https://ift.tt/Epu7l4z Introducing Fugue — Reducing PySpark Developer Friction Increase developer productivity and decrease costs for big ...
Introducing Fugue — Reducing PySpark Developer Friction
Increase developer productivity and decrease costs for big data projects
An initial version of this article was published on James Le’s blog here. It has been updated to include new Fugue features.

Fugue’s Motivation
Data practitioners often start out by working with Pandas or SQL. Sooner or later, the size of data being processed outgrows what Pandas can handle efficiently, and distributed compute becomes necessary. One such tool is Spark, a popular distributed computing framework that enables processing large amounts of data in-memory on a cluster of machines. While the Spark engine is very powerful in scaling data pipelines, there are many pitfalls that new users, and even experienced ones, face when using Spark.
The expected initial difficulty is having to learn an entirely new framework. The syntax and usage of Spark and Pandas are very different. Users who migrate projects from Pandas to Spark often find themselves re-writing most of the code, even for the exact same application logic. Even worse, some operations that are trivial to do in Pandas become a lot harder in Spark and take a while to implement.
A simple example of this disparity is getting the median for each group of data. In Pandas, there is no need to think twice about getting the median of each group. On Spark though, the operation isn’t as straightforward. We compare the syntax of the two frameworks in the code snippet below:
This syntax disparity is because calculating the median is expensive in a distributed setting. All of the data belonging to one group needs to be moved to the same machine. As such, data needs to be shuffled and sorted before the median can be obtained. To reduce computation cost, an approximate median can be obtained with the specified tolerance. In the snippet above, 20 is the accuracy meaning the relative error could be 1/20, or 5%. Specifying the tolerance allows users to balance accuracy and speed.
Beyond the syntax difference, there are important concepts in a distributed setting (such as partitioning, shuffling, persisting, and lazy evaluation) that Pandas users are not aware of initially. These concepts take a significant amount of time to learn and master, making it hard to fully utilize the Spark engine.
Fugue, an open-source abstraction layer, provides a seamless transition from a single machine to a distributed computing setting. With Fugue, users can code their logic in native Python, Pandas, or SQL, and then bring it to the Spark (or Dask) engine for execution. This means that users don’t even need to learn the Spark syntax to use Spark.

This article will discuss the pain points Spark users face and how Fugue addresses them. Fugue is the direct result of several years of questioning how the Spark developer experience can be improved. Beyond providing an easier interface to coding in Spark, there are more tangible benefits introduced by using an abstraction layer. Here, we’ll show how Fugue:
- Handles inconsistent behavior between different compute frameworks (Pandas, Spark, and Dask)
- Allows reusability of code across Pandas-sized and Spark-sized data
- Dramatically speeds up testing and lowers total project cost
- Enables new users to be productive with Spark much faster
- Provides a SQL interface capable of handling end-to-end workflows
Inconsistencies Between Pandas and Spark
Can we have a unified interface for big and small data?
Pandas users transitioning to Spark often encounter inconsistent behaviors. First off, Pandas allows for mixed column types. This means strings and numbers can be mixed in the same column. In Spark, the schema is strictly enforced, and mixed-type columns are not allowed. This is because Pandas has the luxury of seeing all the data as it performs operations, while Spark performs operations across several machines that hold different parts of data. This means Spark can easily have different partitions behave differently if the schema is not strictly enforced.
NULLs are also handled differently by Pandas and Spark. The table below summarizes the default handling of NULL values

This is the first benefit of using Fugue as an abstraction layer. Getting Pandas code to run on Spark is one thing, but it’s a very tedious process to have the code give consistent results between the computation engines. In a lot of cases, extra code has to be written to get the same results. Fugue takes care of the consistency to create a consistent bridge between Pandas and Spark. Fugue was designed to be consistent with Spark and SQL because that guarantees code will work as expected in the distributed setting. Users should not have to spend their time worrying about framework-specific behavior.
Decoupling of Logic and Execution
Why do I need to choose a framework before I start a data project?
One of the pain points with using Pandas and Spark is that the logic is tightly coupled with the interface. This is impractical because it requires data practitioners to choose what they’ll code with at the project onset. Here are two scenarios, which are two sides of the same problem.
- A user codes in Pandas, and then the data becomes too big. To solve this, the underlying hardware has to be upgraded to support execution (vertical scaling).
- A user codes in Spark expecting data to be big, but it never grows to the size that demands Spark. The code and tests run slower than it has to because of the Spark overhead.
