https://ift.tt/zDLX2qZ Discussing five subtle limitations of Pandas Photo by Georg Bommeli on Unsplash Thanks to the Pandas library,...
Discussing five subtle limitations of Pandas

Thanks to the Pandas library, handling, analyzing, and processing tabular data in Python has never been as effortless and straightforward as it is today.
Contemporarily, the Pandas API provides an extensive collection of functionalities to manage tabular data, intending to serve almost every data science project, such as:
- Input and Output operations
- Data Filtering
- Table Joins
- Data visualization
- Duplicate data handling, and many more, which you can read here.
While Pandas is indeed the go-to tool for almost all data scientists working with tabular data, leveraging it in my projects has made me realize some of its major caveats/limitations, which I wish to discuss in this post.
Therefore, this post presents five things I wish Pandas was capable of doing in the realm of real-world tabular datasets.
The highlight of this article is as follows:
#1 I wish Pandas could read a CSV file parallelly
#2 I wish Pandas could read multiple CSV files at once
#3 I wish Pandas DataFrames utilized less memory
#4 I wish Pandas could be used for large datasets
#5 I wish Pandas supported conditional joins like SQL (somehow)
Let’s begin 🚀!
#1 I wish Pandas could read a CSV file parallelly
Unfortunately, the input-output operations with Pandas from/to a CSV file are serialized, meaning there’s no inherent multi-threading support available in Pandas.
For starters, serialization in the context of reading CSV files means that Pandas reads data only one row (or line) of a CSV at a time. This is illustrated in the animation below:
Similar to the input operation, the output operation is no better. Pandas stores a DataFrame to a CSV file in a serialized fashion as well.
The process of serialized input and output operations makes it incredibly inefficient and time-consuming.
Possible Alternative(s)
As per my exploration, there are two potential solutions one may take to improve the overall input-output run-time.
- Prefer using other file formats like Pickle, Parquet, and Feather to read from and store DataFrames to.
In addition to being fast, these formats also consume lesser memory on disk to store the data. Read more about these file formats in my blog below:
Why I Stopped Dumping DataFrames to a CSV and Why You Should Too
- Use libraries like DataTable, which, unlike Pandas, possess parallelization capabilities.
Read more about DataTable in my blog below:
It’s Time to Say GoodBye to pd.read_csv() and pd.to_csv()
#2 I wish Pandas could read multiple CSV files at once
Imagine you have a folder with multiple CSV files which you need to read and import as a Pandas DataFrame.
The one and the only way to achieve this in Pandas is by iterating over the list of files and reading them one after the other, as shown below:
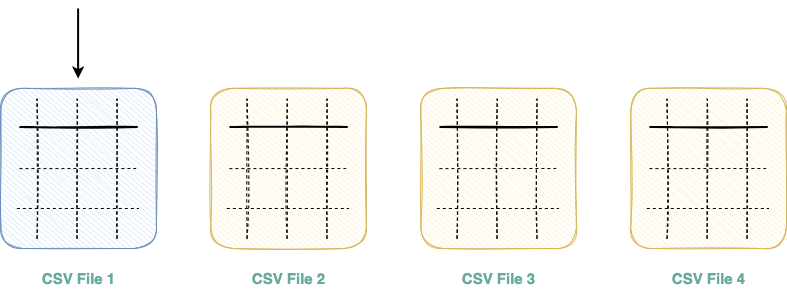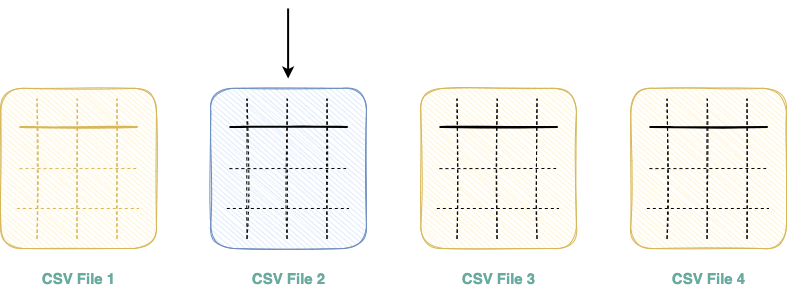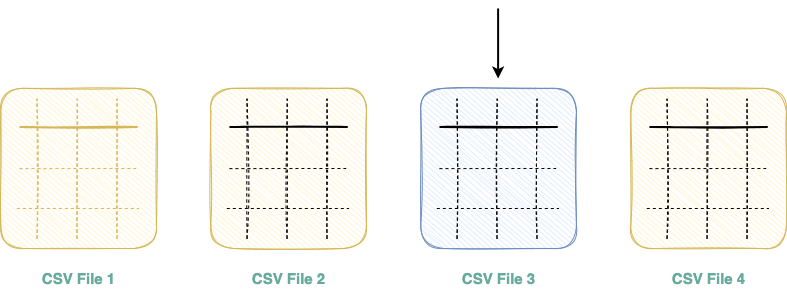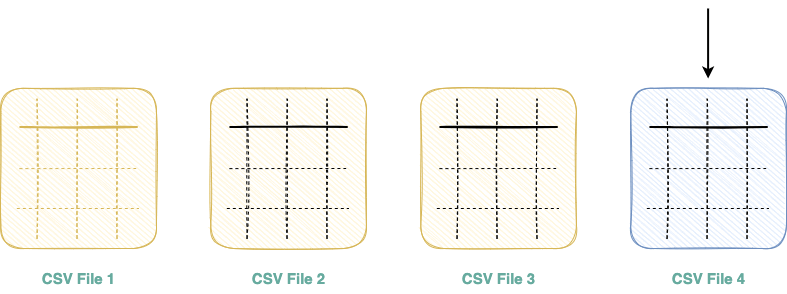
