https://ift.tt/r3Kk45W Using custom metrics to detect problems Photo by Drago ș Grigore on Unsplash In this post, I will describe our...
Using custom metrics to detect problems

In this post, I will describe our experience in setting up monitoring for Spark applications. We will look at custom dashboards that display key metrics of Spark applications and help detect common problems encountered by developers. Also, we will talk in more detail about some of these problems.
Motivation and goals
It seems quite easy to control the performance of Spark applications if you do not have many of them. But complications may begin as your Spark workload increases significantly. For example, we at Joom have gradually come to the situation that we have over 1000 different Spark batch applications (almost all run daily or hourly) that are developed by a dozen teams. New Spark applications are added regularly, and not all of them may be well optimized. Also, the amount of processed data is constantly increasing. All this leads to a constant increase in the execution time and the cost of our computations. Thus, it became necessary to monitor the use of Spark in our company so that we would have a single tool to answer the following questions:
- How does our Spark workload change over time?
- How stable and optimized are our applications?
- Are there any common (and usually solvable) problems in our applications that make them much slower (and therefore more expensive) than we would like?
- How much does it all cost our company?
As a result, we have created a set of dashboards that display key metrics of our Spark applications and help detect some typical problems.
We use Spark 3 on Kubernetes/EKS, so some of the things described in this post are specific to this setup.
Collecting statistics
It all starts with collecting statistics. To have a complete picture of what is going on, we collect and store the following data:
- Standard Spark metrics you can see in Spark Web UI (e.g., Task Time, Shuffle, Input, Spill, Execution/Storage Memory Peak, Failure Reason, Executors Remove Reason, etc.). To collect these metrics, we use a custom SparkListener that listens to various events while a Spark application is running, extracts all the metrics we are interested in, and sends them to Kafka. Then, a special Spark application reads these metrics from Kafka, converts to a convenient format, and saves them as a set of Spark tables (spark_app_level_statistics, spark_stage_level_statistics, spark_executor_level_statistics).
- Metrics related to K8S Pods of Spark drivers and executors (parameters, lifetime). We use prometheus-community/kube-prometheus-stack.
- AWS billing data: cost of EC2 instances, EBS disks, data transfer.
- Information about the data queries we perform (table names, requested time periods, etc.).
Key application metrics
We use the Spark application execution statistics described above to build dashboards where each team can see the most significant information about their Spark applications. For example, here is a summary dashboard showing how the metrics change over time.
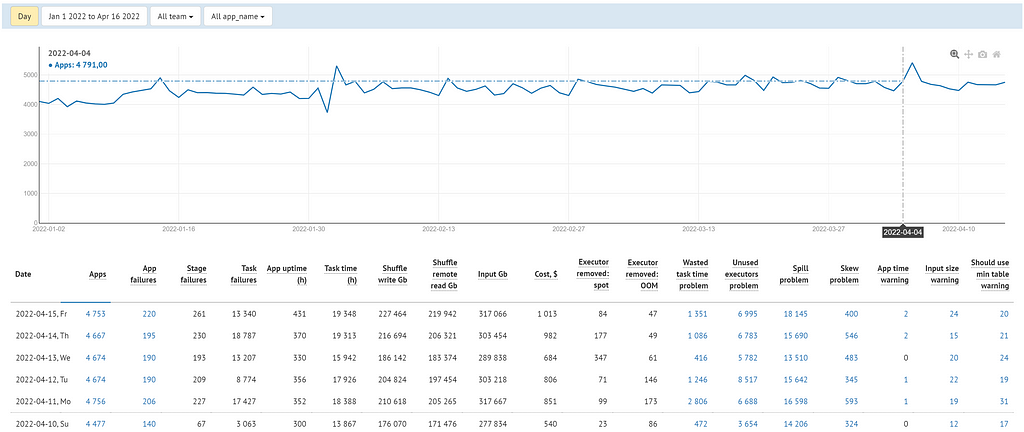
Some metrics are purely informational. They show how heavy each application is relative to the others. We also use them to understand how our Spark statistics, in general, and separately for each team (or application), change over time. These metrics slightly fluctuate in a normal situation and require attention only in case of unexpected large changes that may indicate improper Spark use.
These metrics include:
- Apps — the number of completed Spark applications.