In both scenarios, the user ends up using the wrong tool for the job. These scenarios could be avoided if logic and execution are decoupled. Using Fugue as an abstraction layer allows users to write one code base that is compatible with both Pandas and Spark. Execution can then be specified during runtime by passing an execution engine. To demonstrate this, let’s look at the easiest way to use Fugue, the transform() function.
For this example, we have a DataFrame with columns id and value . We want to create a column called food by mapping value to the corresponding food in mapping.
Pandas has a simple method for this. We can create a Pandas function that invokes it.
Without editing the Pandas function, we can bring it to Spark using Fugue’s transform() function. This function can take a Pandas DataFrame or Spark DataFrame, and it will return a Spark DataFrame if using the Spark engine.
Note we need to call .show() because Spark evaluates lazily. The output is seen below.
+---+-----+------+
| id|value| food|
+---+-----+------+
| 0| A| Apple|
| 1| B|Banana|
| 2| C|Carrot|
+---+-----+------+
In this scenario, we did not have to edit the original Pandas-based function. The transform() function took care of porting execution over to Spark because we supplied a spark_session as the engine. If the engine is not specified, the default Pandas-based execution engine is used. Pandas users may not be used to defining schema explicitly, but it is a requirement for distributed computing.
But actually, Pandas will not always be the easiest way to express logic. Thus, Fugue also supports using native Python functions by being flexible in handling different input and output types. Below are three different implementations for our map_letter_to_food() function. All of them are compatible with the Fugue transform() function and can be used on Pandas, Spark, and Dask engines with the same syntax.
Notice all of the logic is defined in the map_letter_to_food() function. Execution is then deferred to the transform() call where we specify the engine. Users only need to be concerned with defining their logic in their preferred way. Fugue will then do the work of bringing it to the specified execution engine.
While Spark provides pandas_udfas a way to execute Pandas functions on Spark, Fugue provides a simpler interface around the schema. Schema management ends up producing a lot of boilerplate code in Spark. Here, the schema is passed to transform() in a minimal string, leaving the original function definition untouched. Also, Fugue can use pandas_udf under the hood if a user specifies, and the overhead for using Fugue in this scenario is less than one second as can be seen in this benchmark.
On a more practical level, it is very common for data science teams to have shared libraries that contain specific business logic for cleaning and transforming data. Currently, the logic has to be implemented twice — once for Pandas-sized projects, and once again for Spark-sized projects). By using Fugue, the same function could be used on both Pandas and Spark engines without any code change.
This also future-proofs the code. What if one day, you decide you want to use the Dask Engine? What if you wanted to use a Ray engine? Using Fugue as an abstraction layer would let you migrate seamlessly, as it would just be a matter of specifying the execution engine during runtime. On the other hand, writing code using the Spark API would automatically lock in the codebase to that framework. Fugue’s minimalistic interface intentionally makes it easy to offboard if a user wants to.
Improving Testability of Spark
How can we accelerate the development iterations and testing on big data projects?
Testing code in Spark is tedious. There are currently two approaches that are used in developing Spark applications. Users on Databricks may use the databricks-connectPython library, which replaces the local installation of PySpark. Whenever pysparkis called, the execution plan is compiled locally and then executed on the configured cluster. This means that simple tests and code changes require the backend cluster to be spun up. It takes a while and is also extremely expensive.
The second approach is to develop locally and then use the spark-submit tool to package the code and run it on the cluster through SSH. This process takes a bit more work and is time-consuming. For teams doing test-driven development, the whole test suite can take a very long time to test. Even if all the testing is done locally, Spark is still slow to spin up compared to Pandas because the JVM environment needs to be set up. Assertions on values on DataFrame operations require either a collect()or toPandas()call, which would take a lot of time compared to Pandas-based evaluation.
Because selecting an execution engine at runtime, we can use the Pandas-based engine on smaller data during testing, and then use the Spark engine for production. Testing becomes faster and cheaper because code is decoupled from Spark, meaning that the Spark runtime does not have to be spun up for every little code test. After testing locally with Pandas, the same code can be brought to the Spark execution engine to scale.
The consistency guaranteed by Fugue ensures that running on the default engine and running on the Spark execution engine provides the same results. Having this separation dramatically speeds up development cycles, and makes big data projects significantly cheaper as expensive mistakes could be avoided. Testing time is often reduced from minutes to seconds.
