https://ift.tt/3ehGhsi I learn best when I have to describe something from the ground up! In “reinventing” articles, I’ll try to describe t...
I learn best when I have to describe something from the ground up! In “reinventing” articles, I’ll try to describe the mathematical intuitions necessary to implement a technology for yourself!
I didn’t love any of the LSTM graphics I found, so I made my own! Feel free to reuse in any context without attribution (no rights reserved).
Why LSTMS?
RNNs allow us to apply our toolkit of neural network methods to timeseries problems. The original RNN implementation, however, often struggled to learn long-term temporal dependencies. LSTMs introduce a vector of cell state or “memory” to improve the network’s capacity to learn possible relationships between features even when separated by hundreds or thousands of timepoints.
Where we are going…
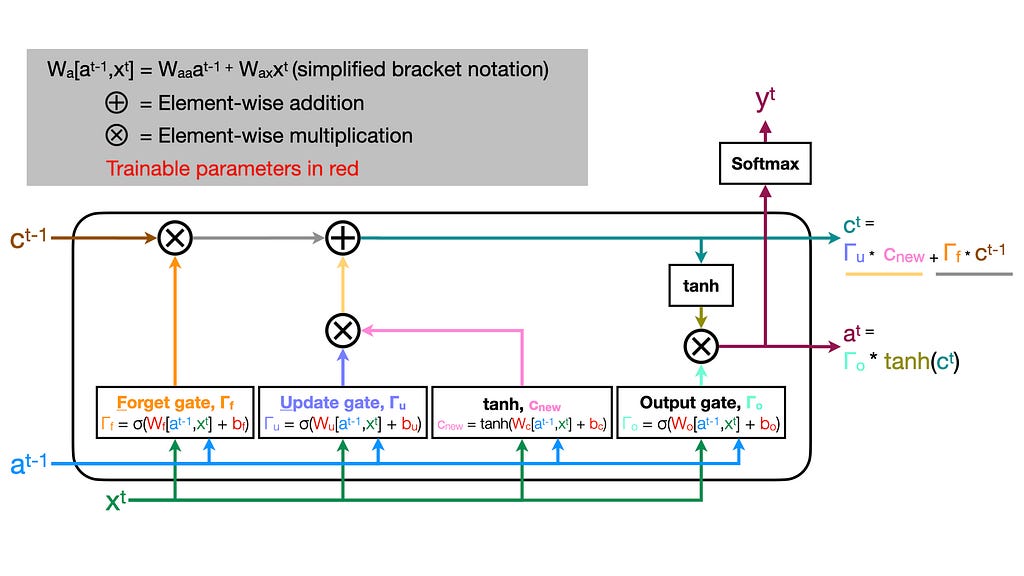
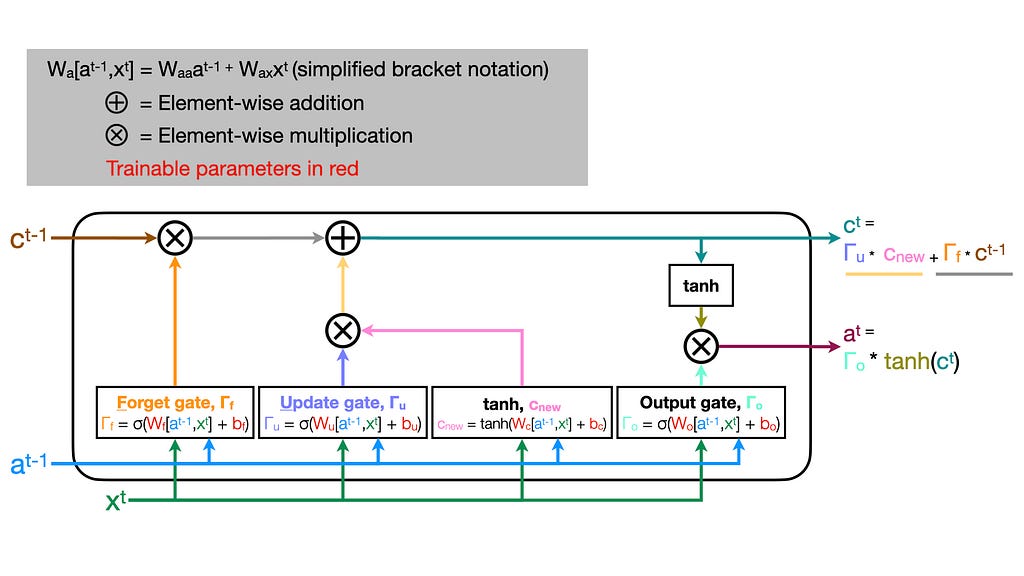
Each LSTM unit outputs two values: a vector of a(ctivations) and a memory vector of c(ell) state. Intuitively, this allows our network to maintain a memory of relevant features from timeseries data. The network can hold on to information and reference important context at later timepoints. We’ll walk through the pieces and discuss how each contributes to LSTM function!
