https://ift.tt/BlvIiR5 Collecting, storing, and processing customer event data involves unique technical challenges. It’s high volume, nois...
Collecting, storing, and processing customer event data involves unique technical challenges. It’s high volume, noisy, and it constantly changes. In the past, these challenges led many companies to rely on third-party black-box SaaS solutions for managing their customer data. But this approach taught many companies a hard lesson: black boxes create more problems than they solve including data silos, rigid data models, and lack of integration to the additional tooling needed for analytics. The good news is that the pain from black box solutions ushered in today’s engineering-driven era where companies prioritize centralizing data in a single, open storage layer at the center of their data stack.
Because of the characteristics of customer data mentioned above, the flexibility of the data lakehouse makes it an ideal architecture for centralizing customer data. It brings the critical data management features of a data warehouse together with the openness and scalability of a data lake, making it an ideal storage and processing layer for your customer data stack. You can read more on how the data lakehouse enhances the customer data stack here.
Why use Delta Lake as the foundation of your lakehouse
Delta Lake is an open source project that serves as the foundation of a cost-effective, highly scalable lakehouse architecture. It’s built on top of your existing data lake–whether that be Amazon S3, Google Cloud Storage, or Azure Blob Storage. This secure data storage and management layer for your data lake supports ACID transactions and schema enforcement, delivering reliability to data. Delta Lake eliminates data silos by providing a single home for all data types, making analytics simple and accessible across the enterprise and data lifecycle.
What you can do with customer data in the lakehouse
With RudderStack moving data into and out of your lakehouse, and Delta Lake serving as your centralized storage and processing layer, what you can do with your customer data is essentially limitless.
- Store everything – store your structured, semi-structured, and unstructured data all in one place
- Scale efficiently – with the inexpensive storage afforded by a cloud data lake and the power of Apache Spark, your ability to scale is essentially infinite
- Meet regulatory needs – data privacy features from RudderStack and fine-grained access controls from Databricks allow you to build your customer data infrastructure with privacy in mind from end-to-end
- Drive deeper insights – Databricks SQL enables analysts and data scientists to reliably perform SQL queries and BI directly on the freshest and most complete data
- Get more predictive – Databricks provides all the tools necessary to do ML/AI on your data to enable new use cases and predict customer behavior
- Activate data with Reverse ETL – with RudderStack Reverse ETL, you can sync data from your lakehouse to your operational tools, so every team can act on insights
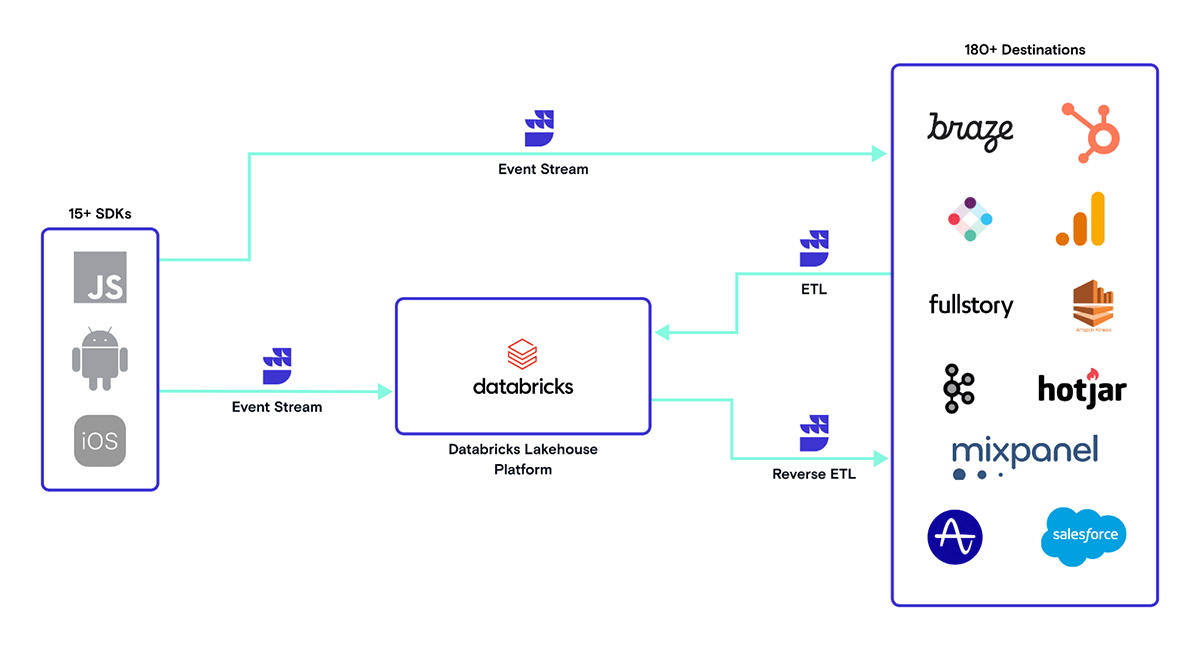
Rudderstack simplifying ingest of event data into the Databricks Lakehouse and activating insights with Reverse ETL
How to get your event data into Databricks lakehouse
How do you take unstructured events and deliver them in the right format, like Delta, in your data lakehouse? You could build a connector or use RudderStack’s Databricks Integration to save you the trouble. RudderStack’s integration takes care of all the complex integration work:
Converting your events
RudderStack builds size/time-bound batches of events converted from JSON to columnar format, according to our predefined schema, as they come in. These staging files are delivered to user-defined object storage.
Creating and delivering load files
Once the staging files are delivered, RudderStack regroups them by event name and loads them into their respective tables at a user chosen frequency–from every 30 minutes up to 24 hours. These “load files” are delivered to the same user-defined object storage.
Loading data to Delta Lake
Once the load files are ready, our Databricks integration loads the data from the generated files into Delta Lake.
Handling schema changes
RudderStack handles schema changes automatically, such as the creation of required tables or the addition of columns. While RudderStack does this for ease of use, it does honor user set schemas when loading the data. In the case of data type mismatches, the data would still be delivered for the user to backfill after a cleanup activity.
Getting started with RudderStack and Databricks
If you want to get value out of the customer event data in your data lakehouse more easily, and you don’t want to worry about building event ingestion infrastructure, you can sign up for RudderStack to test drive the Databricks integration today. Simply set up your data sources, configure Delta Lake as a destination, and start sending data.
Setting up the integration is straightforward and follows a few key steps:
- Obtain the necessary config requirements from the Databricks portal
- Provide RudderStack & Databricks access to your Staging Bucket
- Set up your data sources & Delta Lake destination in RudderStack
Rudderstack : Getting event data into the Databricks Lakehouse
Refer to RudderStack’s documentation for a detailed step-by-step guide on sending event data from RudderStack to Delta Lake.
--
Try Databricks for free. Get started today.
The post Sync Your Customer Data to the Databricks Lakehouse Platform With RudderStack appeared first on Databricks.
from Databricks https://ift.tt/8qlR90S
via RiYo Analytics








No comments