Users of Fugue also benefit from having to write fewer tests. In our transform() example above, only the original function needs to be tested. Users can also test transform() , but it has already been heavily tested on the Fugue level. In comparison, using a PySpark approach will require 1 or 2 helper functions that then have to be tested also. An equivalent PySpark code snippet to transform() can be found here.
Reducing Expensive Mistakes
How can we reduce the friction distributed computing beginners face?
A lot of Spark users are not aware that it’s very easy for data to be recomputed in Spark. Distributed computing frameworks lazily evaluate code, meaning the computation graph (or DAG) is constructed and then executed when an action is performed to materialize a result. Actions are operations like printing or saving the DataFrame.
In the computation graph below, B is recomputed for the actions that run C, D, and E. This means it is computed three times. If one run of B takes one hour, we unnecessarily add two hours to our workflow.
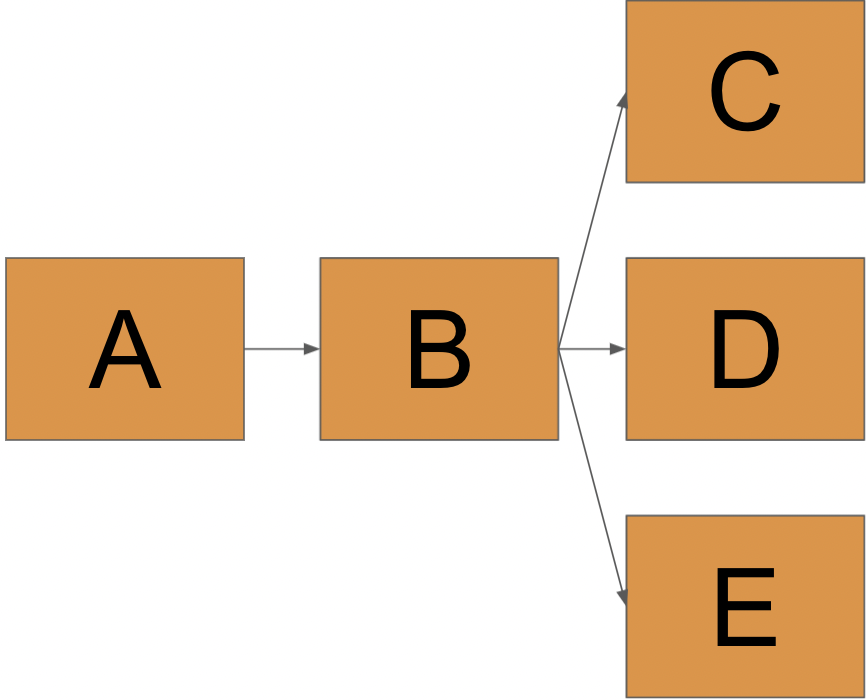
Experienced Spark users will know that B should be persisted to avoid recomputation. However, people less familiar with lazy evaluation often suffer from unnecessary recomputation. In extreme situations, this lazy evaluation and recomputation can lead to unexpected behavior when operations are not deterministic. The clearest example would be a column with random numbers in B. The random number column will be recalculated with different results for C, D, and E if B was not persisted.
To solve this, Fugue also has optimizations at the workflow level. Previously, we showed Fugue’s transform() interface for a single function. Fugue also has support for constructing full workflows by using FugueWorkflow() as seen below. This is an engine-agnostic DAG representation of an entire workflow. FugueWorkflow() can take in an engine like the previously shown transform() function to port it to Spark or Dask.
By analyzing the dependencies of the computation graph (DAG) constructed, Fugue can smartly persist DataFrames that will be reused by multiple actions. For more control, Fugue also provides an interface for users to persist the DataFrames themselves.
Through this DAG, Fugue can also perform validations (such as schema and partitioning) that allow code to fail quickly. Fugue will recognize if the schema is mismatched for future operations, and error out immediately. A lot of Spark users often spend a lot of money and time running code on a cluster, only to find out hours later that it failed. Having Fugue’s DAG compiling process helps users avoid expensive mistakes.
SQL Interface
How can SQL be elevated to a first-class grammar for compute workflows?
One of Spark’s innovations is the SQL interface in SparkSQL. The SparkSQL interface is great for allowing people who prefer SQL to describe their computation logic. Unfortunately, it does not let users take advantage of everything Spark has to offer because it is tightly based on ANSI SQL. It is also a second-class interface, often invoked in-between predominantly Python-based code.
