https://ift.tt/G0B2Ddr Better late than never All modern businesses have digital aspects in today’s world. Perhaps a few small handicraft ...
Better late than never
All modern businesses have digital aspects in today’s world. Perhaps a few small handicraft businesses remain free from digital influence, but that’s the exception. Each organization progresses through several stages of digitalization — from basic accounting of cash flows to advanced analytics, predictive modelling and development of data-based digital services.
Today, let me share one of my client’s cases, where my team and I worked on the Data Lake implementation to enable automated analytics to help speed up the decision-making process.
Obviously, all of it starts from Excel workbooks. However, the number of data sources in an enterprise expands along with its growth. Usually, many business applications are in use, such as CRM, ERP, and WMS. However, a habit of making reports and analyzing data in Excel never dies away!
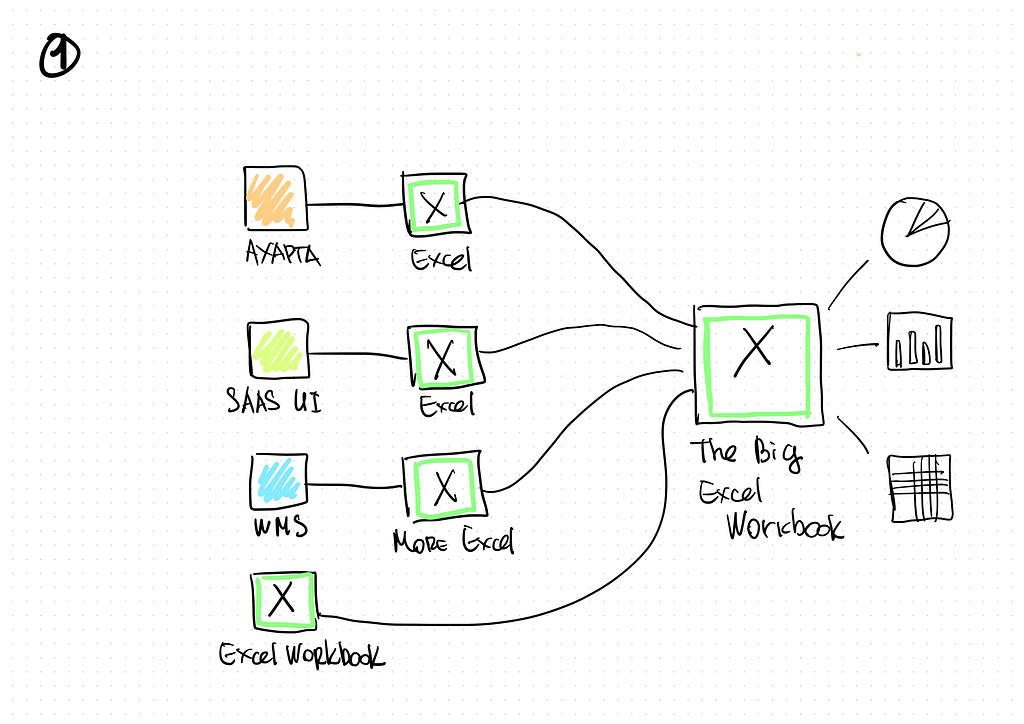
Sooner or later, it will lead to a situation when there are too many charts with data exported from an excessive number of systems. It takes time each day to manually prepare data for reports, and it can be challenging to pool information from different systems. It really becomes a nightmare if you ever need to update information for past periods. Finding a mistake would be virtually impossible if any were made manually processing data for reports and analytics. It might even be easier to start fresh!