Sigmoid and tanh
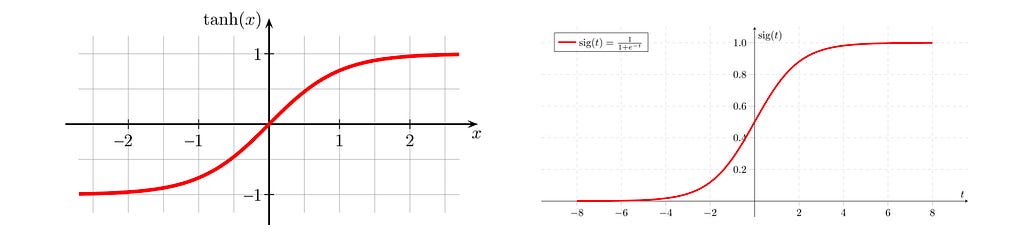
To understand LSTM behavior, we have to understand the nonlinear functions used under the hood. The sigmoid and hyperbolic tangent function are visually similar. Critically, though, the sigmoid function does not take on negative values. The tails of the sigmoid are equal to approximately zero (for negative values of the domain, x < 0) and approximately one (for positive values of the domain, x > 0). For this reason, we can consider the sigmoid to be a boolean selector that toggles between values close to zero and values close to 1.
In an LSTM cell, sigmoids are applied to values before an element-wise multiplication. This allows us to remove elements where the sigmoid is 0 and preserve values where the value is 1.
Creating new memories
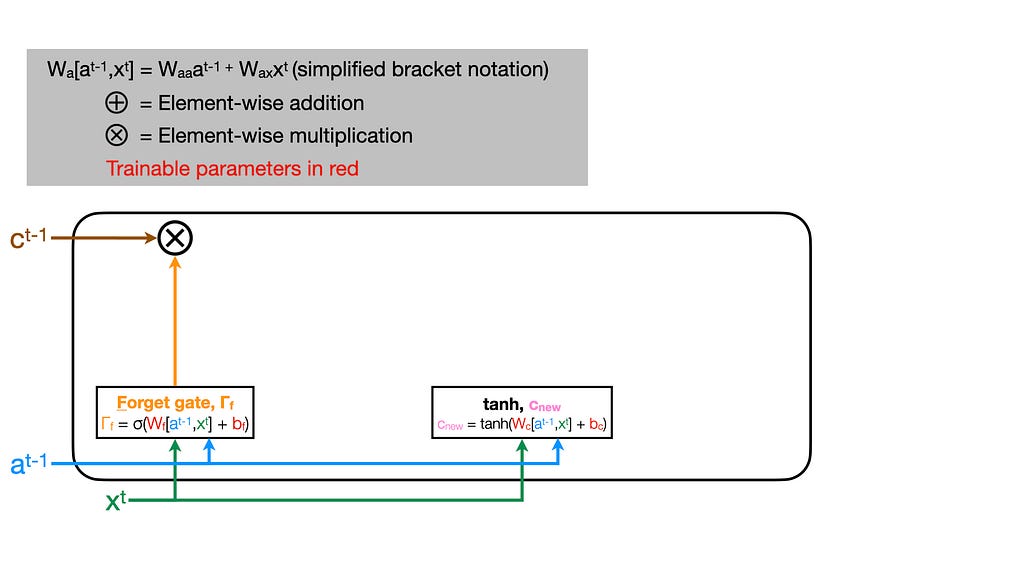
Let’s start off at timepoint t by creating a new candidate cell state memory vector. Later, we’ll consider using these values to overwrite the cell state vector from the previous cell (t-1). Here, we’ll use our hyperbolic tangent function (tanh) to calculate a nonlinear activation of a weighted (W_c) sum of the current features (x_t) and the previous cell’s activation (a_t-1) plus a bias term (b_c).
Don’t be intimidated! This nonlinearity applied to a weighted sum builds on the same intuitions as a unit in a multilayer perceptron. We learn the weight matrices and bias term through gradient descent. The activation is just a tanh rather than the activation functions we might see more commonly in other contexts like relu!
We’ll call this new candidate cell state memory vector c_new.

The forget gate
Now, we need to figure out how we will change the cell state memory vector that we got from the previous cell (c_t-1). First, let’s choose which elements we want to forget.
The forget gate determines which elements to forget/remember from the previous cell’s state memory vector (c_t-1).
The logic is exactly the same as we applied before to determine our new candidate memory vector. This time, though, we’ll be using a separate weight matrix (W_f) and bias term (b_f). We want this gate to determine which values from c_t-1 are kept or dropped, so we want most of the values to be near one (keep) or zero (drop). As described above, we achieve this using a sigmoid activation that returns mostly zeros (negative tail) and ones (positive tail) followed by an element-wise multiplication with c_t-1!