- App uptime (h) — application running time. This metric may change from launch to launch, even if the application itself and the amount of data processed have not changed. For example, if during the next execution, the application does not get all the requested executors (there may be a shortage of AWS Spot instances), then this time, the application will take longer to complete. Therefore, it is not the best metric for evaluating changes in the efficiency of the application (e.g., in the case of its optimization), but this may be useful if you are interested in the dynamics of execution time.
- Task time (h) — the total execution time of all application tasks. In most cases, this metric is stable when using the same code, data, and execution environment. Therefore, it can usually be used to evaluate the effectiveness of application optimization.
- Shuffle write Gb — the total size of all written shuffle data.
- Shuffle read Gb — the total size of all read shuffle data.
- Input Gb — the sum of all data read from external sources (in our case, it is almost always S3).
- Executor removed: spot interruption — the number of lost executors while the application was running due to AWS reclaiming back Spot instances. We have almost no influence on this process. If you use Spot EC2 instances, you should be aware that AWS can take them away at any time, which will affect the execution time of the application. You may only optimize your AWS infrastructure to reduce the probability of such events.
Cost
Cost, $ — the cost of running the application. More precisely: how much money we spent on AWS resources on which the application was running (excluding the cost of data stored in S3). Sometimes it is very curious to find out how much money we spend on computing, both team-wide and for each individual application.
Calculation principle (simplified):
- For each Spark K8S Pod, we determine the EC2 instance on which it was running and calculate the full cost of this EC2 instance over its lifetime according to the AWS billing data: EC2 instance cost + EBS cost + AWSDataTransfer cost associated with the instance.
- Next, we determine how much the Pod used this instance:
> Time share = Pod running time / EC2 instance running time
> Capacity share — what share of the EC2 instance the Pod occupied (for example, our standard Spark executor Pod occupies 1/2 of a 4xlarge EC2 instance, 1/4 of an 8xlarge instance, etc.). - Pod cost = Full cost of the EC2 instance * Time share * Capacity share.
- And finally, the cost of an application is the cost of all its Pods.
Metrics describing problems
The metrics above give a general idea of how heavy our applications are but do not readily say if anything can be improved. To give users more direct help, we have added higher-level metrics that draw attention to common problems we encounter in practice.
Key features of such metrics:
- They only show problems that can be fixed (e.g., by setting more suitable Spark parameters or optimizing the code).
- Typically, each value of any such metric tells us the magnitude of the corresponding problem. This way, we can sort by it and see the most problematic applications that require attention first. This is also true when aggregating metric values by some dimensions (e.g., by date or team name).
- For any application, we show the value of any such metric greater than 0 only if the magnitude of the problem is worth attention. For example, a small Spill usually has no negative impact on the application, and we can ignore it. And in this case, we still show the corresponding metric as 0 to not bother anyone.
Below are some of these metrics.
Wasted Task Time problem
This metric shows the approximate Task Time which was wasted due to various kinds of failures in applications. For failed application runs, we consider all their total Task Time as wasted. For successfully completed applications, we consider as wasted the total time of all Failed Tasks, as well as the total Task Time of all retries of previously successfully completed Stages (or individual tasks), since such retries usually occur when it is necessary to re-process data previously owned by killed executors.
A few points why we are interested in this metric:
- This metric allows us to detect “hidden” problems in Spark applications. While an application is running, there may be failures of some stages or tasks that slow down this application, which could be avoided by using the correct settings or environment. But since the application may eventually complete successfully, your workflow management platform (e.g., Airflow) will not report any such problems affecting the efficiency of the application. In addition, the application may fail on the first try for some reasons, but if you use a retry policy, it may complete successfully on the following tries. In this case, such failures also often occur unnoticed.
- It is a quantitative metric that more clearly reports the severity of the problem with a particular application than just the number of failed apps/stages/tasks.
Here are some examples of common causes of Wasted Task Time, which may require the use of such metrics to detect problems:
- Loss of executors, which leads to the loss of already partially processed data, which in turn leads to their re-processing. The most common reason is the killing of executors because of Out of memory errors (OOM). There are two types of OOM:
> K8S container OOM: This is usually due to insufficient spark.executor.memoryOverhead for specific applications. In this case, we usually either reduce the size of partitions (by increasing spark.sql.shuffle.partitions) or increase memoryOverhead by reducing spark.executor.memory (the sum of memory + memoryOverhead remains constant, since it is limited by the amount of memory on used EC2 instances).
