https://ift.tt/3nISXyi An introduction to embedding-based classification of unlabeled text documents Photo by Patrick Tomasso on Unsplas...
An introduction to embedding-based classification of unlabeled text documents

Text classification is the task of assigning a sentence or document an appropriate category. The categories depend on the selected dataset and can cover arbitrary subjects. Therefore, text classifiers can be used to organize, structure, and categorize any kind of text.
Common approaches use supervised learning to classify texts. Especially BERT-based language models achieved very good text classification results in recent years. These conventional text classification approaches usually require a large amount of labeled training data. In practice, however, an annotated text dataset for training state-of-the-art classification algorithms is often unavailable. The annotation of data usually involves a lot of manual effort and high expenses. Therefore, unsupervised approaches offer the opportunity to run low-cost text classification for unlabeled data sets. In this article, you will learn how to use Lbl2Vec to perform unsupervised text classification.
How does Lbl2Vec work?
Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embedded label, document and word vectors and returns documents of categories modeled by manually predefined keywords. The key idea of the algorithm is that many semantically similar keywords can represent a category. In the first step, the algorithm creates a joint embedding of document and word vectors. Once documents and words are embedded in a shared vector space, the goal of the algorithm is to learn label vectors from previously manually defined keywords representing a category. Finally, the algorithm can predict the affiliation of documents to categories based on the similarities of the document vectors with the label vectors. At a high level, the algorithm performs the following steps to classify unlabeled texts:
1. Use Manually Defined Keywords for Each Category of Interest
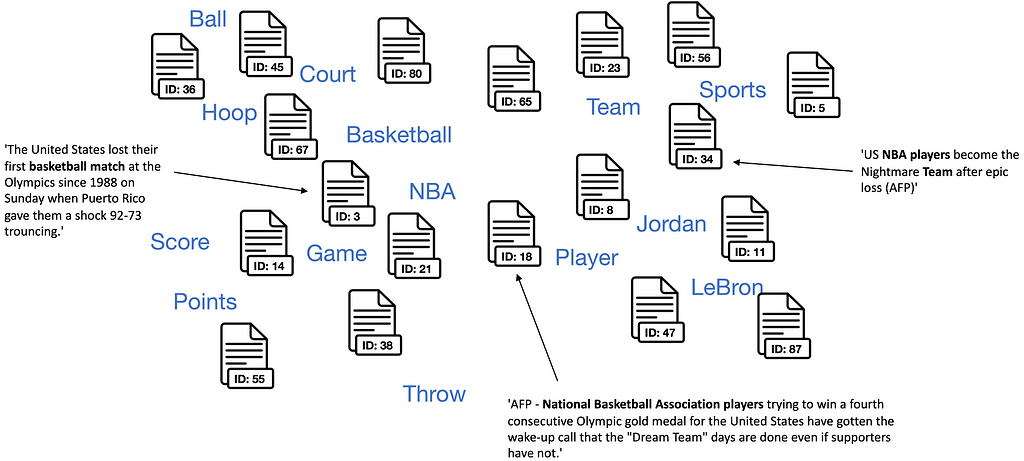
First, we have to define keywords to describe each classification category of interest. This process requires some degree of domain knowledge to define keywords that describe classification categories and are semantically similar to each other within the classification categories.

2. Create Jointly Embedded Document and Word Vectors
An embedding vector is a vector that allows us to represent a word or text document in multi-dimensional space. The idea behind embedding vectors is that similar words or text documents will have similar vectors. -Amol Mavuduru
Therefore, after creating jointly embedded vectors, documents are located close to other similar documents and close to the most distinguishing words.
Once we have a set of word and document vectors, we can move on to the next step.