In short, it is called “Excel Hell” :)
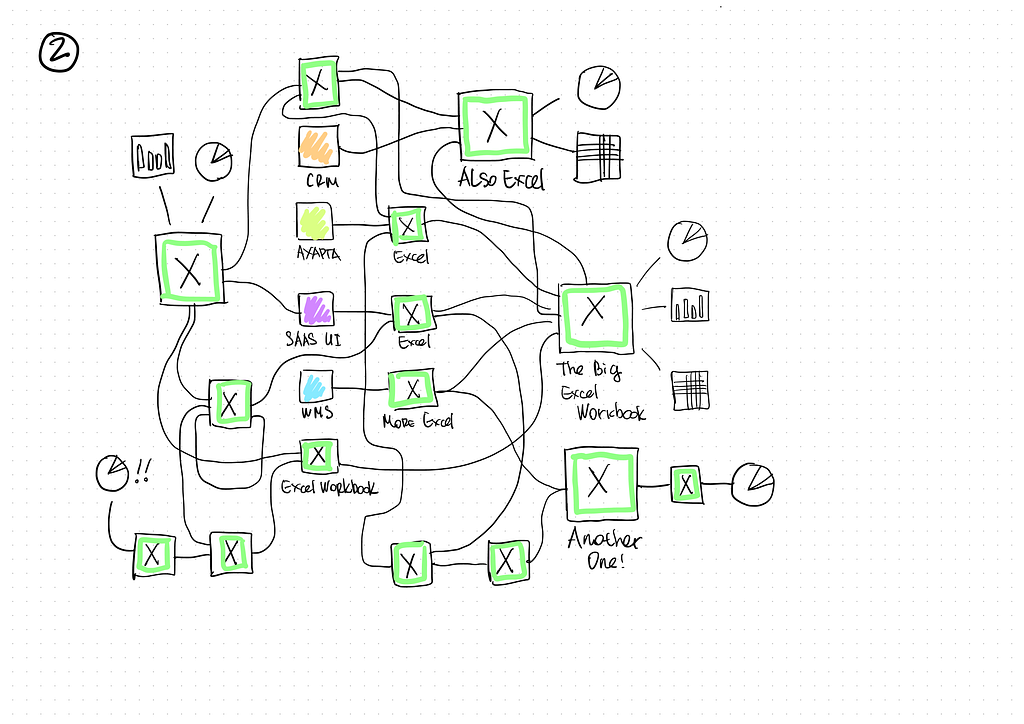
Fortunately, our client, a major dealer of heavy construction machinery and equipment, saw those tendencies before it was too late and asked us to help. The task was to rid their employees of manual data preparation and give them an option for versatile analysis of data from all systems without needing additional developers. If possible, we were also to provide a method for the company’s clients to access the data. Just in time!
Even Excel is Better Than Nothing
It seemed that we would have to automate parts of the data preparation processes and create the rest from scratch. That called for an analysis of the as-is state.
First, we interviewed all reporting system users and received examples of the reports. To our surprise, we found out that employees used parts of workbooks as a source for reports created in Power BI. They simply attached the manually prepared workbook as a source and visualized the data!
This is undoubtedly suboptimal as, in most cases, there is a possibility to connect to the business-system data directly and to place restrictions, add calculations, and links in the report editor proper. There is no use in blaming analysts for it, considering how simple Power BI is for operation.