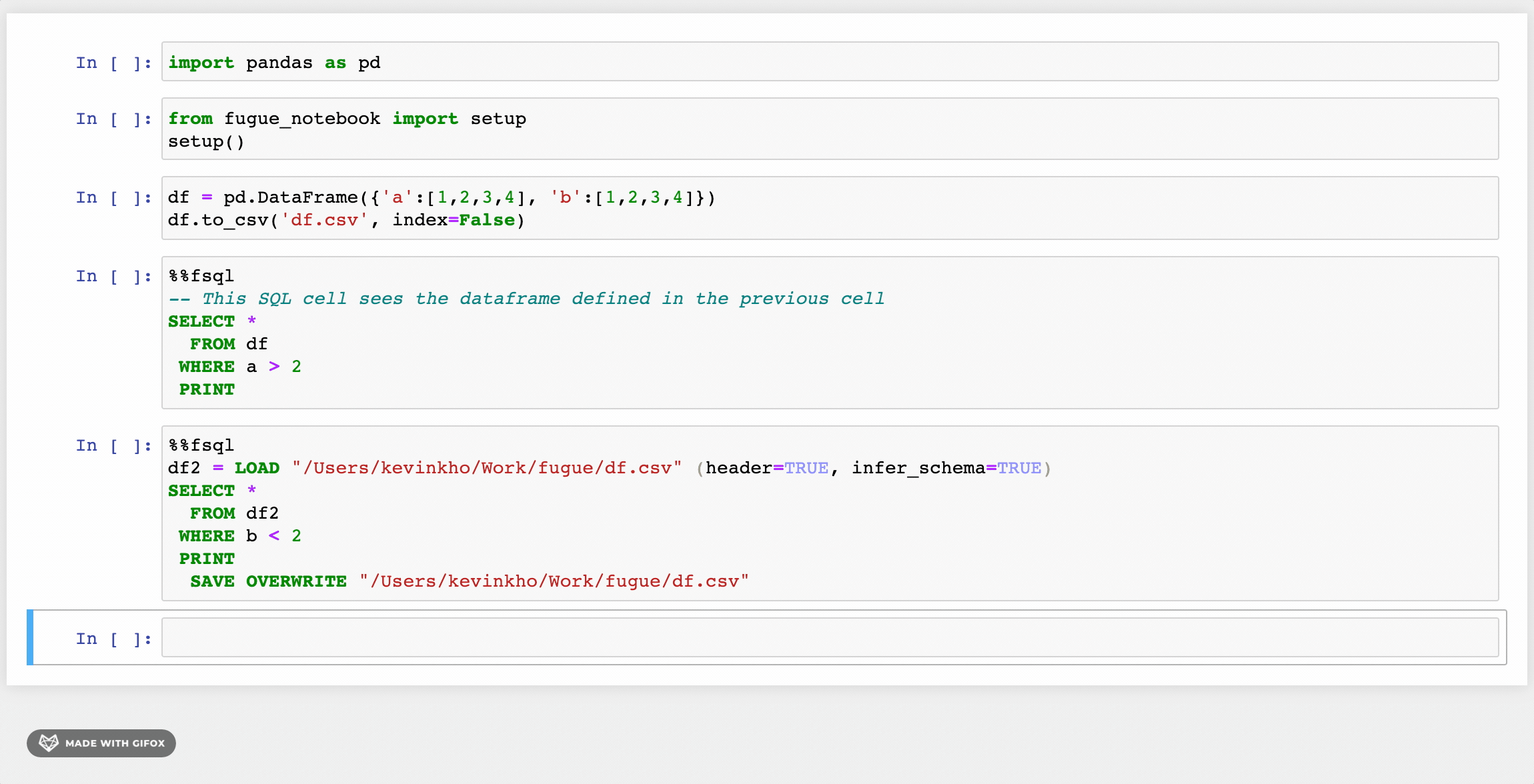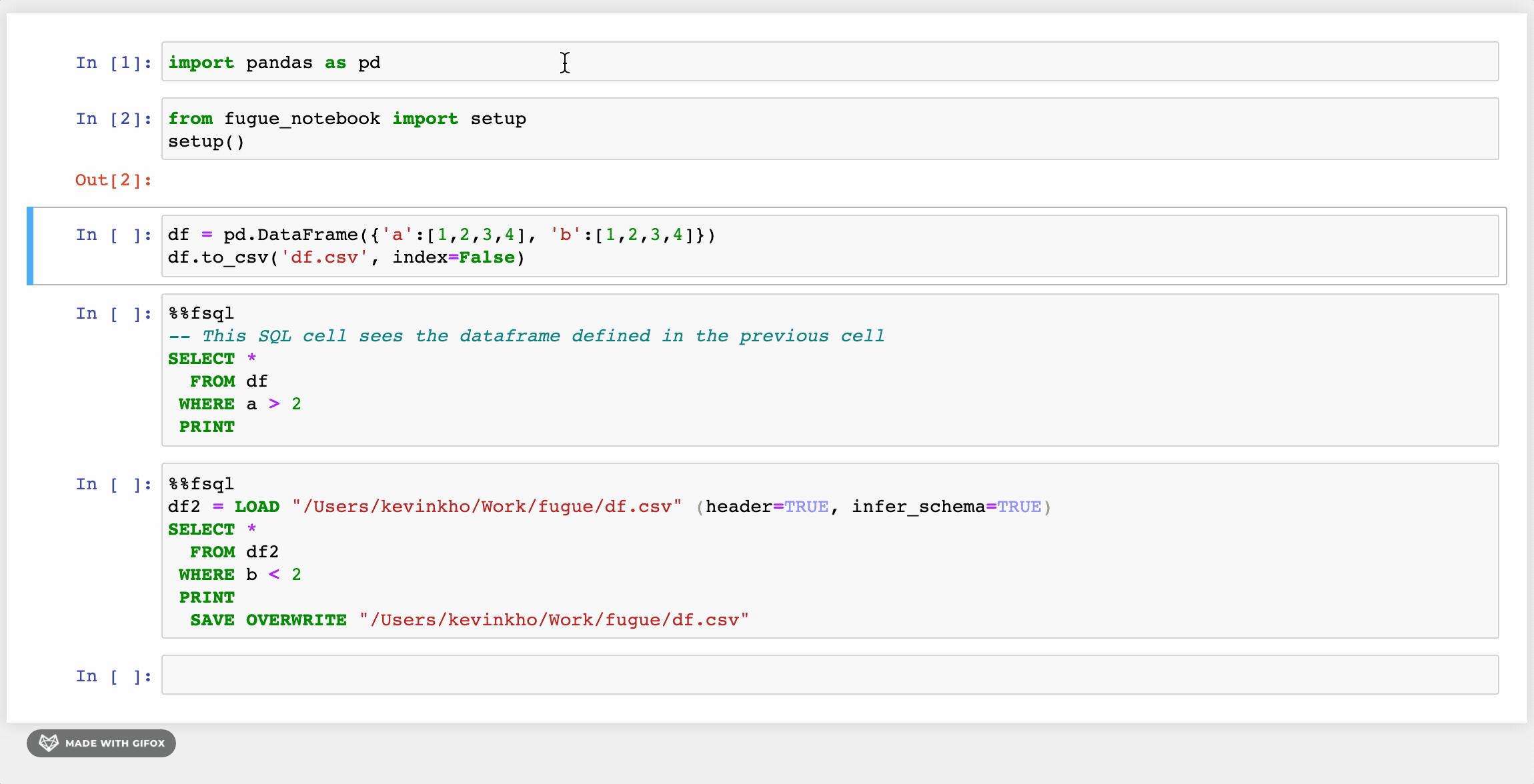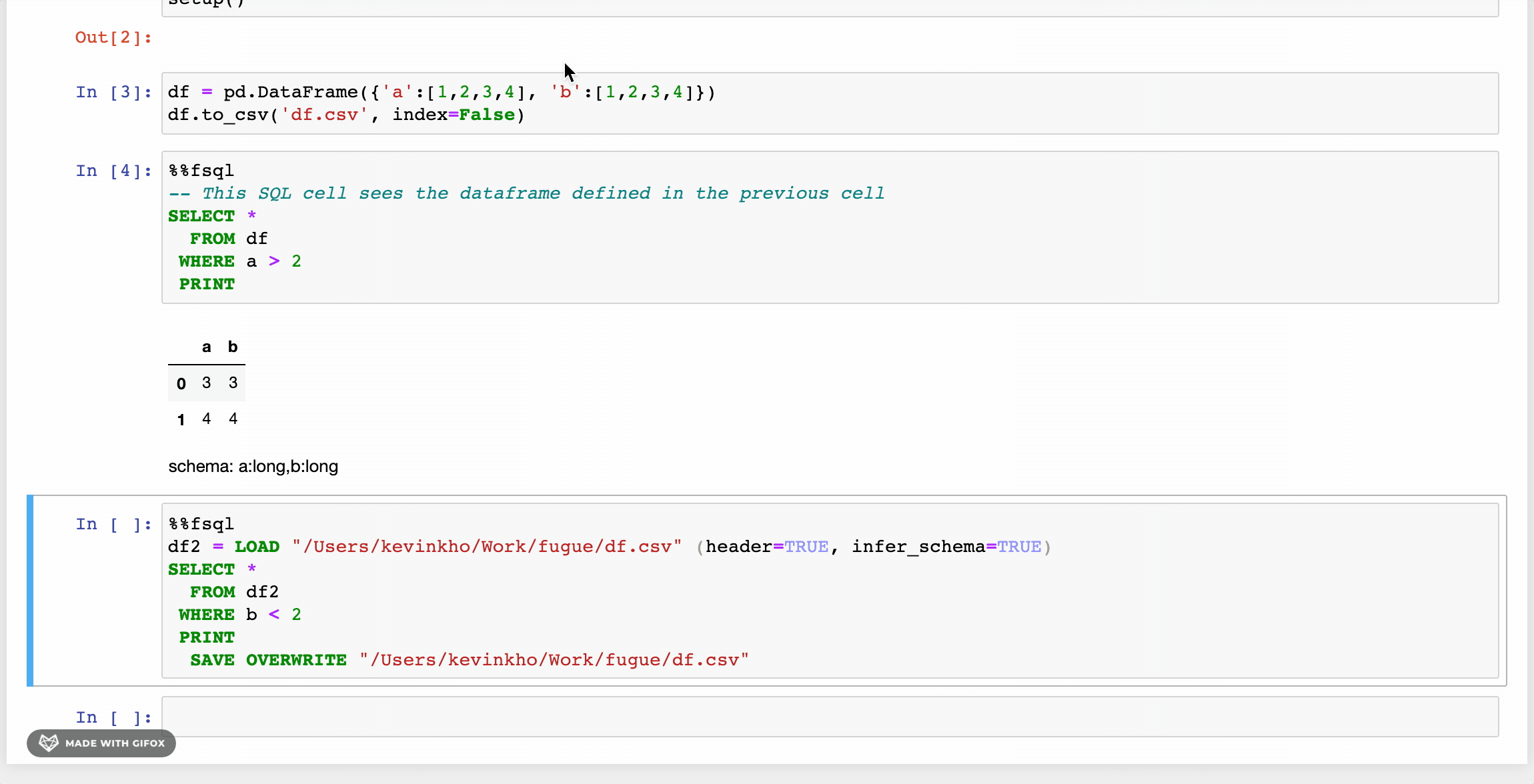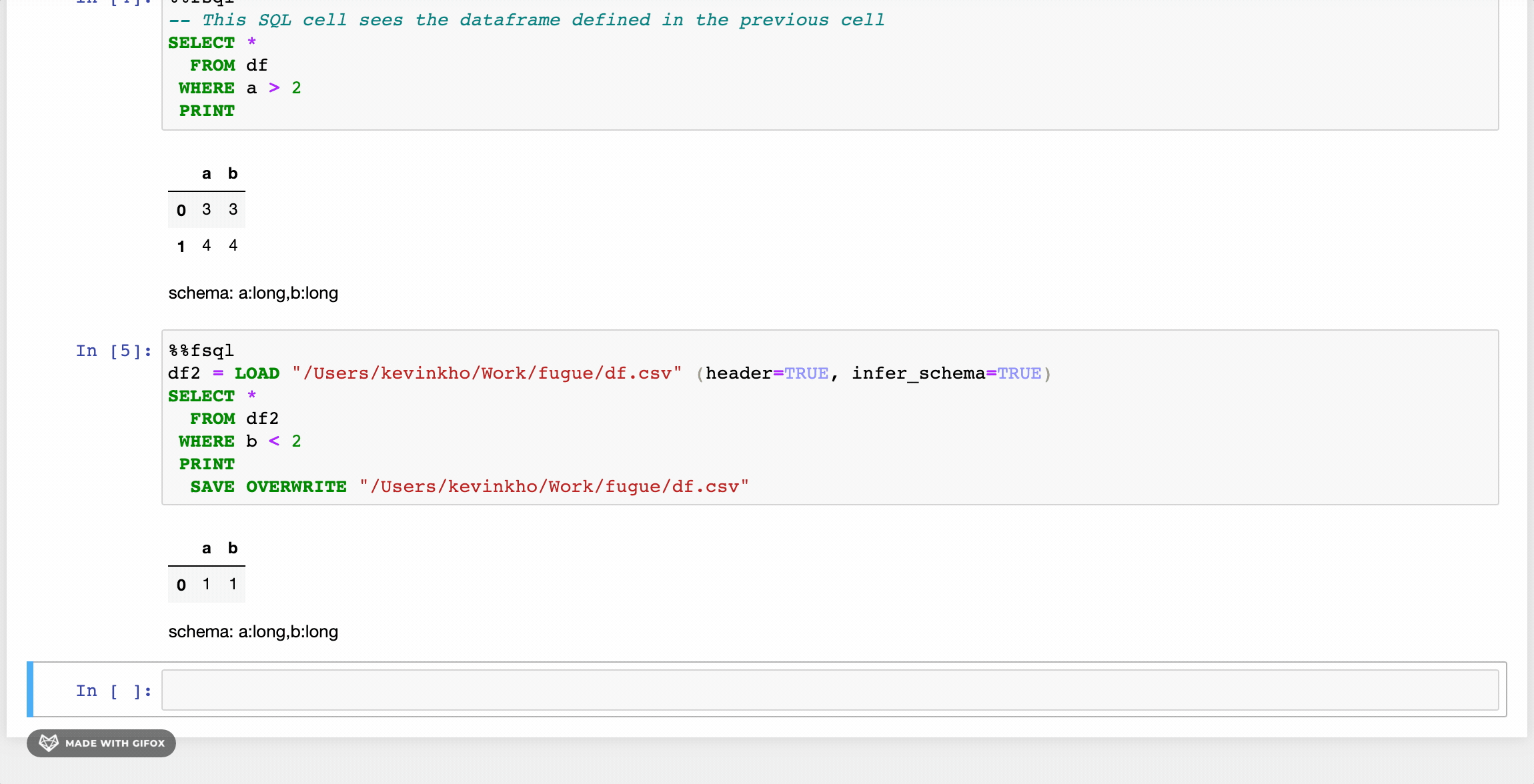
Fugue has a SQL interface based on SparkSQL’s implementation but with added enhancements. First, there are additional keywords like BROADCAST, PERSIST, PREPARTITION, and PRESORT that allow users to explicitly take advantage of Spark’s distributed computing operations. There is also support to use Python functions with FugueSQL through the TRANSFORM keyword (among others). More keywords such as LOAD and SAVE have been added to support end-to-end workflows. Below is the equivalent of our previous FugueWorkflow.
