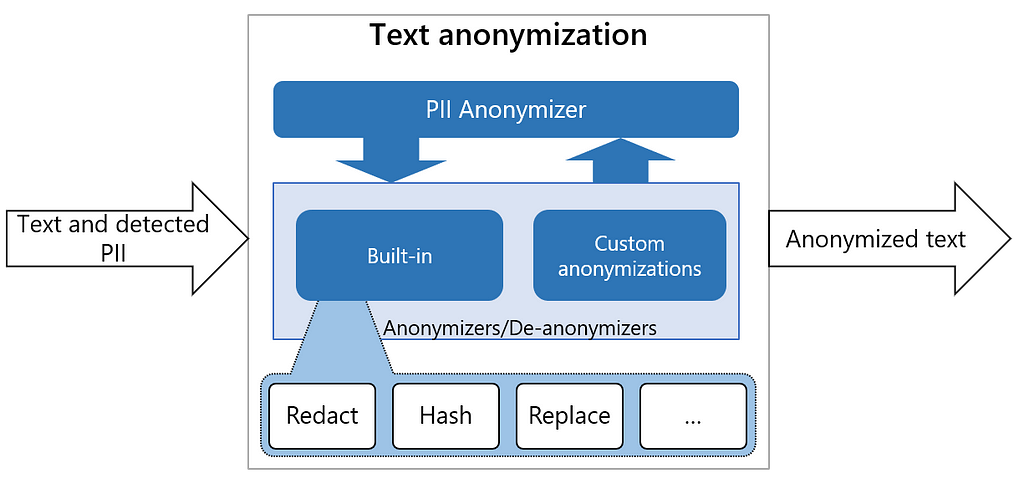
To get started, after installing Presidio as instructed here, using it is as easy as calling the default AnalyzerEngine and AnonymizerEngine:
The AnalyzerEngine orchestrates the detection of PII. A few of its most important attributes include:
- registry: RecognizerRegistry that contains all the pre-defined or customized recognizers to be used on the text
- nlp_engine: abstraction of the NLP modules that include processing functionalities on tokens in the text
- supported_languages: list of supported languages
Using the default analyzer is not enough for our aforementioned scenario, we need to make our own customized analyzer engines by adding the following customizations.
1. Additional language support
By default, Presidio works with English text. But since in our case we will be dealing with Norwegian text as well, we need to add the Norwegian language to the configuration for NlpEngineProvider for Presidio.
This is the Norwegian language model pipeline on SpaCy. The language model also needs to be downloaded before the analyzer is run.
2. Add Norwegian phone number recognizers
There is a set of pre-defined recognizers in Presidio. See the detailed entity list here. We can choose to load some or all of them. One advantage that Presidio has is that it is very easy to add recognizers that suit one’s use case. In the example below, we added a recognizer for the Norwegian phone number that starts with the +47 country code, since the default phone number recognizer does not support all country codes.
3. Add Norwegian National ID recognizers
The Norwegian ID number contains a person’s birthday and some digits following certain rules (see detailed rules here). We can create a class for Norwegian ID recognizer, which extends the EntityRecognizer from Presidio in the following way:
And finally, putting everything together, we have our customized analyzer:
When we run the analyzer to analyze a piece of text (by calling analyzer.analyze(text), optionally giving a list of entity types to recognize), the text is going to pass through a pipeline of recognizers as we defined. There are three main types of recognizers that we can add — pattern-based recognizers, rule-based recognizers, and external recognizers. In this example, we need to add rule-based recognizers. Rule-based recognizers leverage the NLP artifacts, which are token-related information such as lemmas, POS tags, or entities, produced by the NLP engine for recognizing PII.
For recognized PII, it will return a dictionary containing detailed information:
{
'entity_type': 'NORWEGIAN_ID',
'start': 74,
'end': 85,
'score': 0.95
}
In terms of anonymization, we can directly mask the PII entity by its type <NORWEGIAN_ID> in the text and get something like “My id is <NORWEGIAN_ID>”, or we can provide a dictionary of custom operators to the Anonymizer. For example, we can create a random 11-digit for replacement of the ID. Furthermore, we can also use packages such as faker to generate synthetic names.
Test the anonymizer with some examples
For testing the performance of the anonymizer, we find recruitment messages from LinkedIn in both Norwegian and English. They usually have many PII entities. Some sample texts are shown below (Note: what is published here are redacted versions so they do not contain any real identifiers).
Submitting the sample texts to our anonymizer pipeline, we obtain the following results:
As we can see, for English text, the anonymizer has a very good performance, detecting all the names, emails, and telephone numbers. For Norwegian text with proper text syntax, the detection performance is also very good. However, when it comes to Norwegian text that is not a proper sentence, such as the 4th example, we can see that it struggles a bit and confuses the phone number with a date. For those who are interested in a more elaborated performance evaluation, check out this paper, where they carry out a study of applying Presidio on a small manually labeled dataset from Wikipedia text.
Conclusions
In this article, we talked about the background of privacy and PII and showed how to use Presidio to build a custom PII anonymizer. The results on real-world text are promising. There are possible further improvements that we can pursue. We can replace the underlying language model with a more powerful one for better performance on NER. For recognizing more PII entities defined by different countries, we can also add more rule-based recognizers.
Final notes:
I work as a Data Science Consultant in Inmeta, part of Crayon Group. We’re seeing an increasing number of customers who are interested in the proper handling of PII, so we are very thankful for good open-source libraries like Presidio that enable us to leverage state-of-the-art technologies for solving this problem.
Check out the full implementation of the customized anonymizer in my Github repository. It also includes scripts for running it as a Docker app and deploying it to AWS. Thank you for reading the article! I’d love to hear your thoughts on the topic! Feel free to connect with me on LinkedIn.
References
- ^ Pierre Lison, Ildikó Pilán, David Sánchez, Montserrat Batet, and Lilja Øvrelid, Anonymisation Models for Text Data: State of the Art, Challenges and Future Directions (2021). Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing
- ^ Pierangela Samarati and Latanya Sweeney, Protecting Privacy when Disclosing Information: k-Anonymity and its Enforcement through Generalization and Suppression (1998). Technical report, SRI International
- ^ Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith, Calibrating Noise to Sensitivity in Private Data Analysis (2006). Theory of Cryptography
- ^ Franck Dernoncourt, Ji Young Lee, Ozlem Uzuner, and Peter Szolovits, De-identification of patient notes with recurrent neural networks (2017). Journal of the American Medical Informatics Association
- ^ Alistair EW Johnson, Lucas Bulgarelli, and Tom J Pollard, De-identification of free-text medical records using pre-trained bidirectional transformers (2020). Proceedings of the ACM Conference on Health, Inference, and Learning
PII anonymization made easy by Presidio was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/msIJyiv
via RiYo Analytics









No comments