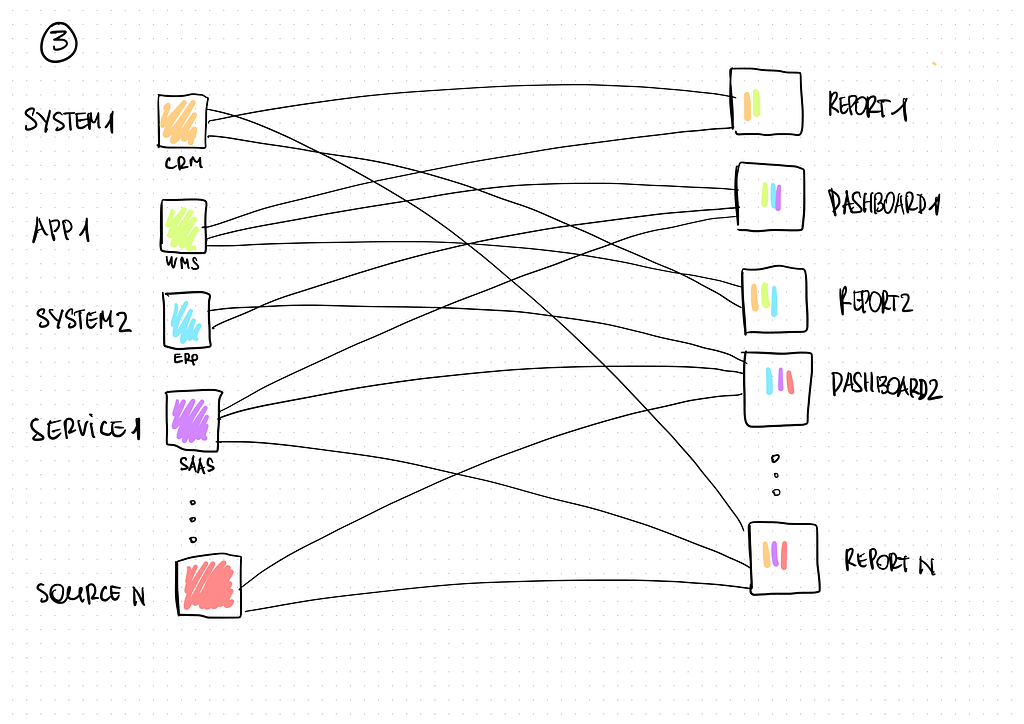
Having received an overview of the current reports, we compared them with their sources. It turned out that those were not just applications but also other Excel files — files containing planning data and reports from external cloud SaaS. Even exported PDF files with reports on movements of their own vehicle fleet from the GPS-tracking provider were used. Unexpectedly, we knew an approach to arrange a data collection process for such systems.
As a result, we had a sizable Excel file specifying all sources and their properties (access method, granularity, refresh rate, change history, etc.). These were actually metadata, and there is a unique software developed for this purpose — a data catalogue. However, to instill data culture in the business, we had to start small. The Excel file was the first step to the future catalogue.
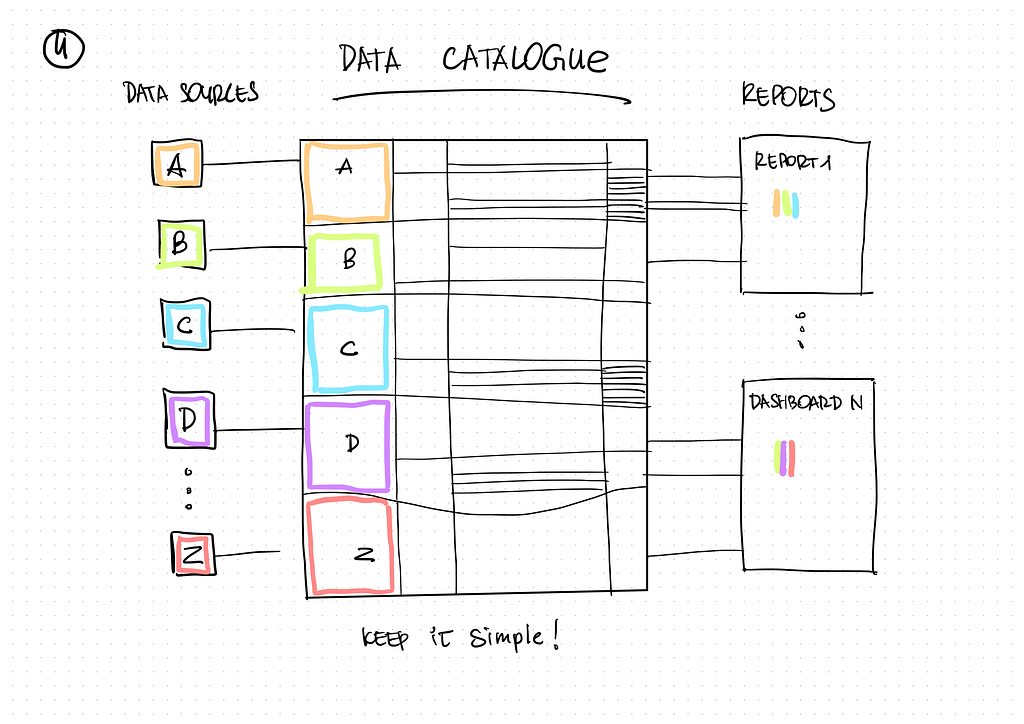
Architecture
So, all of this data had to be regularly extracted from their sources and kept updated. The data also had to be available to analysts at the most detailed level, never knowing in advance what kind of reports they would like to create or what kind of new metrics and properties of their business they would like to analyze.