3. Find Document Vectors that are Similar to the Keyword Vectors of Each Classification Category
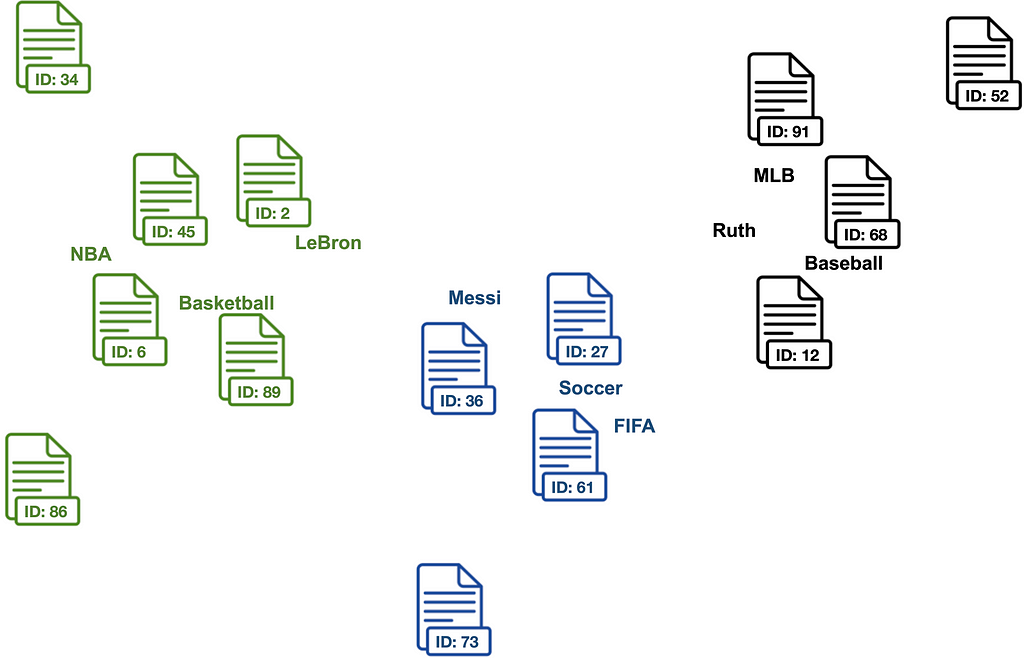
Now we can compute cosine similarities between documents and the manually defined keywords of each category. Documents that are similar to category keywords are assigned to a set of candidate documents of the respective category.
4. Clean Outlier Documents for Each Classification Category
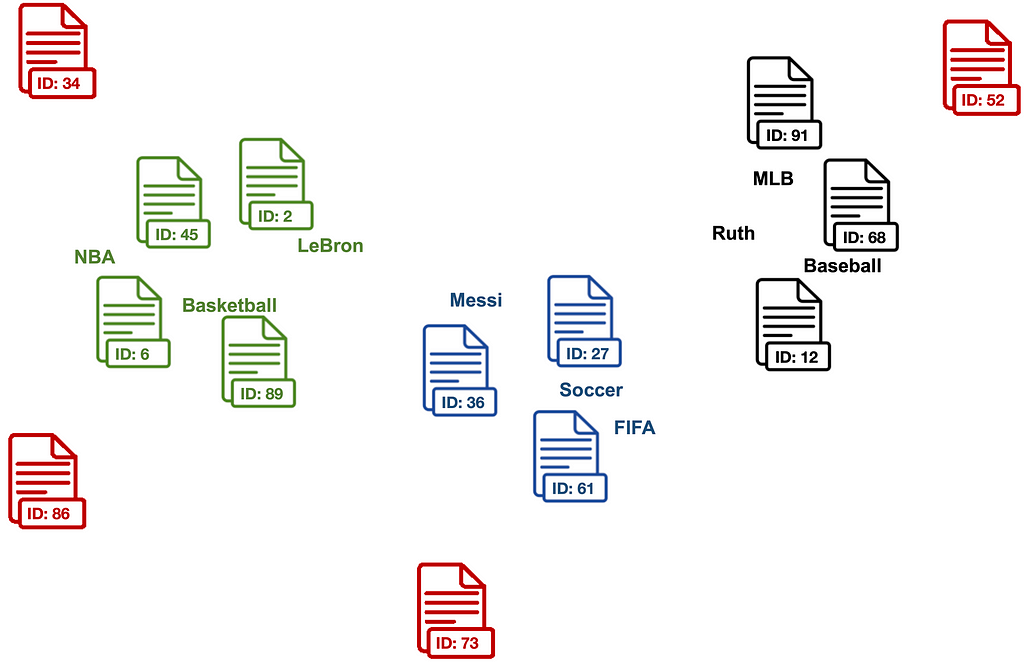
The algorithm uses LOF to clean outlier documents from each set of candidate documents that may be related to some of the descriptive keywords but do not properly match the intended classification category.