The above illustration can be programmatically demonstrated as follows:
Due to the absence of multi-threading support in Pandas, a set of files that could be potentially read in parallel should be read one by one, resulting in increased run-time and resource underutilization.
Possible Alternative(s)
The DataTable library again stands as a great alternative to Pandas to address this limitation.
With DataTable, you can read multiple CSV files efficiently. This is demonstrated below:
Read more about the run-time performance in my blog below:
How To Read Multiple CSV Files Non-Iteratively (and Without Pandas)
#3 I wish Pandas DataFrames utilized less memory
Pandas DataFrames are incredibly bulky and memory-inefficient to work with. For instance, consider that we create a DataFrame comprising of two columns as shown below:
Next, let’s determine the datatypes assigned by Pandas to the two columns of the above DataFrame df using the dtypes attribute:
By default, Pandas always assigns the highest memory datatype to columns. For instance, once Pandas interpreted colA above as an integer-valued, there were four possible sub-categories (signed) to choose from:
- int8: 8-bit-integer datatype spanning integers from [-2⁷, 2⁷].
- int16: 16-bit-integer datatype spanning integers from [-2¹⁵, 2¹⁵].
- int32: 32-bit-integer datatype spanning integers from [-2³¹, 2³¹].
- int64: 64-bit-integer datatype spanning integers from [-2⁶³, 2⁶³].
However, Pandas assigned int64 as the datatype of the integer-valued column, irrespective of the range of current values in the column. We notice a similar datatype behavior with colB.
Possible Alternative(s)
To optimize memory utilization, there is one direction that you can possibly explore, which I call the min-max-reduce analysis.
The first step is to find the minimum and maximum values in the column of interest.
The final step is to abridge (reduce) the column's datatype.
As the current range of values can be squeezed into the int16 datatype (because -2¹⁵< 10000 (min)< 30000 (max) <2¹⁵), we will transform the datatype from int64 to int16 using the astype() method as demonstrated below:
The total memory utilized by the colA column dropped by approximately 40% with this simple one-line datatype transformation.
With a similar min-max-reduce analysis, you can also alter the datatype of other integer and float valued columns.
Read more about the memory optimization techniques in my blog below:
Seven Killer Memory Optimization Techniques Every Pandas User Should Know
#4 I wish Pandas could be used for large datasets
As discussed above, there is no inherent multi-threading support available in Pandas. As a result, irrespective of the scale of the data, Pandas will always stick to a single core utilization — leading to increased run-time, which is proportional to the size of the data.

For instance, consider an experiment to study the correlation between DataFrame size and the run-time to execute a function on the DataFrame.
We start with a random DataFrame comprising a thousand rows and two columns.
