https://ift.tt/HWpTPtg Introduction and solution to Feynman’s Restaurant Problem from a RecSys perspective Photo by shawnanggg on Unspl...
Introduction and solution to Feynman’s Restaurant Problem from a RecSys perspective

You’re on holiday, and you’re going to spend the following days on a remote island in the Pacific. There are several restaurants and you would like to enjoy the most the local cuisine. The problem you face is that a priori you don’t know which restaurants are you going to enjoy and which not, and you can’t find the restaurants on Yelp, so you can’t use others' opinions to decide which restaurants to visit. Also, the number of restaurants is bigger than the number of days you’re going to stay on the island, so you can’t try all the restaurants and find the best one. However, since you love math you decide to find the best strategy to optimize your experience during your holidays. This is known as the Feynman’s Restaurant Problem.
This same problem can be interpreted from the perspective of the restaurant, where cookers want to recommend dishes to clients but they don’t know which dishes are the clients going to enjoy or not. So this problem falls under the category of recommender systems. More generically, this is the problem of recommending M items (with repetition) from a set of N items with an unknown rating.
The content of this post is heavily inspired by this solution. I have tried to explain some details which were obscure to me, and I also added some plots and code to give more intuition about the problem. Here you can read more about the history of the problem.
Mathematical formulation
Let’s try to formalize the problem using maths. First of all, let’s define D as the number of days you’re going to spend in the city and N as the number of restaurants. Let’s assume that you can rank all the restaurants with respect to your taste, and let’s call r_i the ranking of restaurant i. Let’s assume also that you can go to the same restaurant every day without getting tired of it, which means that if you know the best restaurant in the city you are going to go there always.
Notice, that since D<N you can’t try all the restaurants in the city, so you’ll never know if you have visited the best restaurant.
Notice that you will never know the actual rating ri. You only know if a restaurant is the best up to that moment or not. You can rank the restaurant that you have tried up to a given moment, but this “partial” ranking maybe it’s not the same as the “absolute” ranking. For example, if you have only tried 4 out of 10 restaurants you could have the rank [3, 2, 1, 4, ?, ?, ?, ?, ?, ?], but the real rank could be [5, 4, 3, 6, 1, 2, 7, 8, 9].
The function you want to optimize is
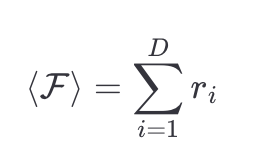
where r_i is the restaurant rating you visited on the day i.
Solution
Analytical
Every day you stay in the city you have two options: (1) try a new restaurant, or (2) go to the best restaurant you visited until that moment. We can think about this problem as an exploration-exploitation problem, this is, you explore the city for the first M days, and after that, you always go to the best place up to that moment for the following D−M nights.
Therefore, we can split the function to optimize as
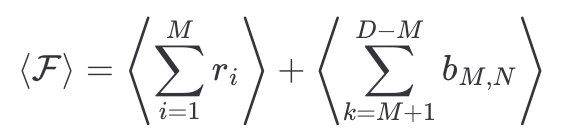
where b_M,N is the ranking of the best restaurant you have tried during the first M days.
The only free parameter in our equation is M, so you want to find the value of M where the expected profit is maximized. This is
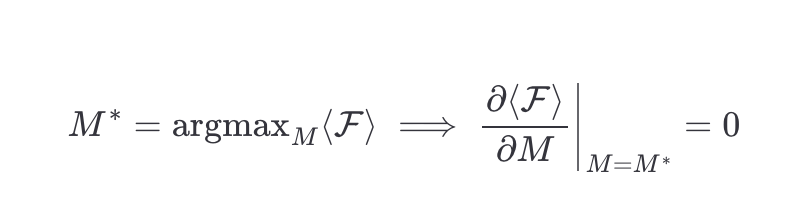
For the first term, applying linearity and knowing that <r_i> = (N+1)/2 we get
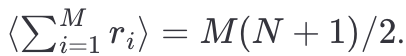
Now we need to compute ⟨b_M,N⟩, which is the expected maximum value obtained after M draws from the range (1,N).
On one hand, we know that if you only try a restaurant the expected ranking is ⟨b_1,N⟩ = (N+1) / 2. On the other hand, if you try all the restaurants, the expected maximum ranking is of course ⟨b_N,N⟩ = N.