> Executor heap OOM: This is quite rare, and to solve it, you can try the following steps (considering that it is problematic to increase memory): reduce the size of partitions, reduce spark.memory.fraction, and after all, reduce the number of spark.executor.cores (i.e., the simultaneous number of tasks) per executor. - Running out of disk space on any EC2 instance due to using too much data.
- Random failures of some tasks. It usually happens because of temporary problems with access to external systems (Mongo, Cassandra, ClickHouse, etc.).
We pay special attention to the situation where we lose executors because AWS occasionally reclaims back Spot instances. This is not an application problem, and there is nothing we can do about it at the application level. Therefore, we do not increase the Wasted Task Time metric for applications with which this happened.
The dashboard also shows several additional metrics related to this problem, such as:
- App/Stage/Task failures — the number of failed applications/stages/tasks.
- Executor removed: OOM — the number of executors that were lost due to OOM.
Unused executors problem
This metric shows the difference between the theoretically maximum possible Total Task Time and the actual Total Task Time for any completed Spark application. The theoretically possible Total Task Time for an application we calculate as: <the total time spent by all its executors in the Running state> * spark.executor.cores.
The actual Total Task time is usually always less than theoretically possible, but if it is much smaller, then this is a sign that executors (or individual cores) are not used most of the time (but at the same time, they occupy space on EC2 instances). For each application, we show this metric being greater than 0 (and therefore requiring attention) only if the ActualTaskTime / MaxPossibleTaskTime ratio is less than a certain threshold.
There can be various situations that cause such irrational use of resources. Just a few examples:
- Executors can be idle due to long synchronous operations on the driver (e.g., when using a third-party API) or when using very little parallelism in some Stages. We use Spark dynamicAllocation, but by default, it doesn’t scale down the number of executors if these executors have cached data blocks or store shuffle data.
- Someone runs a large number of very short Jobs in a loop.
As practice shows, it is often possible to optimize such cases in one way or another. Also, you can always try to reduce the number of executors (spark.dynamicAllocation.maxExecutors option) because in some such cases, this significantly reduces the used resources while having almost no effect on the application’s running time.
Spill problem
This metric shows the total Spill (Disk) for any Spark application. The higher the value, the more serious the problem.
Spark performs various operations on data partitions (e.g., sorting when performing SortMergeJoin). If any partition is too big to be processed entirely in Execution Memory, then Spark spills part of the data to disk. Having any Spill is not good anyway, but a large Spill may lead to serious performance degradation (especially if you have run out of EC2 instances with SSD disks).
The main way to get rid of the Spill is to reduce the size of data partitions, which you can achieve by increasing the number of these partitions.
- If Spill occurs after Shuffle, then it is worth trying to increase the spark.sql.shuffle.partitions property for this application. In theory, you could try to set this property large enough and rely on AQE Dynamically coalescing shuffle partitions, but at the moment, this does not always work well, and you should be careful about setting it too high because it may also lead to performance degradation. It is also worth noting that the optimal number of partitions is relatively easy to calculate automatically individually for each application based on the statistics of past runs.
- If you use Spark tables already bucketed by the right columns, then Spark skips Shuffle, and in this case, Spill can occur right after reading data from the source. In this case, you should try to increase the number of buckets in the source table.
Skew problem
Skew is a situation when one or more partitions take significantly longer to process than all the others, thereby significantly increasing the total running time of an application. This usually occurs due to the uneven distribution of data across partitions. This metric contains the difference taskTimeMax — taskTime75Percentile (the sum over all stages), but currently, we take into account only those stages for which the condition (taskTimeMax — taskTime75Percentile) > 5 min AND taskTimeMax/taskTime75Percentile > 5 is satisfied. That is, as a noteworthy Skew Problem, we show only the most severe cases that can seriously affect the running time.
Starting from Spark 3, there is a Skew optimization feature, which dynamically handles Skew in SortMergeJoin. But at the moment, this optimization does not work in all our cases. And also, Skew may occur in other operations for which there is no such optimization (e.g., Window Functions, grouping). And in these cases, we still have to deal with Skew problems on our own. First of all, we look at what values in our data are the cause of it. For example, there may be many records with empty/unknown values in the join/grouping columns, which should have been discarded anyway. If we need all the data, we try to apply various code optimizations.
App time warning
This field contains the number of Spark applications that took too long to complete. The exact rule we use now: AppUptime > 4 hours OR TotalTaskTime > 500 hours.
Long-running applications do not necessarily need to be fixed because there may be no other options, but we pay attention to them in any case.
