https://ift.tt/GW5ULeI Part 3— Building a deep Q-network to play Gridworld — Learning Instability and Target Networks In this article let’...
Part 3— Building a deep Q-network to play Gridworld — Learning Instability and Target Networks
In this article let’s understand what is Learning instability which is a common problem with Deep Reinforcement Learning agents. We will solve this problem by implementing Target Network
Welcome to the third part of Deep Q-network tutorials. This is the continuation of the part 1 and part 2. If you have not read these, I strongly suggest you to read them, as many codes and explanations in this article will be directly related to the ones already explained in them.
Till now in part 1 !!
- We started by understanding what is Q-learning and the formula used to update the Q-learning
- Later we saw GridWorld game and defined its state, actions and rewards.
- Then we came up with a Reinforcement Learning approach to win the game
- We learnt how to import the GridWorld environment and various modes of the environment
- Designed and built a neural network to act as a Q function .
- We trained and tested our RL agent and got very good result in solving static GridWorld. But we failed to solve Random GridWorld.
In part 2 !!
- We learnt what is Catastrophic forgetting and how it effects the DQN agent
- We solved Catastrophic forgetting by implementing Experience reply
- We saw that DRL suffer from learning instability.
In this article we will learn how to implement Target network to get rid of the learning instability
What is learning instability ??
When Q-network's parameter's are updated after every move there are chances of instabilities in the network as reward is very sparse (significant reward is given only on winning or loosing). AS significant rewards are not available for each step the algorithm start to behave erratically.
For example, In any state moving ‘up’ would win the game and hence +10 as reward is achieved. Our algorithm thinks that action ‘up’ is good for the current state and updates its parameters to predict high Q value to this action. But in next game, the network predicts high Q value to ‘up’ and this might result in acquiring -10 reward. Now the our algorithm thinks the action is bad and updates its parameter. Then some game later moving up can result in winning. This would result in confusion and predicted Q value would never settle for a reasonable stable value. This is very similar to catastrophic forgetting which we have discussed in the previous article.
Device a duplicate Q-network called Target network!!
The solution DeepMind devised is to duplicate the Q-network into two copies, each with its own model parameters: the “regular” Q-network and a copy called the target network (symbolically denoted Q^-network, read “Q hat”). The target network is identical to the Q-network at the beginning, before any training, but its own parameters lag behind the regular Q-network in terms of how they’re updated.
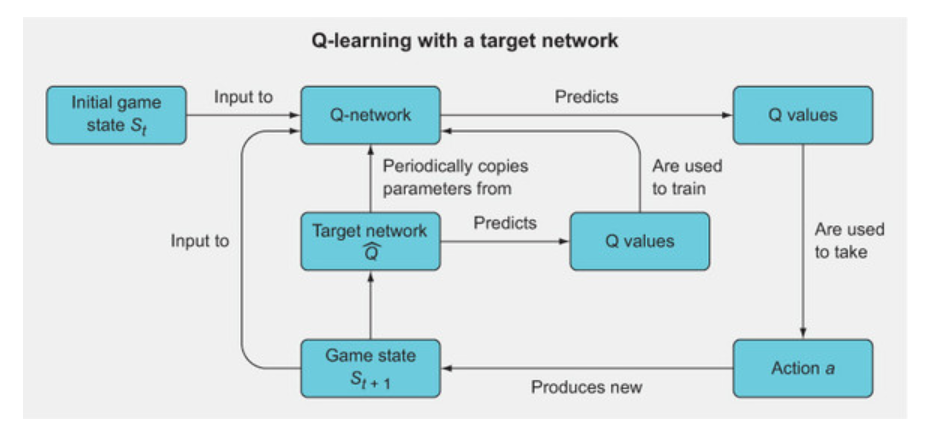
The above figure shows the general overview for Q-learning with a target network. It’s a fairly straightforward extension of the normal Q-learning algorithm, except that you have a second Q-network called the target network whose predicted Q values are used to backpropagate through and train the main Q-network. The target network’s parameters are not trained, but they are periodically synchronized with the Q-network’s parameters. The idea is that using the target network’s Q values to train the Q-network will improve the stability of the training.
Steps followed in using a target network are
- Initialize the Q-network with parameters (weights) θ(Q) (read “theta Q”).
- Initialize the target network as a copy of the Q-network, but with separate parameters θ(T) (read “theta T”), and set θ(T) = θ(Q).
