https://ift.tt/wslMyoe Modelling geopolitical risk based on UK parliament transcripts Image by Author In text analysis, topic models ar...
Modelling geopolitical risk based on UK parliament transcripts
In text analysis, topic models are a prominent approach to extract overall themes from large collections of documents. Maybe the most widely used model in this domain is the Latent Dirichlet Allocation (LDA).
LDA is a probabilistic topic model, and exists in many variations. Today we will look at one of these: The seeded LDA model.
A seeded topic model allows the researcher to pass a collection of keywords to the model, which outlines the sought out themes before the estimation. This seeding provides more control over the estimation process, and also leads to “better” interpretability of the results.
In my recent master thesis, I explored how to measure the abstract concept of geopolitical risk based on text data. For this, I used transcripts of the UK’s House of Commons parliament debates of the last 200 years, and applied a seeded topic model.
Data science can help provide new measuring tools and can enable us to incorporate new, or more precise variables into econometric models.
In my application, this meant to measure geopolitical risk with a seeded LDA topic model, and plug this measurement into a Vector Autoregression.
I would like to give you an overview of seeded LDA models and provide some code snippets for a basic setup.
Why LDA at all?
LDA models assume that a document, consists of a mixture of different topics, and that each of these topics is a mixture of words.
You can extend LDA models in various ways. For example, your can incorporate meta information on the documents, such as their author, or the time of their release.
For me, a dynamic seeded LDA model seemed adequate. As it is a dynamic model, your topics can evolve over the course of time, creating threads of history, rather than a snapshot.
The world changed significantly over the last 200 years. Developments such as the Cold War, the invention of Nuclear Weapons, or changes in language could change how debates from 1810 read, compared to ones from 2010.
Why Seeded LDA?
The temptation to interpret the topics found by a regular LDA model is huge.
A topic containing words such as war, military, or weapons, just has to be about geopolitical risk — right?
Wrong. In a strict sense at least.
If you want to measure a concept, it is important to have a tool which delivers objectively interpretable topics.
In this context, objective means, that you need to pass an explicit definition of the concept before actually estimating your model. Otherwise, you will find yourself cherry-picking afterwards, making a subjective interpretation.
Compare this to proving to your friend that you can make a half-court shot with the basketball: To do it right, you have to announce the shot first, and then score a basket. Rather than hitting a shot, and yelling “I told you so” afterwards.
Toolbox: Quanteda and keyATM
I would recommend to work with R for seeded LDA, mainly because of the libraries quanteda (data cleaning) and keyATM (seeded LDA models).
I want to provide you with a short overview of which steps are necessary to compute a dynamic seeded LDA model.
For more in-depth explanations visit the documentations for quanteda, and keyATM respectively.
Preprocessing the Data
First, you need to preprocess the data. For this we create a corpus first.
In a second step, we can preprocess this corpus with the function tokens and transform it to a format suitable for the keyATM model with keyATM_read.
For dynamic seeded LDA models, it is necessary to create a period variable which starts at 1 and counts up by one for every period. In the code below, one period reflects 5 years, starting with the year 1805.
Keyword Dictionary
We seed the topic model with a keyword dictionary.
You can pass as many keywords as you like per topic. However, the model’s fit strongly depends on the quality of your keywords. For example, good keywords occur in many documents and are unique to the concept of interest.
Specify and Estimate the Model
Now, we can specify some hyper-parameters for our model. Again, for more in-depth explanations visit the documentations mentioned above.
Note that it is important to allow for no_keyword_topics, as it enables the model to also freely explore patterns in the data.
Finally, we can combine all these components as arguments in keyATM to estimate our model.
It is important to keep in mind that the estimation can taken a long time, and might require significant resources. The computational cost depends, besides other factors, on the number and length of the documents.
Example: Measure Geopolitical Risk with Debate Transcripts
After the estimation, we should evaluate the model in a holistic fashion, i.e. assess the quality of fit in different ways.
For example, we can look at our resulting topics. We get the most “important” words to a topic, as estimated by our model, with the function top_words.
