https://ift.tt/vgejBKV Part 2 — Building a deep Q-network to play Gridworld — Catastrophic Forgetting and Experience Replay In this articl...
Part 2 — Building a deep Q-network to play Gridworld — Catastrophic Forgetting and Experience Replay
In this article let’s talk about the problem in Vanilla Q-learning model: Catastrophic forgetting . We will solve this problem using Experience replay and see the improvement we have made in playing GridWorld
Welcome to the second part of Deep Q-network tutorials. This is the continuation of the part 1. If you have not read the part 1, I strongly suggest to go through it as many codes and explanations in this article will be directly related to the ones already explained in part 1.
Till now in part 1!!
- We started by understanding what is Q-learning and the formula used to update the Q-learning
- Later we saw GridWorld game and defined its state, actions and rewards.
- Then we came up with a Reinforcement Learning approach to win the game
- We learnt how to import the GridWorld environment and various modes of the environment
- Designed and built a neural network to act as a Q function .
- We trained and tested our RL agent and got very good result in solving static GridWorld. But we failed to solve Random GridWorld.
- We understand what is the problem and promise to solve it in this article
What is the Problem??
We were able to train our model on a static environment where, every time the model saw objects, player and goal in the same position. But when agent was trained on more complicated initialization where environment was randomly initialized everytime a new episode is created, it failed to learn.
The name for the above problem is Catastrophic forgetting. This is a important issue associated with gradient descent based training when we backpropagate after every moves in the play which we call as online training.
The idea of catastrophic forgetting is that when two game states are very similar and yet lead to very different outcomes, the Q function will get “confused” and won’t be able to learn what to do. In below example, the catastrophic forgetting happens because the Q function learns from game 1 that moving right leads to a +1 reward, but in game 2, which looks very similar, it gets a reward of –1 after moving right. As a result, the algorithm forgets what it previously learned about game 1, resulting in essentially no significant learning at all.
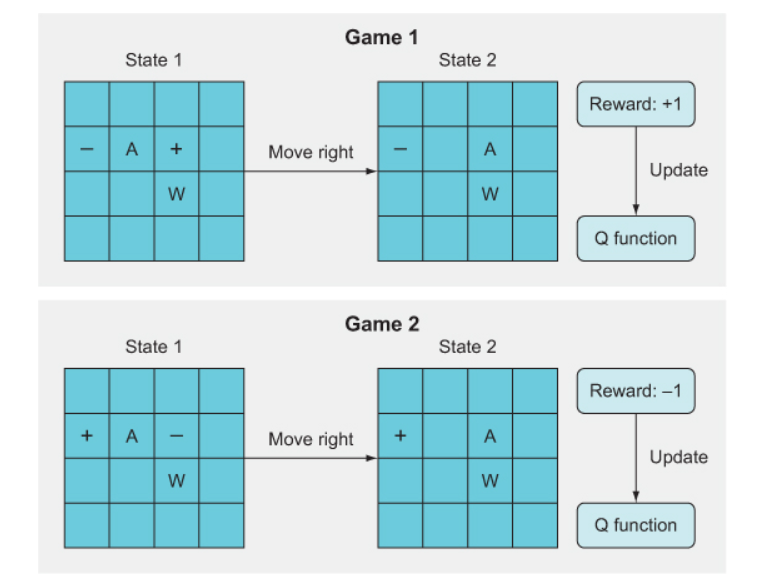
The reason for Catastrophic forgetting is that we are updating the weights after every move of the game. We generally don’t have this problem in the supervised learning realm, because we do randomized batch learning where we don’t update our weights until we’ve iterated through some random subset of training data and computed the sum or average gradient for the batch. This averages over the targets and stabilizes the learning.
Can we do it in DQN?
Yes, and that is what is called as Experience Replay. Experience replay gives us batch updating in an online learning schema.
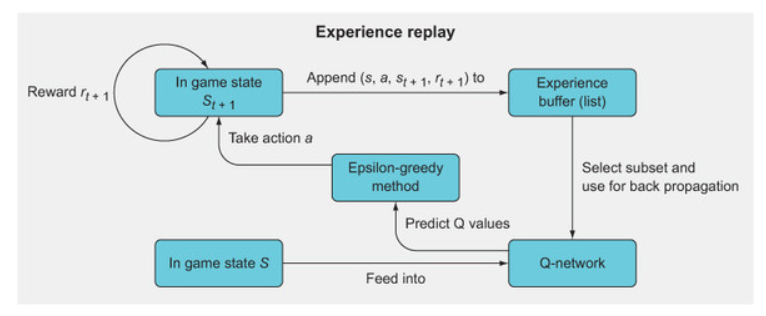
The above figure shows the general overview of experience replay, a method for mitigating a major problem with online training algorithms: catastrophic forgetting. The idea is to employ mini-batching by storing past experiences and then using a random subset of these experiences to update the Q-network, rather than using just the single most recent experience.
The steps involved in experience replay are
- In state s, take action a, and observe the new state s(t+1) and reward r(t+1).
- Store this as a tuple (s, a, s(t+1), r(t+1)) in a list.
- Continue to store each experience in this list until you have filled the list to a specific length (this is up to you to define).
- Once the experience replay memory is filled, randomly select a subset (again, you need to define the subset size).
- Iterate through this subset and calculate value updates for each subset; store these in a target array (such as Y) and store the state, s, of each memory in X.
- Use X and Y as a mini-batch for batch training. For subsequent epochs where the array is full, just overwrite old values in your experience replay memory array.