We can also compute ⟨b_2,N⟩. In this case, there only exists 1 pair of restaurants where 2 is the maximum, ie you choose the restaurants (1,2). There only exist 2 pairs of restaurants where 3 is maximum, ie (1,3) and (2,3). There only exist 3 pairs of restaurants where 4 is maximum, ie (1,4), (2,4), and (3,4). And so on. All together there are N(N−1)/2 possible pairs. Therefore
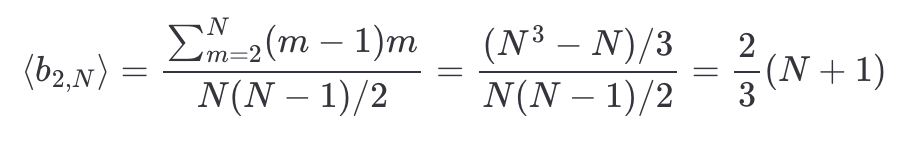
Now consider ⟨b_N−1,N⟩. This is, you try all the restaurants in the city except one. In this case, you’ll visit the best restaurant in N−1 cases, and in only one case you’ll skip the best restaurant. Therefore, the expected value is
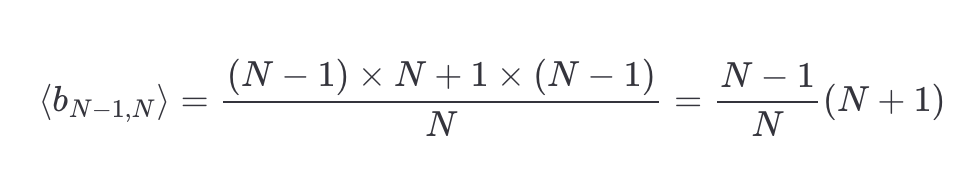
From all these results, one can see the pattern and guess that
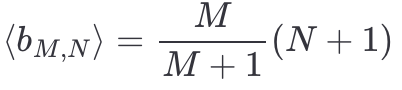
Putting it all together we finally have
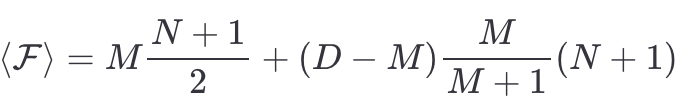
which has a maximum at
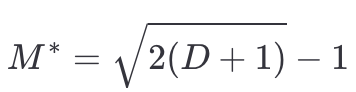
Notice that the result doesn’t depend on N. This means that you don’t care about how many different restaurants are in the city, which sounds -at least for me- a little bit counterintuitive.
Notice also that if you want to try all the restaurants in the city without decreasing the expected profit you’ll need to stay in the city D≥(N+1)^2/2−1 days. So if the city has 10 restaurants you’ll need to stay in the city for at least 60 days: exploring the city for the first 10 days, and during the following 50 days going to the best restaurant. Please, don’t use these results to plan your next vacations.
Numerical
In the last section, we derived an analytical solution to our problem. Let’s now run some simulations to derive more intuition about this problem. In particular, it seems surprising that the solution doesn’t depend on N. So let’s see if the simulations support this claim.
With the following snippet, one can simulate the expected profit ⟨F⟩ for a set of parameters
import numpy as np
def expected_profit(n_days: int, n_restaurants: int, n_experiments=10000):
"""
Computes the average profit at each
possible m \in range(1, n_days) over n_experiments.
:param n_days: number of times one can visit the restaurant.
:param n_restaurants: number of restaurants in the city.
:param n_experiments: number of experiments to perform.
"""
results = {}
for m in range(1, n_days + 1):
results[m] = []
for i in range(n_experiments):
ranks = x = list(range(n_restaurants))
np.random.shuffle(ranks)
profit = sum(ranks[:m]) + (n_days - m) * max(ranks[:m])
results[m].append(profit)
results = {k: np.mean(v) for k, v in results.items()}
return results
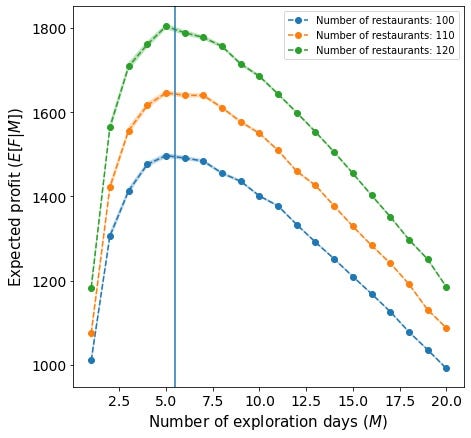
Using this snippet we have generated the following plot, using N=(100, 110, 120) and D=10. Notice how the maximum of the three curves coincides, which gives support to the counterintuitive analytical results.
Conclusions
In this post, we have explored Feynman’s Restaurant Problem. First, we have derived an analytical solution for the optimal exploration strategy, and then we have checked the analytical results with some simulations. Although these results make sense from a mathematical point of view, no one in their right mind would follow the optimal strategy. This is probably caused by the unrealistic assumptions we made, ie: you can’t go to the same restaurant every day of your life without getting tired of it. One possible solution is to change the rating of a restaurant r_i to be dependent on the number of times you’ve visited it, ie r_i(n). However, this is outside the scope of this post and we’re not going to do it, but maybe it can serve as inspiration for another post.
This story was originally posted here.
Feynman’s Restaurant Problem was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/tvzoGTl
via RiYo Analytics







ليست هناك تعليقات