For my application, words like military, defence, or army are the top words for the topic representing geopolitical risk (topic war). Notice, how we also get topics for the concepts treasury, education, and peace with the same estimation. By specifying more topics in the keyword dictionary we can get multiple seeded topics at once: While the computation time increases to a small extent, we can get additional measurements “almost” for free.

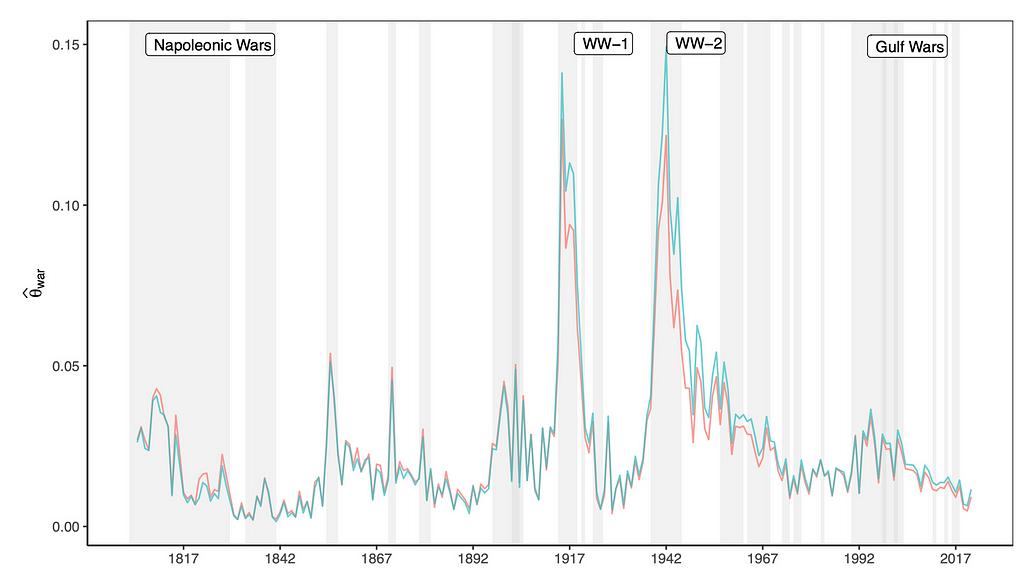
For dynamic topic models, you also want to plot your topics over the course of time to see their development. The graph below shows the estimated share of geopolitical risk in a debate, over time. Shaded areas represent times of military conflict for the UK.
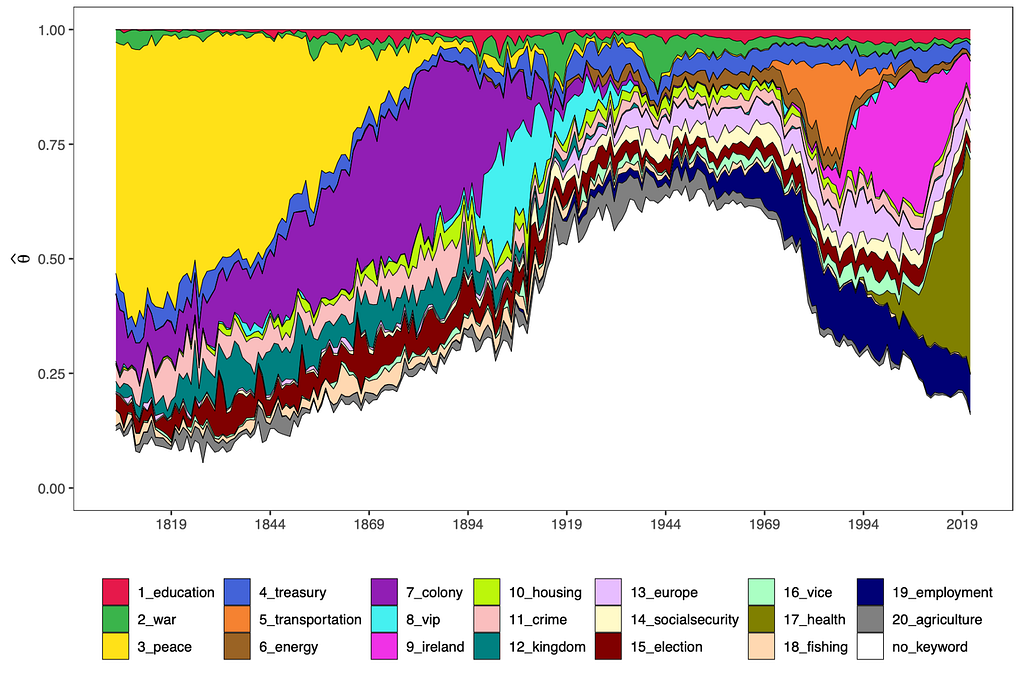
You can also visualise the development of all topics’ shares over time. All no-keyword topics’ shares have been aggregated into the white area below.
