https://ift.tt/alzXUZe Everybody loves SMOTE, but is it really a silver bullet? Photo by eberhard 🖐 grossgasteiger on Unsplash When ...
Everybody loves SMOTE, but is it really a silver bullet?

When the topic of imbalanced classification comes up, many people praise SMOTE as the go-to approach. And indeed, popular algorithms have survived some evolutionary selection process by the community. However, we should still not just blindly throw canned solutions at our problems. To prove this point, we can construct actual toy examples that make SMOTE fail miserably. Before we do that, let us do a brief recap on the imbalance problem and the algorithm itself.
How SMOTE intends to solve the problem of imbalanced classification
The narrative of imbalanced data in large parts of the data science of community is as follows:
If one or many classes are heavily underrepresented in your dataset, classification algorithms will often not recognize these classes after training. To solve this problem, we use some resampling technique that creates a new dataset where all classes are roughly equally present. The SMOTE algorithm is one of those re-sampling techniques that has stood the test of time so far.
In summary, SMOTE oversamples the underrepresented classes by randomly creating synthetic observations in the domain gaps of the minorities. Consider a 1D example, where your minority class instances are all located in the interval [0,1]. SMOTE now creates more minority instances in this interval by randomly interpolating two existing datapoints.
I won’t go into further details here, but recommend reading the original paper if you want to learn more. As a side-fact worth mentioning, the original SMOTE algorithm will not work if your input data is not continuous. Consider one-hot encoded data — the random interpolation step will create non-binary synthetic data which is clearly wrong. Luckily, the imbalanced-learn library contains a suitable alternative for that case.
Creating a simple example where things go up in SMOTE
We can easily construct a counter-example of the usefulness of SMOTE. Consider the following data-generating process:
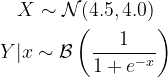
The original data — where everything looks good
A Logistic Regression model should easily learn the conditional class-distribution. Due to the shift of the input variable, X, we can expect that the class y=0 to be underrepresented. Let us plot this example in Python:
As we can see, the Logistic Regression model was able to learn the underlying class probabilities quite well.
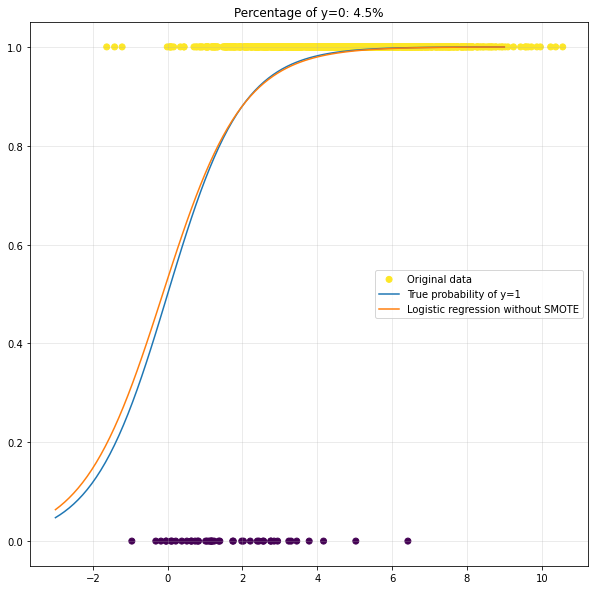
Making things worse with oversampling
Now, suppose that you were unable to inspect the data as nicely as we could in this example. You might only see that your dataset is imbalanced and quickly start implementing a SMOTE solution.
Let us plot the result of this approach for the example above:
After applying SMOTE, the performance of our model decreased significantly. This is bad, given the fact that SMOTE is the praised go-to solution for imbalanced data.
What went wrong?
The construction of the above example easily points us to the underlying issue:
SMOTE implicitly assumes that the class distribution is sufficiently homogenous in some neighbourhood around the minority class instances.
In plain English: If the data generating process frequently ‘jumps’ between classes in your input domain, you’re gonna have a bad time.