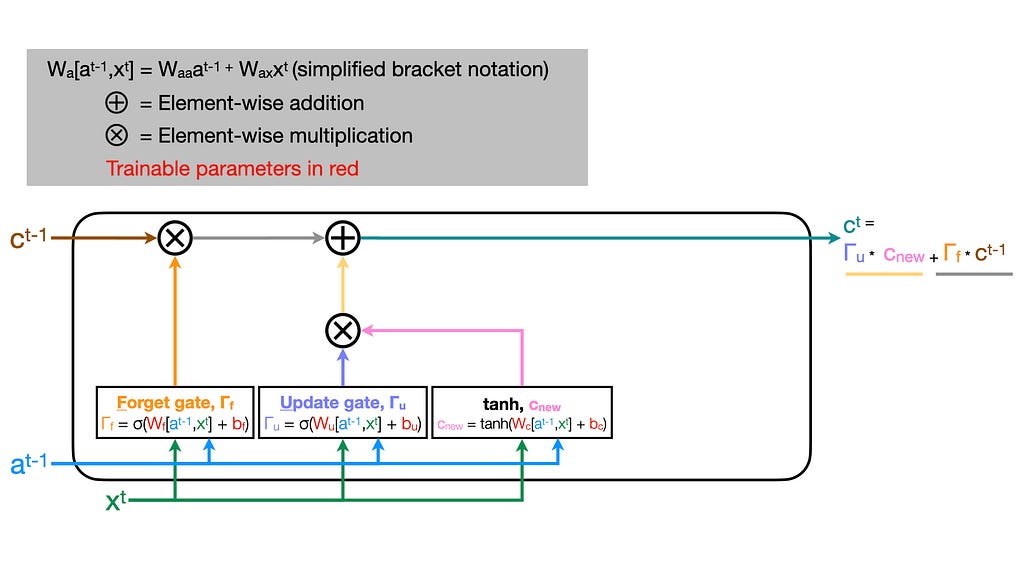
The update gate
Completing our cell’s state memory vector, we will now use the same sigmoid selector logic but applied with another trainable matrix (W_u) and bias (b_u). The result will be multiplied element-wise with the candidate cell state memory vector we computed before (c_new).
The update gate determines which elements we want to ignore/add from our candidate cell state memory vector (c_new).
Now, we have c_t-1 without the elements we want to forget and c_new with only the new values we want to add to memory. Element-wise summing these two quantities together yields the updated cell state memory vector c_t that we’ll pass to the next LSTM unit!
The output gate
Finally, we will compute an activation (a_t) to pass to the next cell. Luckily, the logic is all recycled! We’ll pass our cell state memory vector (c_t) through a final nonlinear hyperbolic tangent function. Then, we’ll apply a sigmoid — just like for the other gates — but using a final trainable set of weights (W_o) and biases (b_o). An element-wise multiplication of the tanh outputs and the output gate values yields our cell’s activation (a_t): the second value passed to the next cell (t+1).
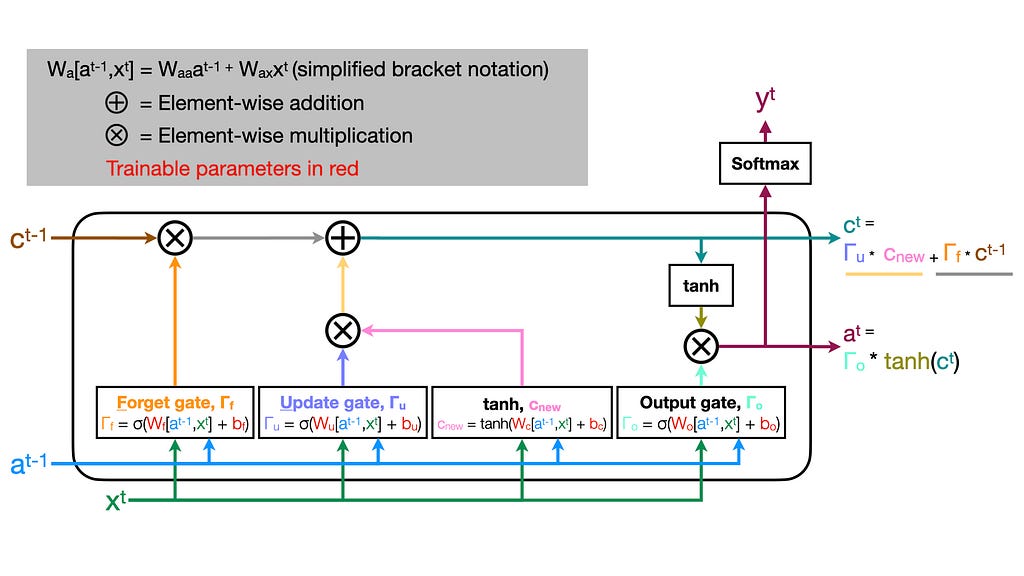
The optional sequence-to-sequence return
If we want, we can also predict a quantity at each timepoint. For instance, using our activation (a_t) we can apply a final sigmoid to predict a binary value or a softmax to perform multiclass classification (y_t). This allows our LSTM layer to return a sequence of predictions of the same length as the input sequence.
… where we ended up!
You can imagine the complex nonlinear temporal relationships that this architecture can learn! Chaining these cells together enables the modeling of complicated timeseries dynamics of arbitrary duration.
Give the article a clap if the text or visuals helped explain LSTMs! Leave a comment if you have a correction or would like to recommend additional clarification. Thanks for reading!
Reinventing the LSTM: Long short-term memory from scratch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3pqehsY
via RiYo Analytics






{kind=link}
{kind=link}
ليست هناك تعليقات