https://ift.tt/3FoPydS In real-case applications, machine learning is not as common as we would expect: let’s explore why. Photo by Alice...
In real-case applications, machine learning is not as common as we would expect: let’s explore why.

Machine Learning is the talk of the town. Models have shown that with today’s technology they are capable of achieving jaw-dropping results. Unfortunately, the lab and the real world are two different playfields: Algorithms work great if the data they see is similar to the ones they were trained on, but this is not always the case. Data can shift due to a number of factors:
- Scarcity of labeled data — annotating data is expensive, so the model is trained on what’s available hoping that it fully represents the use case;
- Time — e.g. new terms emerge in a language, previous facts are no longer valid, etc.;
- Geography — e.g. British vs American English, native vs non-native speakers, etc.;
- Format — e.g. short documents vs larger ones, jargon from one domain vs another domain, etc.
Generalizing is the real challenge we face in the era of omnipresent AI. To learn how to face this challenge, we tested several algorithms on a generalization task, to see how they responded and we collected our findings in this article.
1. The setting
We wanted to mimic what would happen in a real-case scenario, so we searched for a dataset that was similar to those with which companies work. The Consumer Complaint Database seemed a perfect choice: It contains thousands of anonymized complaints — short texts in which a user complains about a financial service — organized in nine classes and fifty subclasses, i.e. the services that are affected by the complaint. For example, for the class “Student debt” the dataset contains examples about the subclasses “Federal student loan servicing” and “Private student loan”. We worked on a set of 80k complaints — the ones submitted from July 2020 to January 2021.
It is important to notice that this database is not error-free. Since users can only pick one class for each complaint, human error can always creep in. Some complaints are erroneously classified, some are arbitrarily classified (can be about class x but also class y) and some seem to be classified based on information that is not available in the text. Keep in mind that machine learning models will reflect the provided classification, even if it makes no sense.
Take the following complaint:
Can’t connect to XXXX, XXXX? Also, it used to work like 2 months ago.
This is classified as “Money transfer, virtual currency, or money service” but we have no clue why. We can suppose that in the anonymization some important piece of information was lost — but we can’t tell for sure.
Or take this complaint:
They have illegally marked me as past due, and haven’t corrected it.
The latter is classified as “Credit card or prepaid card”, but it might also have been classified as “Debt collection” — maybe even more rightfully so.
2. The experiments
We were interested in running two experiments: one represents what is usually done in the lab phase, and the other what happens once a model goes into production. For the lab phase, we wanted to see the potential of each algorithm we evaluated, to get a sense of how well it performs in perfect conditions. For the production phase, we wanted to challenge the algorithms on data shifting and check if performances take a hit. We divided the models into two families: data-driven approaches — which rely on machine learning techniques and use only the raw text as features - and knowledge-driven approaches - which rely on the creation of human-made heuristics for each class.
For the experiments presented in this article, we decided to compare the models using F1 Score. This measure provides an indicator of the solution’s quality since it takes into consideration both precision and recall. These are the findings we collected:
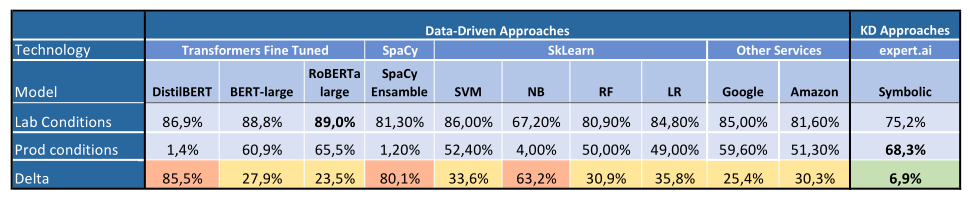
We can notice how machine learning algorithms experience a greater loss when dealing with data shift, and that the knowledge-driven approach is the one that minimizes this loss.
2.1. Lab conditions
The lab conditions experiment was performed by using the whole dataset and splitting it into training and test set. What comes out from this experiment is no surprise: Larger machine learning models perform best, with Transformers leading the way. Other data-driven models still perform well, thanks to the large number of training examples. Another model was tested in this phase: expert.ai AutoML combines symbolic and subsymbolic features and can be considered a hybrid algorithm. This model produced promising results, performing slightly less than RoBERTa-Large.
We also tested a knowledge-driven approach: expert.ai Symbolic model. This consists of a collection of human-curated rules, created on top of a text analysis engine. The model was developed in a few days of work. With a longer effort it could have reached better performances, but for the experiment to be fair, each approach had to take about the same amount of time.
2.2. Production conditions
To represent what would happen in a production environment, we tested our models on a generalization task, inserting a data shift from the training set to the test set. The algorithms were first trained on a selection of the least represented subclasses and then tested on the remaining subclasses — with a minimum of 50 training texts per class. For instance, we trained the model on “Federal student loan debt” but tested the model on the other subclasses for “Debt collection”:
To make things more difficult, we also inserted a few-shot training constraint: We provided 1.4k complaints for training and then we tested on 8k complaints. Here is the dataset used. Stressing the algorithms can give us an idea of how trustworthy they can be in the real world.
This produced an overturning in results: Transformers did not perform best in this scenario, with DistilBERT providing especially low performance. The best-performing model was expert.ai Symbolic. As said, this model is composed of a set of human-curated rules. Having a human in the loop helps greatly at generalizing since humans already possess information about the world, whilst machine learning can only learn from provided examples. Also, expert.ai technology itself helps generalization. When developing rules, one can check expert.ai Knowledge Graph, which is a large collection of ready-to-use concepts, organized and easy to navigate.
3. Conclusion
Looking at generalization tasks, we can notice how unpredictable data-driven models become once they experience data shift. In the lab, data-driven approaches work really well — that comes as no surprise. But when we expect such models to generalize in situations similar to real life, we can see that a more grounded understanding is required. On the other hand, a knowledge-driven approach makes it easier to generalize, since a human knows that when seeing the case X1, cases X2, X3, …, Xn can also be expected.
In the lab, we’ve also had a chance to test the hybrid expert.ai AutoML — a model that performs similarly to Transformers and yet is much lighter. Given these promising preliminary results, we should keep exploring these combinations of data-driven and knowledge-driven approaches.
A huge thank you to Raul Ortega and Jose Manuel Gómez Pérez who performed most of the experiments here collected.
Can you trust your model when data shifts? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3H9rI6p
via RiYo Analytics







No comments