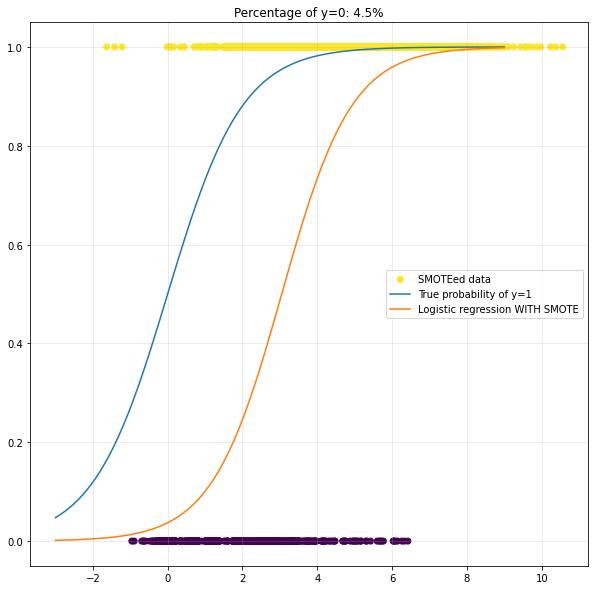
We can verify the claim with yet another plot:
In this example, less than five datapoints occur in each “minority-bin”. Since SMOTE (default settings) interpolates amongst the five nearest neighbours of each minority point, the algorithm will combine samples from distant clusters. This clearly breaks the pattern in this toy example.
Once the minority clusters are larger than the number of neighbours in the knn-step, things look reasonable again:
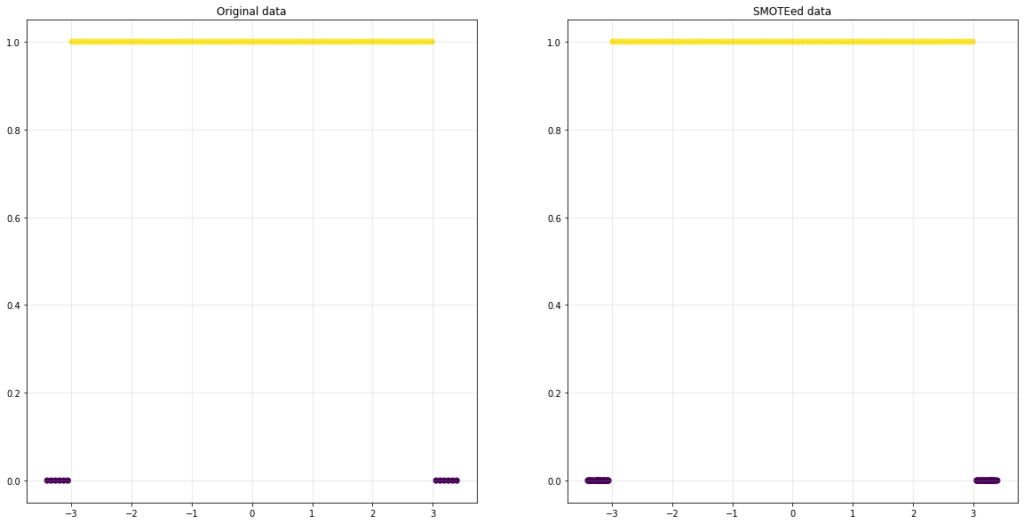
Is it doomed to fail in general?
As always, we should not draw conclusions about an algorithm’s usefulness based on a single toy example. Like with other methods, the usefulness of SMOTE will largely depend on the problem at hand. After all, the original paper dates back to 2002, so the algorithm has definitely stood the test of time so far.
However, you should always keep in mind that each Data Science problem is different and even the most praised algorithm might fail for your task. On the other hand, this paper provides some helpful rules of thumb about when you should use SMOTE and when you should not.