- Use the epsilon greedy method to select the action a with the Q value of the Q-network
- Observe the reward r(t+1) for state s(t+1) post taking the action a
- The target network’s Q value will be set to r(t+1) if the episode has just been terminated (i.e., the game was won or lost) or to r(t+1) + γmaxQθr(S(t+1)) otherwise
- Backpropagate Target network’s Q-values through the Q-network. Here we are not using Q-values of Q-network as this will lead to learning instability
- Every C number of iterations, set the Target network weights with Q-Networks weight
Let’s see the implementation of Target Network using PyTorch
import copy
model = torch.nn.Sequential(
torch.nn.Linear(l1, l2),
torch.nn.ReLU(),
torch.nn.Linear(l2, l3),
torch.nn.ReLU(),
torch.nn.Linear(l3,l4)
)
model2 = model2 = copy.deepcopy(model) 1
model2.load_state_dict(model.state_dict()) 2
sync_freq = 50 3
loss_fn = torch.nn.MSELoss()
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- 1 Creates a second model by making an identical copy of the original Q-network model
- 2 Copies the parameters of the original model
- 3 Synchronizes the frequency parameter; every 50 steps we will copy the parameters of model into model2
Lets now build a DQN with experience replay and target network
from collections import deque
epochs = 5000
losses = []
mem_size = 1000
batch_size = 200
replay = deque(maxlen=mem_size)
max_moves = 50
h = 0
sync_freq = 500 1
j=0
for i in range(epochs):
game = Gridworld(size=4, mode='random')
state1_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state1 = torch.from_numpy(state1_).float()
status = 1
mov = 0
while(status == 1):
j+=1
mov += 1
qval = model(state1)
qval_ = qval.data.numpy()
if (random.random() < epsilon):
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_]
game.makeMove(action)
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state2 = torch.from_numpy(state2_).float()
reward = game.reward()
done = True if reward > 0 else False
exp = (state1, action_, reward, state2, done)
replay.append(exp)
state1 = state2
if len(replay) > batch_size:
minibatch = random.sample(replay, batch_size)
state1_batch = torch.cat([s1 for (s1,a,r,s2,d) in minibatch])
action_batch = torch.Tensor([a for (s1,a,r,s2,d) in minibatch])
reward_batch = torch.Tensor([r for (s1,a,r,s2,d) in minibatch])
state2_batch = torch.cat([s2 for (s1,a,r,s2,d) in minibatch])
done_batch = torch.Tensor([d for (s1,a,r,s2,d) in minibatch])
Q1 = model(state1_batch)
with torch.no_grad():
Q2 = model2(state2_batch) 2
Y = reward_batch + gamma * ((1-done_batch) * \
torch.max(Q2,dim=1)[0])
X = Q1.gather(dim=1,index=action_batch.long() \
.unsqueeze(dim=1)).squeeze()
loss = loss_fn(X, Y.detach())
print(i, loss.item())
clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
if j % sync_freq == 0: 3
model2.load_state_dict(model.state_dict())
if reward != -1 or mov > max_moves:
status = 0
mov = 0
losses = np.array(losses)
- 1 Sets the update frequency for synchronizing the target model parameters to the main DQN
- 2 Uses the target network to get the maximum Q value for the next state
- 3 Copies the main model parameters to the target network
Below is the loss plot of the DQN with target network
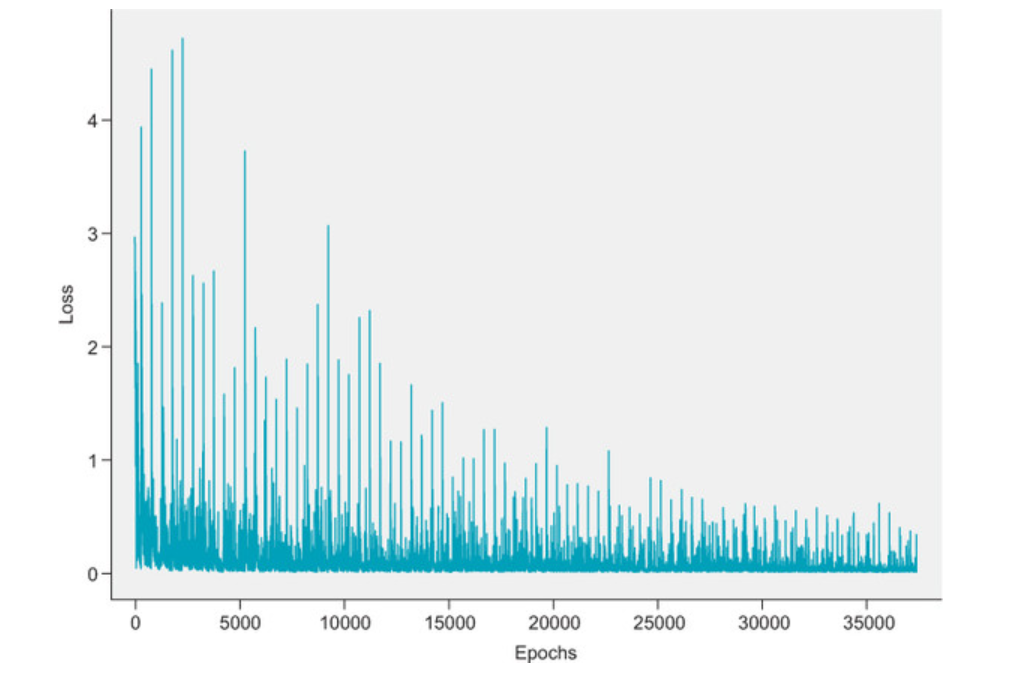
We can see that the loss has a more stable downward trend. Experiment with the hyperparameters, such as the experience replay buffer size, the batch size, the target network update frequency, and the learning rate. The performance can be quite sensitive to these hyperparameters.
When experimented on 1000 games we got a improvement of 3% in the accuracy over just using experience replay. Now the accuracy stands at around 93%
The entire code for this project can be found in this GIT link
Check out the part 1 of this article here:
Check out the part 2 of this article here:
Part 3— Building a deep Q-network to play Gridworld — Learning Instability and Target Networks was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/0UJ6omq
via RiYo Analytics








No comments