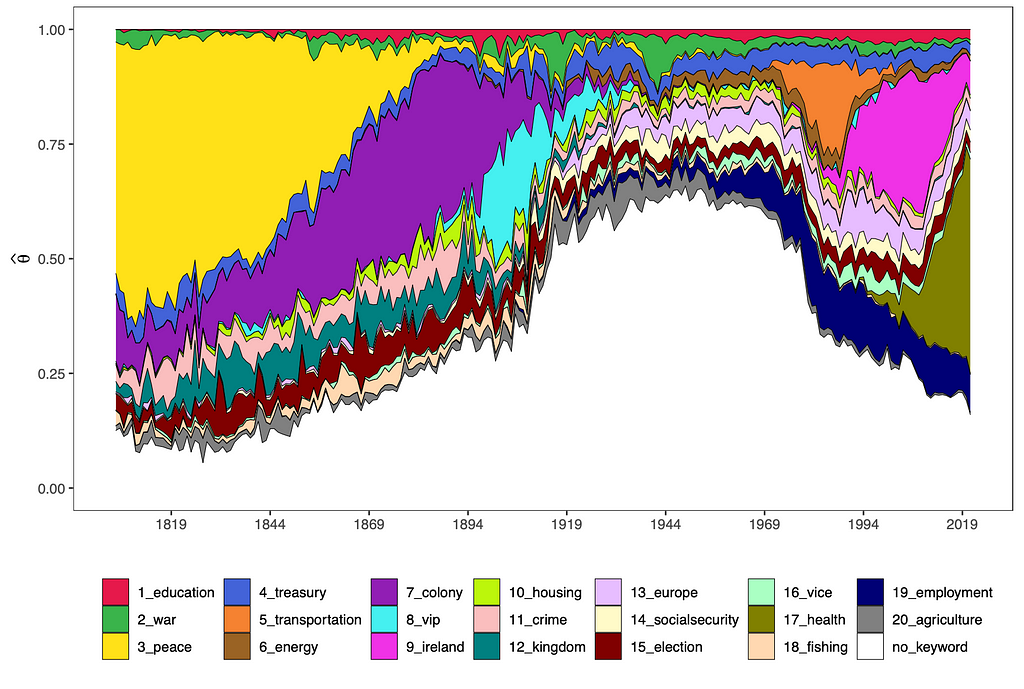
While some of these topic’s time-trends appear to be reasonable, such as the importance of the topic “colony” before the first World War, there are some topics with a poor fit, e.g. the topic of peace.
Also, the importances of the topics relative to each other could be implausible, as it is hard to believe that the topic “war”, only made up for around 15% of the discourse during the second World War.
Nevertheless, seeded topic models are an exciting tool for creating measurements based on unstructured data (e.g. text). In the future, it will be important to incorporate more meta-data, and to improve the keyword seeded. In my case that could mean to include a discussants political affiliation in the model, or to tailor my keyword dictionary more precisely to the concept.
Seeded Topic Models as a Yard Stick: Implement them in R with keyATM was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/qwoFhzH
via RiYo Analytics







No comments