With everything we had learned so far, we deliberately rejected the classical approach to developing an enterprise data warehouse. We chose not to create a unified data model with facts, measurements and pre-defined formulas for calculating showings. The most suitable architecture type was “Data Lake,” in this case.
Of course, data lake architecture also has its pros and cons, but we will talk about the applicability of this approach another time. Suffice it to say that the data are stored in the most detailed and “raw” form, and users can receive access to them or a prearranged data mart. It is possible to do without them, though sometimes it is worth using them to increase the response rate in reports in case of complex calculations.
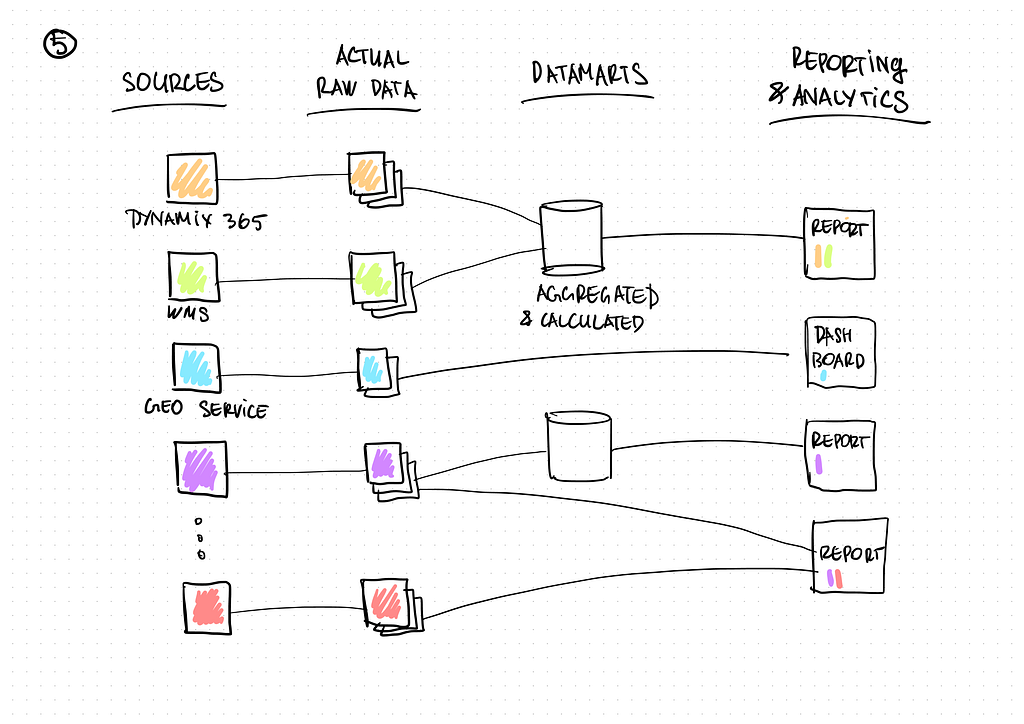
Data lake architecture can be realized with the help of various software, such as an open-source stack using Apache components. However, our client already had a subscription to Microsoft Azure and some parts of business applications were used via cloud services such as MS Dynamix 365. It should be noted that MS Azure has undergone some significant improvement over the past several years and now includes all necessary tools for developing enterprise analytical and Big Data systems. So, we decided to set up the system with MS Azure.
