https://ift.tt/TX5UmdR By Mateo Espinosa Zarlenga and Pietro Barbiero . From the NeurIPS paper “ Concept Embedding Models ” ( GitHub ). T...
By Mateo Espinosa Zarlenga and Pietro Barbiero. From the NeurIPS paper “Concept Embedding Models” (GitHub).
TL;DR
- Problem — Human trust in deep neural networks is currently an open problem as their decision process is opaque. Current methods such as Concept Bottleneck Models make the models more interpretable at the cost of decreasing accuracy (or vice versa).
- Key innovation — A supervised concept embedding layer that learns semantically meaningful concept representations and allows simple human test-time interventions.
- Solution — Concept Embedding Models increase human trust in deep learning going beyond the accuracy-explainability trade-off — being both highly accurate and interpretable.
Learning Concepts: the New Frontier of Explainable AI
Concept Bottleneck Models (or CBMs, [1]) have, since their inception in 2020, become a significant achievement in explainable AI. These models attempt to address the lack of human trust in AI by encouraging a deep neural network to be more interpretable by design. To this aim, CBMs first learn a mapping between their inputs (e.g., images of cats and dogs) and a set of “concepts” that correspond to high-level units of information commonly used by humans to describe what they see (e.g., “whiskers”, “long tail”, “black fur”, etc…). This mapping function, which we will call the “concept encoder’’, is learnt by — you guessed it :)— a differentiable and highly expressive model such as a deep neural network! It is through this concept encoder that CBMs then solves downstream tasks of interest (e.g., classify an image as a dog or a cat) by mapping concepts to output labels:
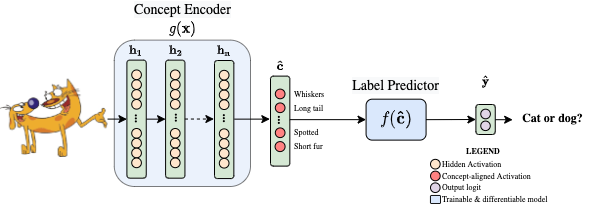
The label predictor used to map concepts to task labels can be your favourite differentiable model, although in practice it tends to be something simple like a single fully connected layer. Thanks to CBM’s ability to learn intermediate concepts as part of its predictive process, they can:
- provide simple concept-based explanations for their predictions. These are explanations that humans can intuitively understand as opposed to feature-based explanations that require a high mental load from the user (e.g., saliency maps). For instance, in image classification a concept-based explanation could look like: “if red and round, then it is an apple”, which is more intuitive than a feature-based explanation such as: “if pixel-#7238 and pixel-#129, then it is apple”.
- allow human experts to interact with the model changing mispredicted concepts at test time, significantly improving task accuracy with expert interaction.
Both concept-based explanations and human interventions significantly contribute to increasing human trust in CBMs. This is due to (i) their interpretable-by-design architecture, (ii) the clear alignment between terms used in a CBM’s explanations and known human categories used by experts, and (iii) their native support for human interaction allowing experts to test the strength of the causal dependency of the tasks on learnt concepts through concept interventions.
Concept Bottleneck Models increase human trust providing intuitive concept-based explanations and supporting human interventions on concepts.
The End of a Fairy Tale: The Accuracy-Explainability Trade-Off in CBMs
As with everything in life, CBMs have an unfortunate dark side to them. In their inception, Concept Bottleneck Models tried to promote trustworthiness “by design” by conditioning classification tasks on an intermediate level of human-like concepts. Nevertheless, here is where our love story ends and the realization that there is no such thing as free lunch comes to reality. Although CBMs are more interpretable than traditional deep neural networks by construction, this new interpretability may come with a significant cost on task accuracy! This is particularly exacerbated in real-world scenarios where concept supervision required to train a model is scarce, thus questioning the practical utility of CBMs. This can be seen in the following figure where we observe a sharp drop in a CBM’s task accuracy drops as the number of concepts we supervise is reduced:
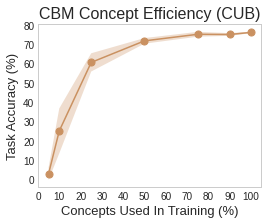
Vanilla Concept Bottleneck Models may break in real-world conditions when concept supervisions are scarce or classification problems get tough.