Next, we define a function that takes a row of the DataFrame and returns its sum. This function is implemented below:
At every iteration, we determine the time to compute the sum of every row of the DataFrame. To eliminate randomness, we shall repeat each iteration runs times. At the end of each iteration, we shall increase the size of the DataFrame two folds.
The experiment is implemented below:
The plot below depicts the iteration vs run-time graph. With each iteration, the size of the DataFrame doubles, and so does the Pandas run-time — indicating that the Pandas’ run-time is always proportional to the size of the DataFrame and it never adopts parallelization.
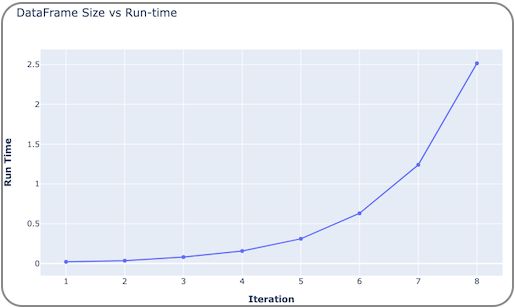
Possible Alternative(s)
Pandas is extremely good to work with on small datasets. However, as the scale of the data and the complexity of the pipeline increases, you as a Data Scientist should refrain from leveraging it due to its profound run-time caveats discussed above.
If your objective is to take the project to production, PySpark is the ideal way to proceed. Other alternatives include Terality, Vaex, DataTable, and Dask — recommended mostly for local computation over Pandas on large datasets.
#5 I wish Pandas supported conditional joins like SQL (somehow)
People working with SQL relish the freedom of writing complex join conditions to merge tables, don’t they?
As the name suggests, conditional joins go beyond the simple equality-based merge conditions. In other words, you can establish joins based on conditions other than equality between fields from multiple tables.
For instance, consider you have two tables, table1 and table2:
The objective is to join these tables based on the following condition
(table1.col1 = table2.col1 + 2) and (table2.col2 >= table2.col2 - 2) and (table2.col2 <= table2.col2 + 2)
SQL Join
The above conditional join is extremely simple to work with in SQL. The SQL query is implemented below, generating the output following the query:
Pandas Join
Pandas can only perform equality-based joins on DataFrames. In other words, the Pandas merge() method will join two records only when the values in the join column are identical — eliminating the scope of conditional joins.
Therefore, a few ways to perform conditional join using the Pandas’ merge() method are:
- Create the join column using operations defined in the join condition and execute the merge on the new column.
- Perform a cross join and filter the DataFrame. This can be extremely challenging in the case of large datasets.
A mix of Approach 1 and Approach 2 is demonstrated below.
First, we create two DataFrames to merge and define the join condition.
(table1.col1 = table2.col3 + 2) and (table2.col2 >= table2.col4 - 2) and (table2.col2 <= table2.col4 + 2)
As the join condition consists of inequalities, let’s keep them aside for a while and perform a join first on equalities (table1.col1 = table2.col3 + 2). After that, we’ll filter the results to incorporate the next two conditions.
First, we shall create a new column in table2. Let’s call it col3_1.
Next, we will perform the join on col1 from table1 and col3_1 from table2, and then filter the obtained records based on the leftover conditions from the join condition. This is implemented below:
Possible Alternative(s)
PandaSQL is a popular python package that provides a blend of both Pandas and SQL, allowing you to leverage the power of SQL syntax in a pythonic environment.
As a result, PandaSQL empowers you to query pandas DataFrames using SQL syntax. To execute SQL-like joins, you can explore PandaSQL.
However, the ease of using SQL with Pandas DataFrames comes at the cost of the run-time. I have discussed this in my previous blog post below:
Introduction to PandaSQL: The Downsides No One Talks About
Conclusion
To conclude, in this post, I discussed five major limitations of Pandas and their workarounds if you are stuck in any of these situations.
Pandas is incredible to work with day-to-day tabular data analysis, management, and processing.
However, suppose you are moving towards developing a production-level solution or having large amounts of data to deal with. In that case, Pandas won’t be of much help to you due to its no parallelization and resource underutilization limitations.
Thanks for reading!

✉️ Sign-up to my Email list to never miss another article on data science guides, tricks and tips, Machine Learning, SQL, Python, and more. Medium will deliver my next articles right to your inbox.
5 Things I Wish the Pandas Library Could Do was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/POUEdi8
via RiYo Analytics







ليست هناك تعليقات