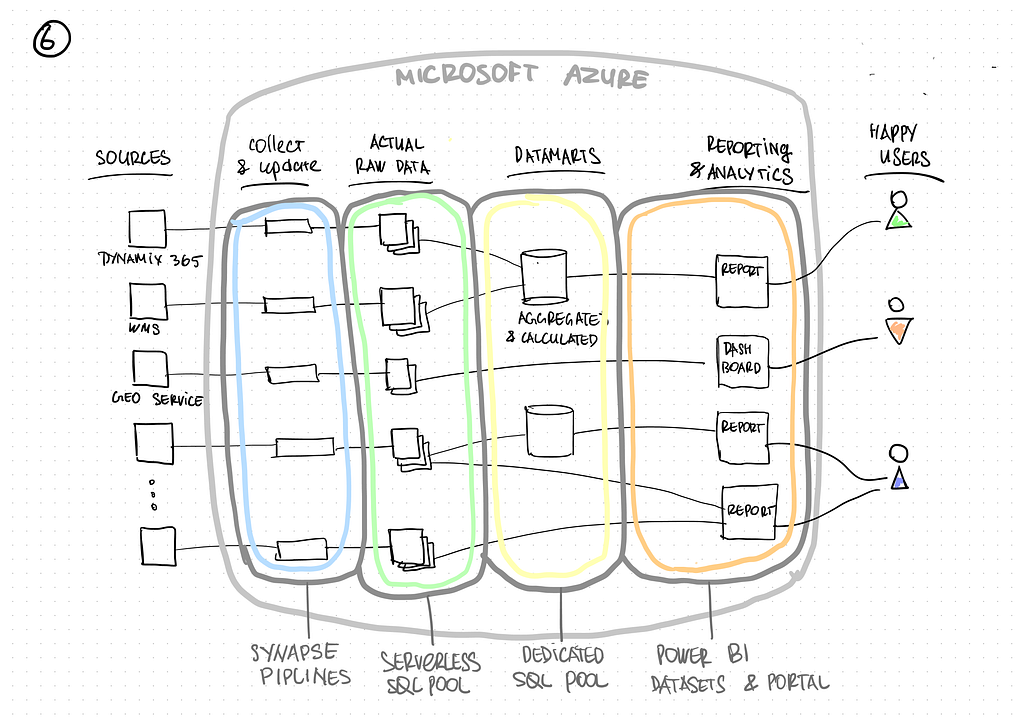
We used Serverless SQL Pool for storing detailed data, Dedicated SQL Pool for data marts, and Synapse Pipelines were utilized as a tool for extracting, transforming and loading the data (ETL). Power BI can connect to both data storage layers in data import mode and live query mode, meaning users are not limited in further data processing, for instance, by using DAX.
Eat the cake bit by bit
No one loves to compose long technical requirements. And, of course, everyone wants quick results!
So, after consulting with our client, we decided not to take the path of lengthy approvals and assignment reviews but to realize the project in short iterations using an Agile development style.
There are several ways to carry out a project of building a BI system in short sprints. You can begin by working on all data sources and add one new processing stage at every iteration. E.g., one sprint for initial loading into Operational Data Store, one for loading into Data Warehouse, and further sprints can be assigned to prepare reports in Data marts.
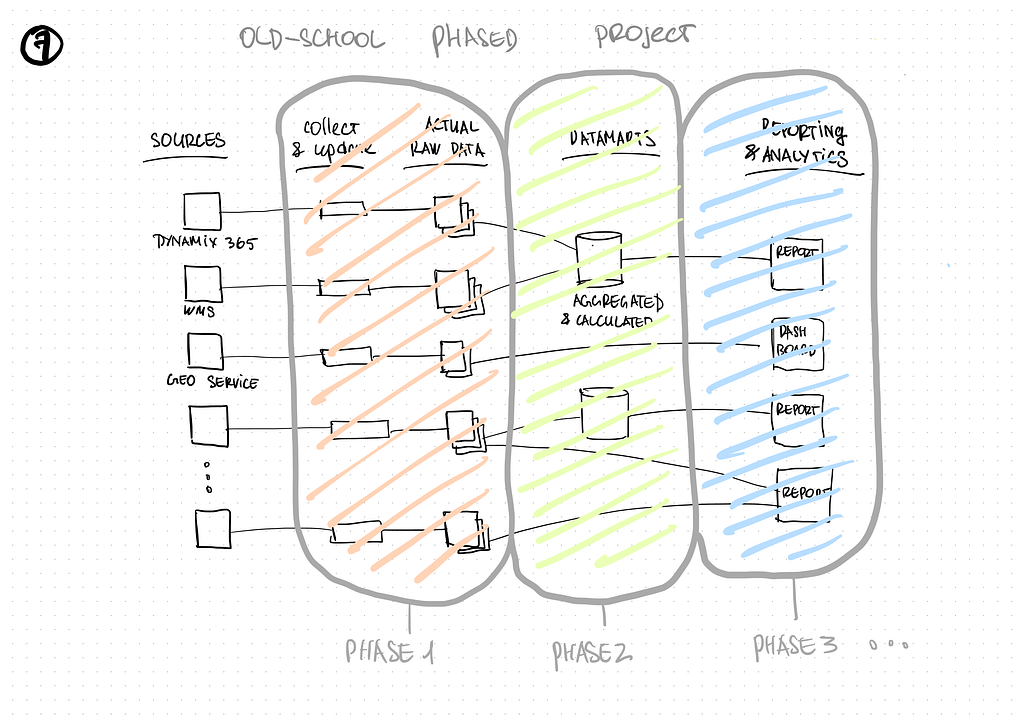
In our case, we used Data Lake architecture. There were actually only two layers but dozens of data sources. That meant that it was logical to separate the work into sprints, taking several sources into each sprint and carrying out the whole development process for them — from assembly to a ready-made data mart.