Now a heavy SQL user can LOAD data, perform transformations, and SAVE results all using FugueSQL on top of the Spark engine. SQL lovers can express their end-to-end computation logic in a SQL-like interface. One weakness is that ANSI SQL only allows one select statement, while FugueSQL allows multiple. FugueSQL allows variable assignments as temporary tables, which is a friendlier syntax than common table expressions (CTEs). For more information, check the FugueSQL docs.
This FugueSQL interface builds on top of the abstraction layer, making it compatible with Pandas, Spark, Dask, and BlazingSQL. It is a first-class citizen that offers the same flexibility and benefits as the Fugue Python API.
There is also a notebook extension with syntax highlighting that allows users to just invoke the %%fsql cell magic. For more information, see this article. Note that the syntax highlighting is only available for the classic Jupyter notebook at the moment, and not for JupyterLab. It also works well in the Kaggle environment, taking advantage of the multiple cores in a Kaggle kernel.
Partitioning
Are there better ways to partition data for certain use cases?
Spark uses hash partitions by default. For a small number of keys, this could easily lead to uneven partitions. This may not seem like a big deal, but if each key takes one hour to run, having uneven partitions could make a job take several more hours to run. The tricky thing is partitions on Spark cannot be made even without writing a significant amount of code.
Fugue allows users to choose between the default hash partition, random partition, or an even partition. Each of these partitioning strategies lends itself well to different use cases. Below is a table summary of when to use each one.