- If any such application fails (e.g., due to the Spot instances interruption), Airflow restarts the application, and a lot of work is done again. Therefore, it is desirable to divide such applications into several parts, if possible.
- The reason for the long execution may be various problems that other metrics do not always show.
Input size warning
This metric highlights Spark applications that read too much data. We take into account both the amount of data read from external sources (Input Gb metric), and the date ranges used in queries. It is only a warning because, in some cases, reading very large amounts of data is necessary. But at the same time, this metric may remind someone that sometimes there is no need to read long periods daily, and data processing can be incremental.
It is also worth noting that some of the problems described above can be partially solved without having to pay attention to every application. For example, we have implemented an automatic selection of optimal values for some Spark parameters (e.g., spark.sql.shuffle.partitions, spark.dynamicAllocation.maxExecutors, etc.) individually for each application based on the analysis of Spark statistics of previous runs. But this auto-selection can’t help in all cases, so the use of all the described metrics is still relevant for us.
Dashboards
Finally, a few words about some of the dashboards we use.
Apps performance — metrics in the time dimension. We use this to track changes in key metrics and display problems that have occurred in recent days. Typically our applications run daily, but we also have other schedule options: hourly, weekly, monthly, etc.
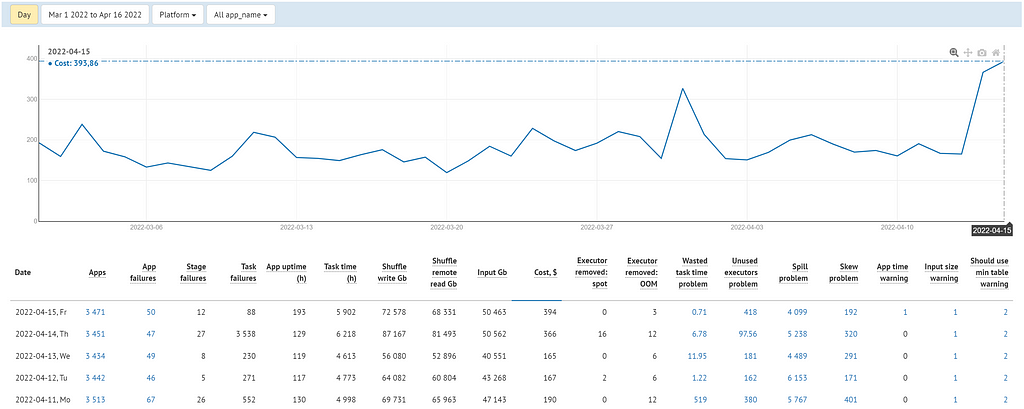
Here we can see the numerical and graphical representation of each metric. Filters by teams and by individual Spark applications are available. Clicking on the values in the columns opens a drill-down page with a list of completed Spark application runs.
Apps performance by name — metrics aggregated by application name.
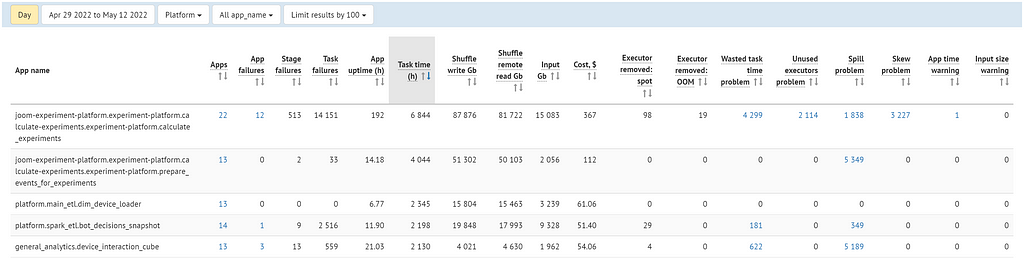
We mainly use this to find the most significant applications for a selected metric/problem, so we know what to focus on first.
Conclusion
In this post, we looked at some metrics and dashboards displaying them, which allow us to monitor the use of Spark in our company and detect various problems.
We plan to work on this topic further: add new metrics (of particular interest are some metrics based on the analysis of Spark application execution plans) and improve existing ones. And there are also plans to improve the usability of these tools. For example, we are thinking about using an anomaly detector. But these are topics for separate posts.
Monitoring of Spark Applications was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/Dtav7yd
via RiYo Analytics






No comments