Besides, it is very convenient for users, as it is often the case that 2–3 sources comprise data for one report. Thus, the result of each iteration provides analysts with data with which they can transfer one or more existing reports to the data lake. This allows gradual change over to using a data warehouse and avoids distraction from their work caused by verifying large amounts of data for a short period of time!
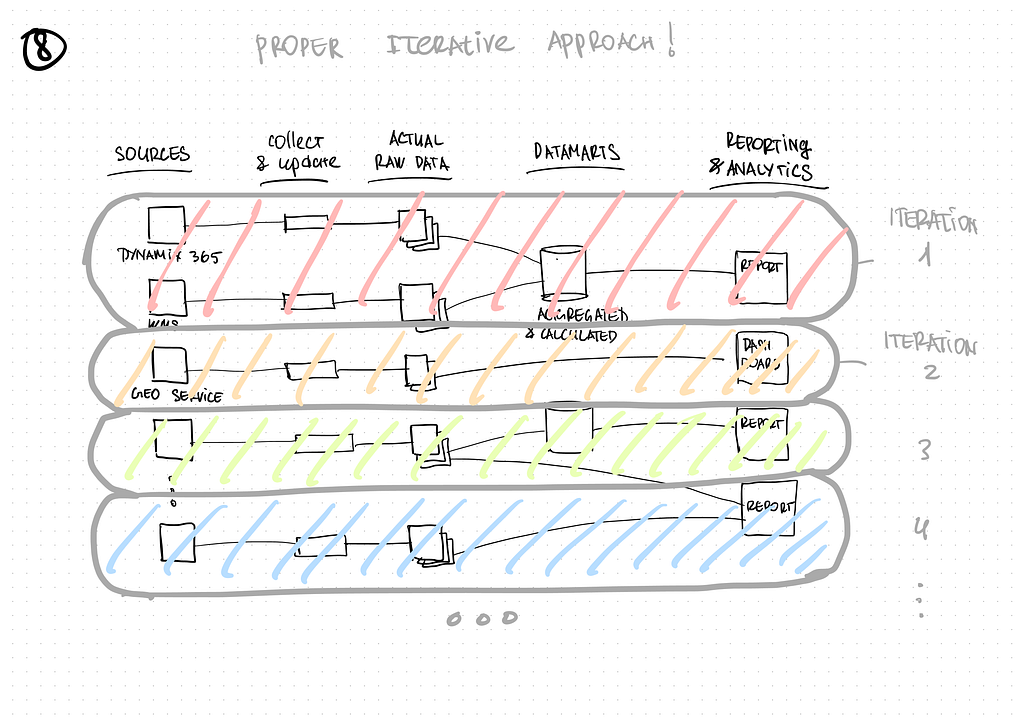
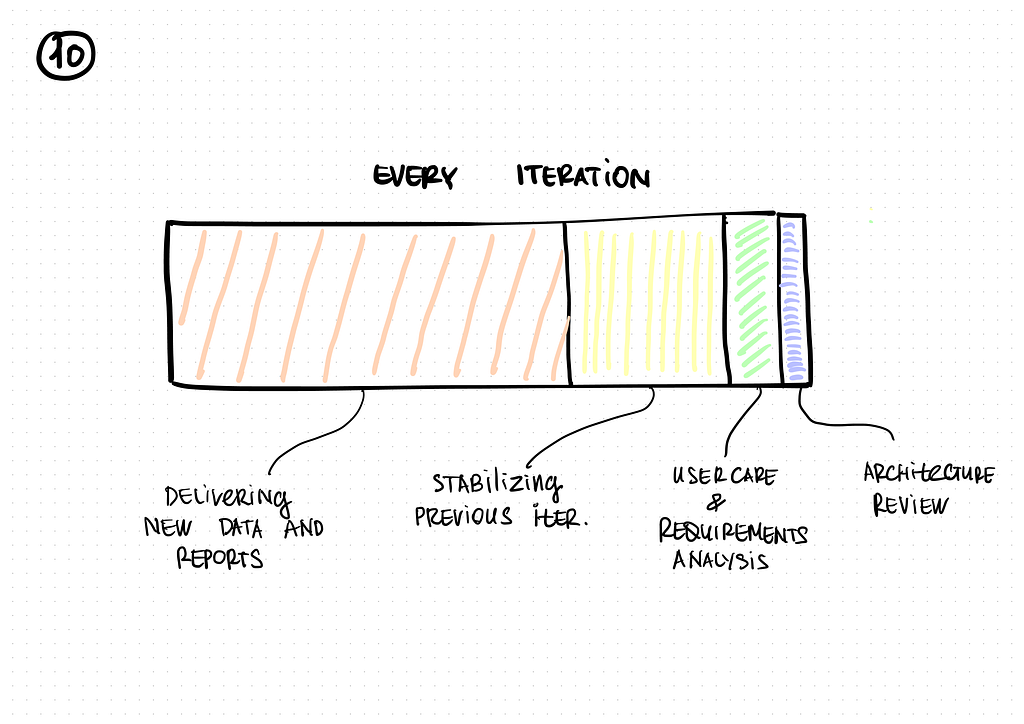
Finally, each iteration consisted of:
- developing an adapter for data extraction
- initial loading
- configuring the data update process
- calculating data marts
- verifying the data in data marts by users (analysts)
- switching the reports from Excel to Azure Synapse
In total, we have connected 37 data source systems! It is no use to list them all here, as each company will have unique systems. Suffice it to say that there were Excel charts, relational databases, external services with API and others.
Learning from mistakes
Naturally, no agile development process goes without mistakes, faults and stabilization. We chose deep analysis over immediate results.
It became clear that it would be a costly affair to place all the data from the data lake into a Dedicated SQL Pool. Also, all the pool itself did during the day was await new connections and respond to occasional user queries.
We suggested transferring Power BI reports into data import mode instead of direct query mode to save our client money. Pre-prepared data would then be stored in the Power BI data set, causing no consumption storage-wise and being available regardless of the pool availability.