5. Compute the Centroid of the Outlier Cleaned Document Vectors as Label Vector for Each Classification Category
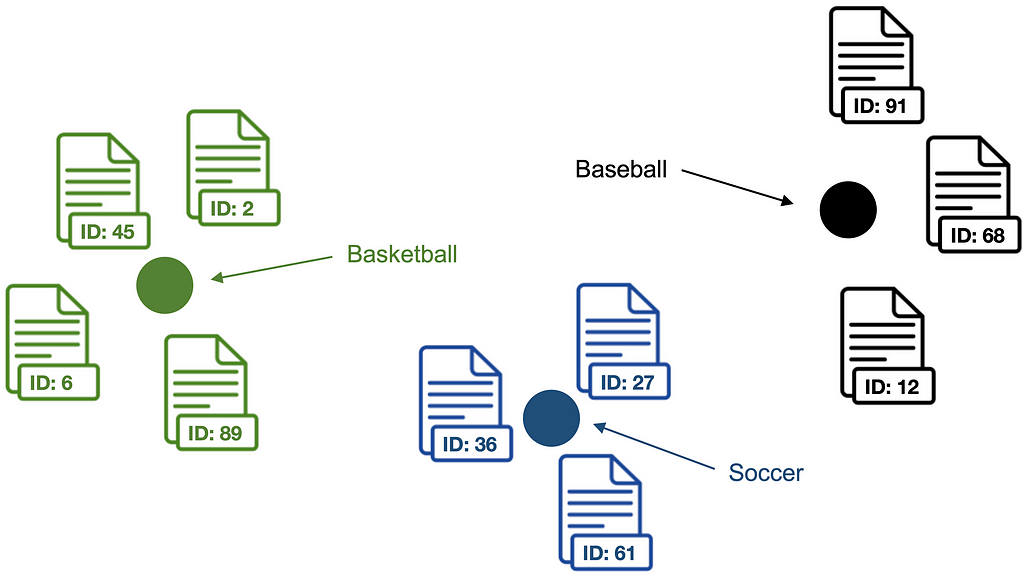
To get embedding representations of classification categories, we compute label vectors. Later, the similarity of documents to label vectors will be used to classify text documents. Each label vector consists of the centroid of the outlier cleaned document vectors for a category. The algorithm computes document rather than keyword centroids since experiments showed that it is more difficult to classify documents based on similarities to keywords only, even if they share the same vector space.
6. Text Document Classification
The algorithm computes label vector <-> document vector similarities for each label vector and document vector in the dataset. Finally, text documents are classified as category with the highest label vector <-> document vector similarity.
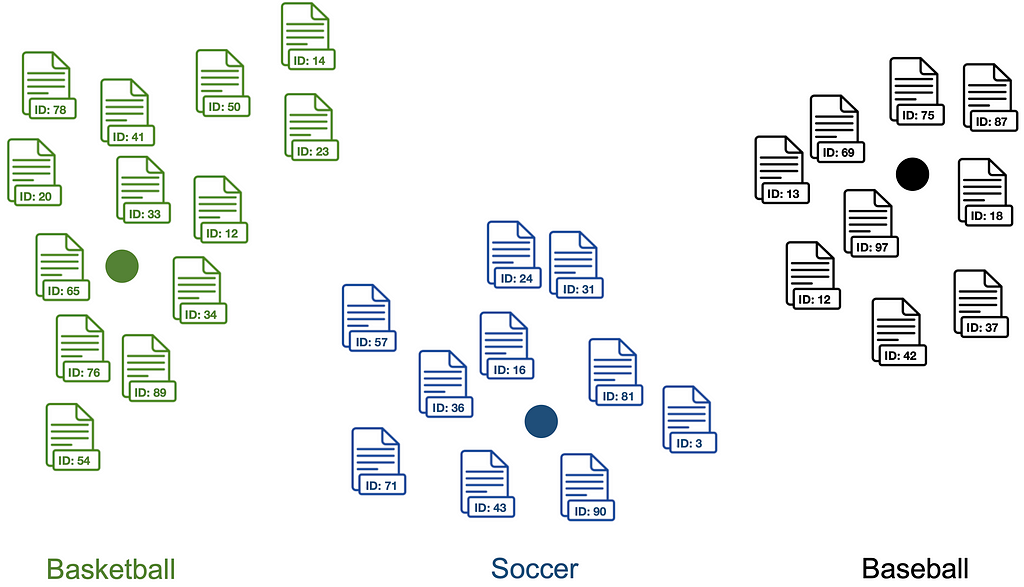
Lbl2Vec Tutorial
In this tutorial we will use Lbl2Vec to classify text documents from the 20 Newsgroups dataset. It is a collection of approximately 20,000 text documents, partitioned evenly across 20 different newsgroups categoties. In this tutorial, we will focus on a subset of the 20 Newsgroups dataset consisting of the categories “rec.motorcycles”, “rec.sport.baseball”, “rec.sport.hockey” and “sci.crypt”. Furthermore, we will use already predefined keywords for each classification category. The predefined keywords can be downloaded here. You can also access more Lbl2Vec examples on GitHub.