Another example, for which I unfortunately only have empirical evidence at this point, are differentiable classifiers for hard class boundaries. The SMOTEed data appears to ‘harden’ and improve the class boundary of a Logistic Regression model for another toy classification problem:
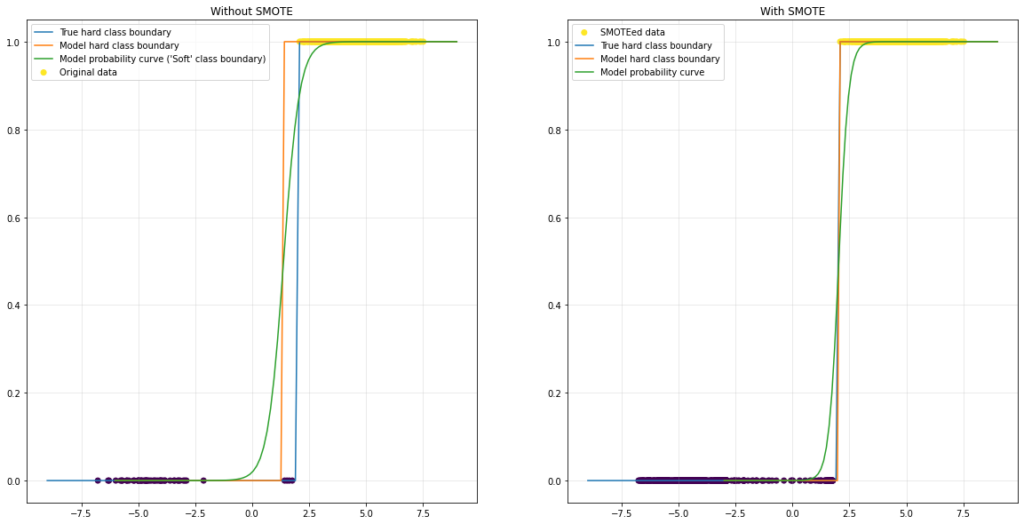
This indicates that SMOTE might be particularly useful for imbalanced image classification. For image data, we can expect low noise in general. For example, chances are quite low that an unambiguous image of a dog actually shows a cat. Also, except for some potential border-cases and -races, dogs and cats are easily distinguished based on their appearance. This implies fairly hard class boundaries as explained before.
For tabular data, we should expect label noise to be much more prevalent. Consider the infamous credit card fraud detection problem where fraudulent transactions typically make up the minority class. While an unusually high withdrawal in a remote country is more likely to be fraudulent, there is still considerably high chance that is alright anyway.
What should I do if SMOTE doesn’t work?
To summarize the above sections — SMOTE can work, but there is no guarantee. If SMOTE is failing you and you have verified that your code itself is sound, I would recommend the following steps:
- Grid-search through as many SMOTE hyper-parameters as possible — If you have enough resources and data available, you should try an exhaustive search for the best SMOTE hyper-parameters if you haven’t done so already.
- Try another re-sampling algorithm for imbalanced data — The imbalanced-learn package in Python offers many more re-sampling methods. Try them out with yet another round of hyper-parameter optimization.
- Adjust the decision boundaries for your classifier — This one is a little tricky to explain in only a few words. I will probably explain this in a future article in more detail. For now, I recommend this and this for an explanation.
- Dig deeper into research on imbalanced classification — A quick Google Scholar research gives you around 25,000 articles about resampling for imbalanced classification problems. Chances are quite high that you can find something that suits your problem at hand.
Conclusion
Hopefully, this brief article could convince you to not blindly jump aboard a Data Science hype-train. While SMOTE and re-sampling in general definitely have their place in the toolkit, they are no magical silver bullets.
Apparently, “SMOTE” and “re-sampling” are even the expected standard answers to imbalanced data during job interviews. I personally deem this to be quite questionable practice. In fact, this practice further spreads the erroneous conception about SMOTE’s universal applicability. Hopefully, this article could convince you otherwise.
Also, this marks yet another example of why a deeper understanding of an algorithm is useful and can help with debugging. After all, you do need (at least some) math for machine learning 🙂
References
[1] Chawla, Nitesh V., et al. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research 16, 2002.
[2] Elor, Yotam; Averbuch-Elor, Hadar. To SMOTE, or not to SMOTE?. arXiv preprint arXiv:2201.08528, 2022.
Originally published at https://sarem-seitz.com on June 13, 2022.
Why SMOTE is not necessarily the answer to your imbalanced dataset was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/mY5N612
via RiYo Analytics








No comments