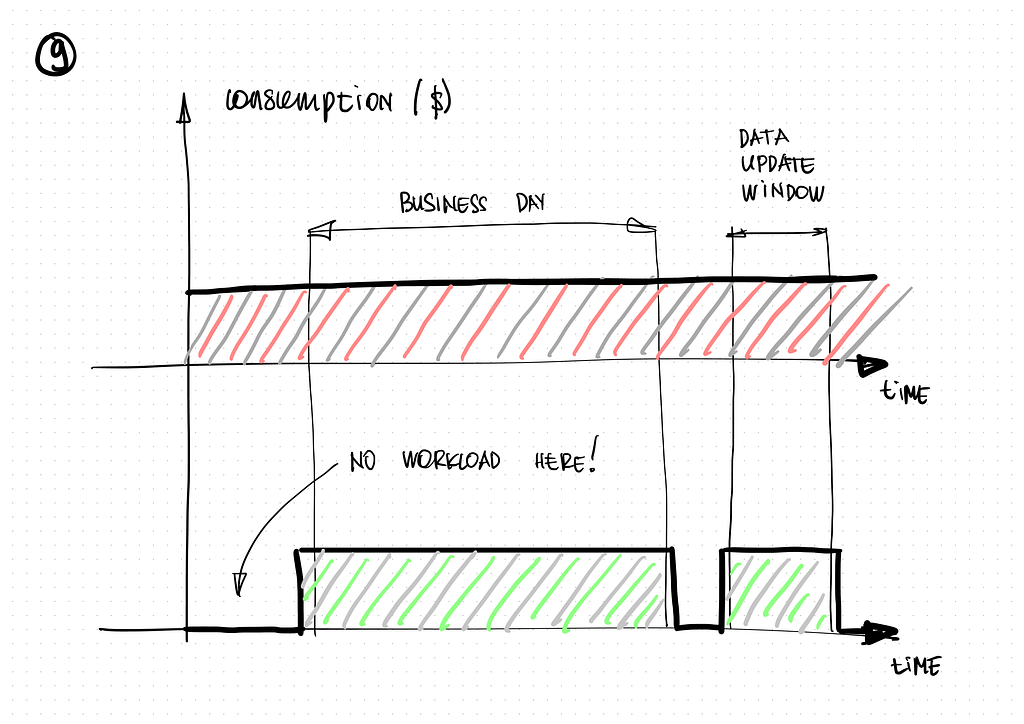
In addition to that, we configured settings to update data sets for all reports, including data refreshing (with the help of Synapse Pipelines). All that was left was to set Dedicated SQL service activation and deactivation on a schedule to update data and data sets. The service cost underwent an almost fourfold decrease!
The second fault was to work with an external SaaS intended for extracting data on movements of the company’s own vehicle fleet. As was often the case, the service provided data through an API in JSON. Except that the form of this JSON was not entirely canonical and did not contain a parent container necessary for logical iterative data processing. At insignificant volumes, it was not a problem. But as soon as our client requested loading detailed GPS coordinates for each trip, we understood that standard tools from Azure Pipelines could not be used for working with incorrectly formatted JSON. The workaround solution was a good old SQL and batch loading of JSON texts. It took us several hours of brainstorming to write a pretty complex script that quickly analyzed text responses from the service and transformed them into files at the Serverless data storage. Nobody promised it would be a no-code development! :)
One more problem we encountered was another external service. For some internal reason, it had revoked all authorization keys, and, of course, our ETL process started receiving error messages (HTTP 403 — Forbidden) instead of the usual data. It’s not a big deal, but considering the instability of some APIs, we followed common configuration practice — several repeated data requests at a minute interval. The number of retries was set to 30.
Unfortunately, the keys had been revoked just before the Christmas holidays, so the error reoccurred many times over the following few days. To our great surprise, we found out that the timeout before the next attempt to receive data was also chargeable according to the MS Azure tariff. Surely, it’s up to Microsoft to define which features are subject to billing and why, but from the client’s point of view (and we agree with it), there is no sense in paying for idle time. We had received a new authorization key, but immediately after, we set up a notification procedure for the development team and the client’s net administrators when a data request attempt failed three times. Better safe than sorry!
Conclusion
Let us return from the technical implementation details to the project goal and the tasks it’s intended for.
The most evident benefit of this system is the saving of staff-months or even staff-years of labor costs from manual data processing. Of course, it can cost a pretty penny for an enterprise, but the main benefit is something else.
It is a drastic decrease in time between a data analysis request from a proprietor or upper manager and when the analyst delivers the report. Now it has become possible to satisfy almost any requirement for analytics within one working day! It is difficult to underestimate the benefit of such acceleration for decision-making in a company.
Naturally, there are exceptions when there are not enough data in a data lake to respond to an analytical request or prepare a report. Fortunately, Power BI provides an opportunity to connect a new source directly to the report editor in a few clicks. Then, after making sure of its value, connecting this source to the data lake is considerably cheaper and faster than a classical BI system.
Thus, data lake analytical systems have become something of a new step in digitalization. Now analysts perform their duties by getting closer to the principle of self-service in their work, and upper management always has access to up-to-date information for quick and precise decision-making!
All images unless otherwise noted are by the author.
Data Lake Architecture: How To Level Up Your Business To The Data-Driven World was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/AnL1R9E
via RiYo Analytics






No comments