Even partitioning is particularly useful for smaller data that require large computations. When data is skewed, some partitions end up containing more data than others. Execution time is then dependent on the completion time of the partition with the largest amount of data. By enforcing an equal number of elements for each partition, the execution time can be reduced. For more information, check the partition documentation.
In the code below, we get the five rows that contain the highest values of col2. The presort is applied as the data is partitioned. The transform()function can also take in a partition strategy.
Fugue vs Koalas vs Modin

Fugue often gets compared with Koalas and Modin as a bridge between single-core computing to distributed computing. Koalas is a Pandas interface for Spark, and Modin is a Pandas interface for Dask and Ray. It’s hard to compare the projects because the objectives are different, but the main difference is that these two frameworks believe Pandas can be the grammar for distributed computing, while Fugue believes native Python and SQL should be, but supports Pandas usage as well.
At the onset, switching to Koalas or Modin may seem a lot easier when coming from Pandas. Some users mistakenly expect that the Pandas importstatement can be changed, and the code will work perfectly on the distributed setting. In a lot of cases, this promise is too good to be true because this requires the interfaces of the libraries to be perfectly in sync with the Pandas API, which is nearly impossible. For example, the Koalas implementation of the rolling operation does not have the window types that the Pandas API provides.
But having complete parity with the Pandas API does not always make sense in the distributed setting. For example, a transpose operation works in Pandas but is very expensive when the data is spread on different machines. In extreme cases, the application has to make extreme compromises to get this import statement magic to work. If an operation doesn’t exist in the Modin API, the architecture defaults to using Pandas, which collects all of the data to a single machine. This can easily overload the machine collecting all the data that was previously spread across multiple workers.
There are also philosophical reasons why Fugue avoids using Pandas as the grammar for distributed compute operations. Koalas and Modin add vocabulary to that grammar, such as persist and broadcast operations to control data movement between workers. But the misalignment here is that the base grammar of Pandas does not translate well to distributed scenarios. The index is very core to Pandas workflows. In a typical script, a lot of reset_index()and set_index()calls will be used. When performing groupby operations, the index is automatically set. The index preserves a global order, allowing for the ilocmethod to be used. Some operations even use index in join conditions. In a distributed setting, order is not guaranteed, as it’s often unnecessarily computationally expensive to keep track of it.
The performance-productivity tradeoff and Fugue
There is always a tradeoff between code performance and developer productivity. Optimizing for performance requires deep engine-specific tricks that are hard to code and maintain. On the other hand, optimizing for developer productivity means churning out solutions as fast as possible without worrying about code performance. Fugue sacrifices a bit of performance for significant increases in iteration speed and maintainability. By focusing on defining the logic on a partition level, users often find their code becomes clearer and big data problems become small and manageable.
While using Pandas and custom functions on Spark used to be slower, it is getting more performant due to improvements on the Spark engine (the use of Apache Arrow). The efficiency lost by Fugue applying conversions is very minimal and users often see speedups in their code gained from more efficient handling of data in the distributed setting. In fact, Fugue transcribes a lot of the code into Spark code, meaning that the only thing changing is the interface in a lot of cases.
Conclusion
In this article, we talked about the pain points of using Spark, including testability, the inconsistencies with Pandas, and the lack of a robust SQL interface. We presented Fugue as a friendlier interface to work with Spark. Fugue does not compete with the Spark engine; Fugue makes it easier to use. By using Fugue, users often see quicker iterations of big data projects, reducing time-to-delivery and project cost.
Using Fugue is non-invasive and free of any dependencies. Logic can be defined in native Python code or Pandas, and then ported to Spark. Fugue believes in adapting to the user, so they can focus on defining their logic rather than worrying about its execution. Though not covered in this article, Fugue also provides ways to use native Spark code or Spark configurations. It does not restrict access to the underlying framework.
Contact Us
If you want to learn more about Fugue, discuss your Spark pain points, or even correct something wrong mentioned in this article, we’d love to hear from you! Also, feel free to reach out if you want us to give a presentation to your team, meetup, or conference.
- Email: hello@fugue.ai
- Slack: Join here
Resources
Additional resources for Fugue:
- Fugue Tutorials
- Fugue Repo
- List of Fugue Conferences Presentations (PyCon, PyData, KubeCon, etc.)
There are a lot more specific applications opened by the abstraction layer. So far, we have presented validation, tuning, and the SQL interface.
Introducing Fugue — Reducing PySpark Developer Friction was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/H2ZhBpP
via RiYo Analytics






No comments