To address this limitation, Manhipei et al. [2] explored a hybrid version of CBMs where the concept layer is augmented with a set of unsupervised neurons allowing the model to use this extra learning capacity to solve the classification tasks:
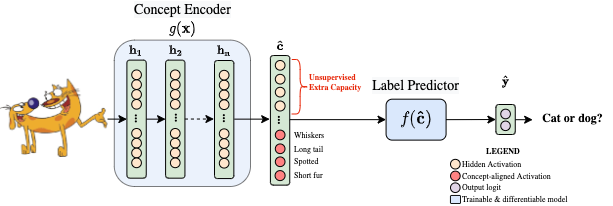
This trick allows hybrid CBMs to outperform vanilla CBMs in terms of task accuracy. However, this increased performance comes at the cost of the model’s interpretability and trustworthiness as:
- the extra neurons are typically not aligned to any known human concept
AND
- the effect that concept interventions have on the output label drastically decreases, suggesting that the model is solving the task using the extra neurons rather than the learnt concepts.
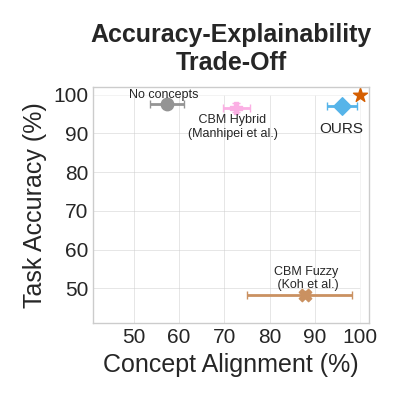
Empirically, we can observe such atrade-off between task accuracy and the alignment of ground truth labels with concepts learnt by different Concept Bottleneck Models in the following figure (we also included an end-to-end model without a concept layer as a reference):
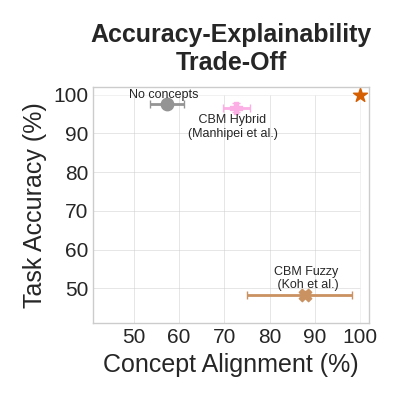
Vanilla and Hybrid Concept Bottleneck Models offer different compromises between accuracy and explainability, but they are far from the optimum!
This is a simple example of the so-called “accuracy-explainability trade-off”: in many non-trivial problems you can either get:
- a simpler but less accurate model (e.g., Koh et al. CBM)
OR
- a more accurate but less interpretable model (e.g., Manhipei et al. CBM).
The problem with less interpretable models is that humans tend to distrust their predictions because they don’t understand the decision process nor they can check whether this process makes sense — thus questioning the ethical and legal repercussions of the deployment of such models.
For these reasons, this ACCURACY-EXPLAINABILITY TRADE-OFF is one of the most challenging open problems “cursing” modern machine learning (and concept-based models in particular). This is why solving this problem is one of the “gold nuggets” in the field!
The accuracy-explainability trade-off “curses” modern machine learning, including Concept Bottleneck Models! It’s hard to maximize both accuracy and explainability when solving non-trivial problems.
Beyond the Accuracy-Explainability Trade-Off
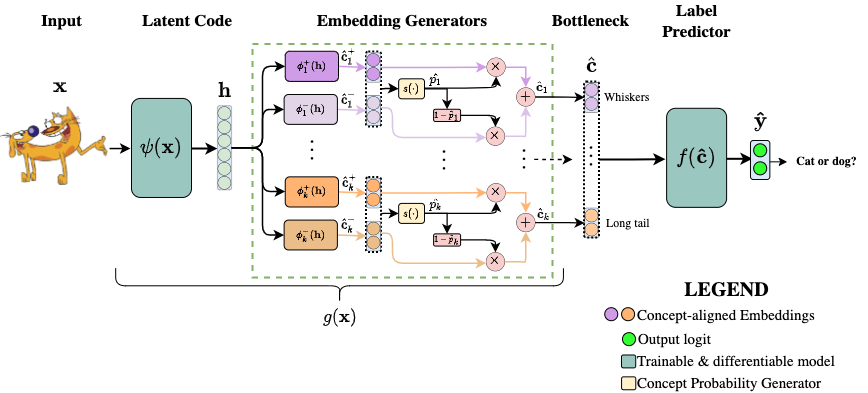
To address this accuracy-explainability trade-off in concept-based models, we recently proposed Concept Embedding Models (CEMs, [3]), a class of concept-based models where:
- The architecture represents each concept as a supervised vector. Intuitively, using high-dimensional embeddings to represent each concept allows for extra supervised learning capacity, as opposed to hybrid CBMs where the information flowing through their unsupervised bottleneck activations is concept-agnostic.
- The training procedure includes a regularisation strategy (RandInt) exposing CEMs to concept interventions during training to improve the effectiveness of such actions at test time.