Installing Lbl2Vec
We can install Lbl2Vec using pip with the following command:
pip install lbl2vec
Reading the Data
We store the downloaded “20newsgroups_keywords.csv” file in the same directory as our Python script. Then we read the CSV with pandas and fetch the 20 Newsgroups dataset from Scikit-learn.
Preprocessing the Data
To train a Lbl2Vec model, we need to preprocess the data. First, we process the keywords to be used as input for Lbl2Vec.

We see that the keywords describe each classification category and the number of keywords varies.
Furthermore, we also need to preprocess the news articles. Therefore, we word tokenize each document and add gensim.models.doc2vec.TaggedDocument tags. Lbl2Vec needs the tokenized and tagged documents as training input format.

We can see the article texts and their classification categories in the dataframe. The “tagged_docs” column consists of the preprocessed documents that are needed as Lbl2Vec input. The classification categories in the “class_name” column are used for evaluation only but not for Lbl2Vec training.
Training Lbl2Vec
After preparing the data, we now can train a Lbl2Vec model on the train dataset. We initialize the model with the following parameters:
- keywords_list : iterable list of lists with descriptive keywords for each category.
- tagged_documents : iterable list of gensim.models.doc2vec.TaggedDocument elements. Each element consists of one document.
- label_names : iterable list of custom names for each label. Label names and keywords of the same topic must have the same index.
- similarity_threshold : only documents with a higher similarity to the respective description keywords than this treshold are used to calculate the label embedding.
- min_num_docs : minimum number of documents that are used to calculate the label embedding.
- epochs : number of iterations over the corpus.
Classification of Text Documents
After the model is trained, we can predict the categories of documents used to train the Lbl2Vec model.
[Out]: F1 Score: 0.8761506276150628
Our model can predict the correct document categories with a respectable F1 Score of 0.88. This is achieved without even seeing the document labels during training.
Moreover, we can also predict the classification categories of documents that were not used to train the Lbl2Vec model and are therefore completely unknown to it. To this end, we predict the categories of documents from the previously unused test dataset.
[Out]: F1 Score: 0.8610062893081761
Our trained Lbl2Vec model can even predict the classification categories of new documents with a F1 Score of 0.86. As mentioned before, this is achieved with a completely unsupervised approach where no label information was used during training.
For more details about the features available in Lbl2Vec, please check out the Lbl2Vec GitHub repository. I hope you found this tutorial to be useful.
Summary
Lbl2Vec is a recently developed approach that can be used for unsupervised text document classification. Unlike other state-of-the-art approaches it needs no label information during training and therefore offers the opportunity to run low-cost text classification for unlabeled datasets. The open-source Lbl2Vec library is also very easy to use and allows developers to train models in just a few lines of code.
Sources
- Schopf, T.; Braun, D. and Matthes, F. (2021). Lbl2Vec: An Embedding-based Approach for Unsupervised Document Retrieval on Predefined Topics, (2021), Proceedings of the 17th International Conference on Web Information Systems and Technologies
- https://github.com/sebischair/Lbl2Vec
Unsupervised Text Classification with Lbl2Vec was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/30Xq08Q
via RiYo Analytics







No comments