Implementation of the Experience replay can be seen below
from collections import deque
epochs = 5000
losses = []
mem_size = 1000 1
batch_size = 200 2
replay = deque(maxlen=mem_size) 3
max_moves = 50 4
h = 0
for i in range(epochs):
game = Gridworld(size=4, mode='random')
state1_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state1 = torch.from_numpy(state1_).float()
status = 1
mov = 0
while(status == 1):
mov += 1
qval = model(state1) 5
qval_ = qval.data.numpy()
if (random.random() < epsilon): 6
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_]
game.makeMove(action)
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state2 = torch.from_numpy(state2_).float()
reward = game.reward()
done = True if reward > 0 else False
exp = (state1, action_, reward, state2, done) 7
replay.append(exp) 8
state1 = state2
if len(replay) > batch_size: 9
minibatch = random.sample(replay, batch_size) 10
state1_batch = torch.cat([s1 for (s1,a,r,s2,d) in minibatch]) 11
action_batch = torch.Tensor([a for (s1,a,r,s2,d) in minibatch])
reward_batch = torch.Tensor([r for (s1,a,r,s2,d) in minibatch])
state2_batch = torch.cat([s2 for (s1,a,r,s2,d) in minibatch])
done_batch = torch.Tensor([d for (s1,a,r,s2,d) in minibatch])
Q1 = model(state1_batch) 12
with torch.no_grad():
Q2 = model(state2_batch) 13
Y = reward_batch + gamma * ((1 - done_batch) * torch.max(Q2,dim=1)[0]) 14
X = \
Q1.gather(dim=1,index=action_batch.long().unsqueeze(dim=1)).squeeze()
loss = loss_fn(X, Y.detach())
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
if reward != -1 or mov > max_moves: 15
status = 0
mov = 0
losses = np.array(losses)
- 1 Sets the total size of the experience replay memory
- 2 Sets the mini-batch size
- 3 Creates the memory replay as a deque list
- 4 Sets the maximum number of moves before game is over
- 5 Selects an action using the epsilon-greedy strategy
- 6 Computes Q values from the input state in order to select an action
- 7 Creates an experience of state, reward, action, and the next state as a tuple
- 8 Adds the experience to the experience replay list
- 9 If the replay list is at least as long as the mini-batch size, begins the mini-batch training
- 10 Randomly samples a subset of the replay list
- 11 Separates out the components of each experience into separate mini-batch tensors
- 12 Recomputes Q values for the mini-batch of states to get gradients
- 13 Computes Q values for the mini-batch of next states, but doesn’t compute gradients
- 14 Computes the target Q values we want the DQN to learn
- 15 If the game is over, resets status and mov number
done_batch in Y = reward_batch + gamma * ((1 — done_batch) * torch.max(Q2,dim=1)[0]) is a boolean variable which sets the right of reward_batch to zero when the the game is done (end of episode)
After training the model in Random mode for 5000 epoch and running the game for 1000 times, we were able to win 90% of games and the loss locked something like below
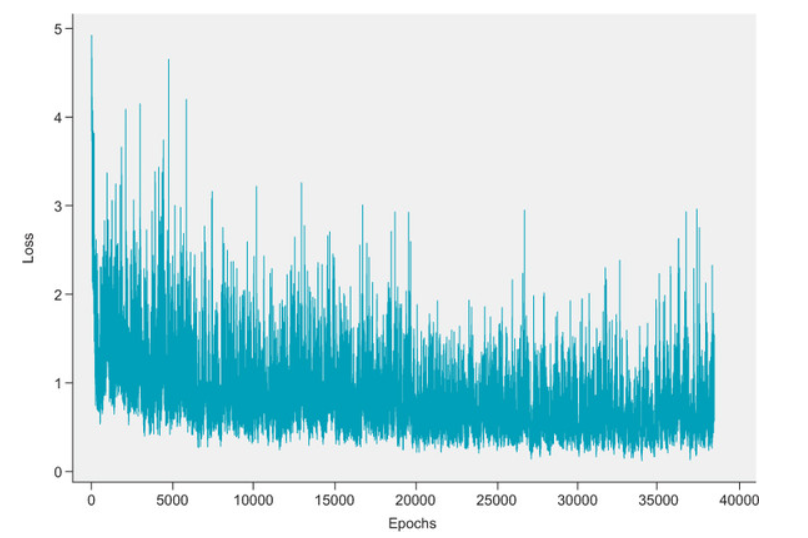
From above figure we can see that the loss is clearly decreasing over the training and also we are able to win the game 90% of the times. We have to understand that there can be some states of the game where winning is impossible. So 90% win rate is really good.
But still we see that the loss increasing in later epochs and the trend is very instable. This is very common in Deep Reinforcement Learning (DRL) problems. We call this is learning instability. And yes, there is a solution to this.
Using a Target network will solve the problem of leaning instability. We will see how to implement the target network in part 3
The code for this article can be obtained in this GIT link
Till Now !!
- We learnt what is Catastrophic forgetting and how it effects the DQN agent
- We solved Catastrophic forgetting by implementing Experience reply
- DRL suffer from learning instability. We will see how to implement Target network to get rid of the learning instability in part 3
Check out Part 1 of this article here:
Part 1 — Building a deep Q-network to play Gridworld — DeepMind’s deep Q-networks
Check out Part 3 of this article here:
https://nandakishorej8.medium.com/part-3-building-a-deep-q-network-to-play-gridworld-learning-instability-and-target-networks-fb399cb42616
Part 2 — Building a deep Q-network to play Gridworld — Catastrophic Forgetting and Experience… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/su3FN7f
via RiYo Analytics








No comments