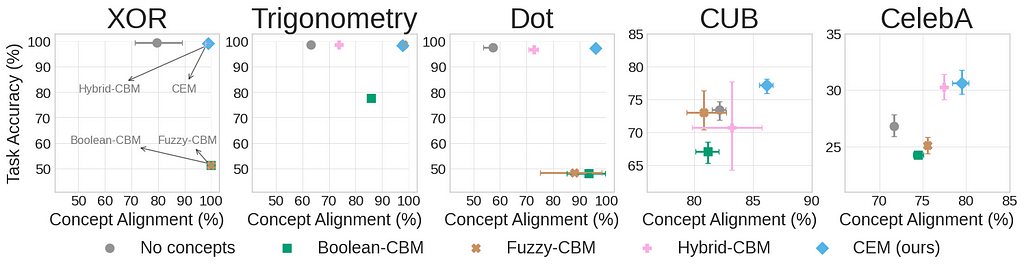
Our experiments on both simple toy and challenging real-world data sets demonstrated that CEMs:
- OVERCOME the accuracy-vs-explainability trade-off being as ACCURATE as equivalent black-box models in solving classification problems (and possibly even more accurate!) and as EXPLAINABLE as traditional CBMs in terms of (a) the extent to which learnt concept representations align with concept ground-truths:
- SUPPORT effective human interventions allowing human experts to interact with the model improving prediction accuracy by fixing mispredicted concepts at test time as opposed to hybrid CBMs:
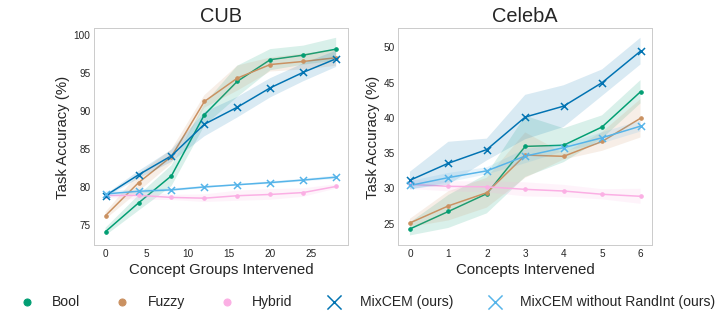
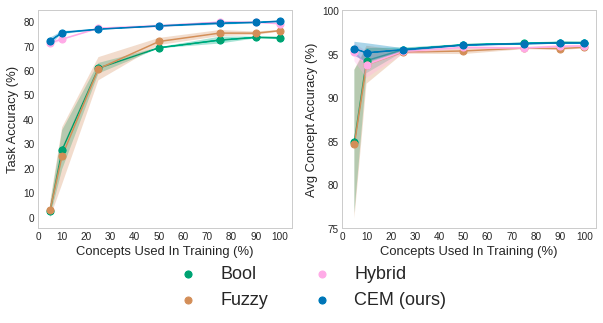
- SCALE to real-world conditions where concept supervisions are scarce:
- PROVIDE concept-based explanations as vanilla CBMs using the predicted activation state of each concept (e.g., “if red and round and not wings, then it is an apple”).
Concept Embedding Model go beyond the accuracy-explainability trade-off in Concept Bottleneck Models — they are both accurate and explainable!
Finally, by supervising the whole embedding, CEMs learns concept representations with a much sharper distinction between the activation state / truth value of the concept when compared to unsupervised embeddings learnt by Hybrid CBMs as shown in the following example:

This suggests that CEMs are able to encode in each concept vector both explicit symbolic information (i.e., concept being active or inactive) subsymbolic concept-semantics (i.e., subclusters in each concept embedding), as opposed to Hybrid CBMs.
Take Home Message
CEMs go beyond the current accuracy-explainability trade-off, significantly increasing human trust!
In particular CEMs are:
- as accurate as standard end-to-end models without concepts (and often even more accurate!);
- as explainable as standard Concept Bottleneck Models (and often even more explainable!);
- as responsive to human interventions as standard Concept Bottleneck Models.
References
[1] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International Conference on Machine Learning, pages 5338–5348. PMLR (2020).
[2] Anita Mahinpei, Justin Clark, Isaac Lage, Finale Doshi-Velez, and Weiwei Pan. Promises and pitfalls of black-box concept learning models. arXiv preprint arXiv:2106.13314 (2021).
[3] Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, Pietro Lio, and Mateja Jamnik “Concept Embedding Models.” arXiv preprint arXiv:2209.09056 (2022).
Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/x0UVwnP
via RiYo Analytics









No comments