https://ift.tt/3ocaDC8 How to establish a baseline with a no-ML “model” Photo by Alexis Fauvet on Unsplash What is this about? This ...
How to establish a baseline with a no-ML “model”

What is this about?
This is the first part of a tutorial on setting up a text summarisation project. For more context and an overview of this tutorial, please refer back to the introduction.
In this part we will establish a baseline using a very simple “model”, without actually using machine learning (ML). This is a very important step in any ML project, as it allows us to understand how much value ML adds over the time of the project and if it’s worth investing in it.
The code for the tutorial can be found in this Github repo.
Data, data, data …
Every ML project starts with data! If possible, we always should use data related to what we want to achieve with a text summarisation project. For example, if our goal is to summarise patent applications we should also use patent applications to train the model. A big caveat for an ML project is that the training data usually needs to be labelled. In the context of text summarisation that means we need to provide the text to be summarised as well as the summary (the “label”). Only by providing both can the model learn what a “good” summary looks like.
In this tutorial we will use a publicly available dataset, but the steps and code remain exactly the same if we used a custom/private dataset. And again, if you have an objective in mind for your text summarisation model and have corresponding data, please use your data instead to get the most out of this.
The data we will use is the arXiv dataset which contains abstracts of arXiv papers as well as their titles. For our purpose we will use the abstract as the text we want to summarise and the title as the reference summary. All the steps of downloading and pre-processing the data can be found in this notebook. The dataset was developed as part of this paper and is licenced under the Creative Commons CC0 1.0 Universal Public Domain Dedication.
Note that the data is split into three datasets, training, validation, and test data. If you’d like to use your own data, make sure this is the case too. Just as a quick reminder, this is how we will use the different datasets:
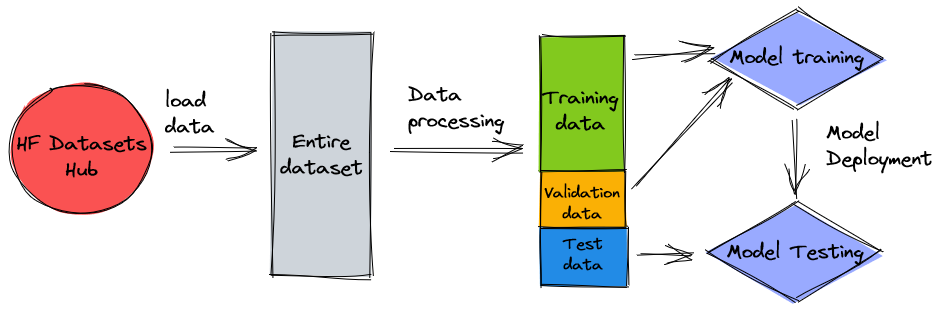
Naturally, a common question at this point is: How much data do we need? And, as you can probably already guess, the answer is: It depends. It depends on how specialised the domain is (summarising patent applications is quite different from summarising news articles), how accurate the model needs to be to be useful, how much the training of the model should cost, etc. We will return to this question at a later point when we actually train the model, but the short of it is that we will have to try out different dataset sizes once we are in the experimentation phase of the project.
What makes a good model?
In many ML projects it is rather straightforward to measure a model’s performance. That's because there is usually little ambiguity around whether the model’s result is correct. The labels in the dataset are often binary (True/False, Yes/No) or categorical. In any case, it’s easy in this scenario to compare the model’s output to the label and mark it as correct or incorrect.
When generating text this becomes more challenging. The summaries (the labels) we provide in our dataset are only one way to summarise text. But there are many possibilities to summarise a given text. So, even if the model doesn’t match our label 1:1, the output might still be a valid and useful summary. So how do we compare the model’s summary with the one we provide? The metric that is used most often in text summarisation to measure the quality of a model is the ROUGE score. To understand the mechanics of this metric I recommend this blog post. In summary, the ROUGE score measures the overlap of n-grams (contiguous sequence of n items) between the model’s summary (candidate summary) and the reference summary (the label we provide in our dataset). But, of course, this is not a perfect measure and to understand its limitations, I quite like this post.
So, how do we calculate the ROUGE score? There are quite a few Python packages out there to compute this metric and to ensure consistency, we should use the same method throughout our project. Because we will, at a later point in this tutorial, be quite l̶a̶z̶y̶ smart and use a training script from the Transformers library instead of writing our own, we can just peek into the source code of the script and copy the code that computes the ROUGE score:
By using this method to compute the score we ensure that we always compare apples to apples throughout the project.
Note that this function will compute several ROUGE scores: rouge1, rouge2, rougeL, and rougeLsum (The “sum” in rougeLsum refers to the fact that this metric is computed over a whole summary, while rougeL is computed as the average over individual sentences). So, which ROUGE score we should use for our project? Again, we will have to try different approaches in the experimentation phase. For what it’s worth, the original ROUGE paper states that “ROUGE-2 and ROUGE-L worked well in single document summarization tasks” while “ROUGE-1 and ROUGE-L perform great in evaluating short summaries”.
Creating the baseline
Next up we want to create the baseline by using a simple, no-ML model. What does that mean? Well, in the field of text summarisation, many studies use a very simple approach: They take the first n sentences of the text and declare it the candidate summary. They then compare the candidate summary with the reference summary and compute the ROUGE score. This is a simple yet powerful approach which we can implement in a few lines of code (the entire code for this part can be found in this notebook):
Note that we use the test dataset for this evaluation. This makes sense because once we train the model we will also use the same test dataset for final evaluation. We also try different numbers for n, i.e. we start with only the first sentence as candidate summary, then the first two sentences, and finally the first three sentences.
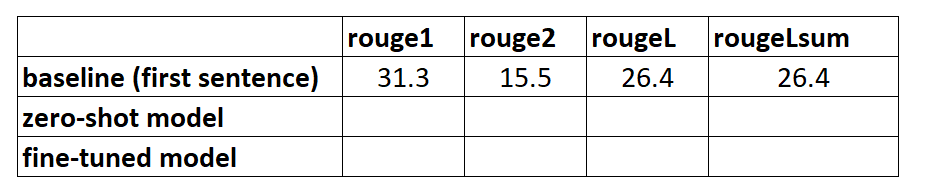
And these are the results for our first “model”:

We can see that the scores are highest with only the first sentence as the candidate summary. This means that taking more than one sentence makes the summary to verbose and leads to a lower score. So that means we will use the scores for the one-sentence summaries as our baseline.
It’s important to note that, for such a simple approach, these numbers are actually quite good, especially for the rouge1 score. To put these numbers in context we can check this page, which shows the scores of a state-of-the-art model for different datasets.
Conclusion and what’s next
We have introduced the dataset which we will use throughout the summarisation project as well as a metric to evaluate summaries. We then created the following baseline with a simple, no-ML model:
In the next part we will be using a zero-shot model, i.e. a model that has been specifically trained for text summarisation on public news articles. However, this model won’t be trained at all on our dataset (hence the name “zero-shot”).
I will leave it to you as homework to guess on how this zero-shot model will perform compared to our very simple baseline. On the one hand, it will be a much more sophisticated model (it’s actually a neural network), on the other it’s only used to summarise news articles, so it might struggle with the patterns that are inherent to the arXiv dataset.
Setting up a Text Summarisation Project (Part 1) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3pn7WNH
via RiYo Analytics








No comments