https://ift.tt/3EMkSTw Natural Language Processing Can you identify biomedical entities in research titles and abstracts? Photo by Adrie...
Natural Language Processing
Can you identify biomedical entities in research titles and abstracts?

In the past two competitions, you predicted video popularity and viral tweets with data science, now it’s time for a whole new challenge!
Bitgrit has released a NLP Challenge with a prize pool of $100,000 💵!
The first phase of this competition ends on 23rd December 2021, so sign up to get access to the data, and follow along with this article to get started!
The goal 🥅
Develop a NLP model that identifies mentions of biomedical 🧬 entities in research abstracts.
There are two parts to this competition.
(The following information is taken from the website)
Part 1: Given only an abstract text, the goal is to find all the nodes or biomedical entities (position in text and BioLink Model Category).
As stated in the website, The type of the biomedical entities comes from the BioLink Model Categories, and can be one and only one of the following
- DiseaseOrPhenotypicFeature
- ChemicalEntity
- OrganismTaxon
- GeneOrGeneProduct
- SequenceVariant
- CellLine
Part 2: Given the abstract and the nodes annotated from it, the goal is to find all the relationships between them (pair of nodes, BioLink Model Predicate and novelty).
From the description of the competition:
Each phase of the competition is designed to spur innovation in the field of natural language processing, asking competitors to design systems that can accurately recognize scientific concepts from the text of scientific articles, connect those concepts into knowledge assertions, and determine if that claim is a novel finding or background information.
This article will be focusing on the first part, which is to identify biomedical entities.
What does the data look like?
📂 LitCoin DataSet
├── abstracts_train.csv
├── entities_train.csv
├── relations_train.csv
└── abstracts_test.csv
A little info about the data:
- abstracts_train is where you’ll find the title and abstract of biomedical journal articles.
- entities_train has the 6 categories that you need to predict, along with the offset positions of the word in the string with the title abstract combined.
- relations_train is for phase 2 of the competition, so don’t worry about this data for now.
Relationship between the data
The relationship is simple in this dataset, entities is related to abstracts through the abstract_id, and to relations through the entity_ids
Below is a visualization of the relationship.

More info about the data in the guidelines section of the competition.
Now that you have an idea about the goal and some information about the data given to you, it’s time to get your hands dirty.
All the code can be found in Google collab or on Deepnote.
Named Entity Recognition (NER)
There are different NLP tasks that solve different problems — text summarization, part of speech tagging, translation, and more.
For this particular problem, we are solving the problem of Named Entity Recognition, specifically on biomedical entities.
What is it?
According to good ol’ wikipedia, NER is defined as
a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
For example, take the following sentence:
“Albert Einstein is a physicist who was born in Germany, on March 14, 1870”
If you read it, you’d immediately be able to classify the named entities into the following categories:
- person: Albert Einstein
- job title: physicist
- location: Germany
- date: March 14, 1870
While it was simple for us humans to identify and categorize, computers need NLP to comprehend human language.
This is what NER does – it identifies and segments the main entities in a text. The entire goal is that computers extract relevant information from a large pile of unstructured text data.
With enough data, you can train NER models that are able to classify and segment these entities with a high accuracy. And those models are able to produce visualizations like below.

How?
There are different libraries and packages such as spaCy and NLTK that allow you to perform NER, and many pretrained NER models with different approaches are also available online.
Since our problem is more specific for biomedical text, we will be using scispaCy, a Python package containing spaCy models for processing biomedical, scientific or clinical text.
scispaCy comes with the following pre-trained models for you to use.
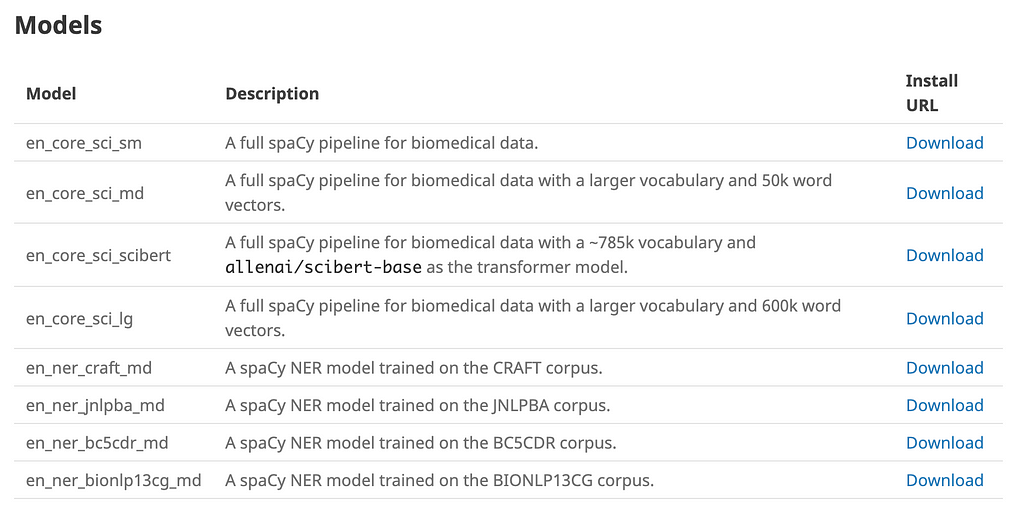
Notice there are 4 NER models that are trained on different corpus of biomedical articles.
The documentation also provides us the entity types that the pretrained model predicts.
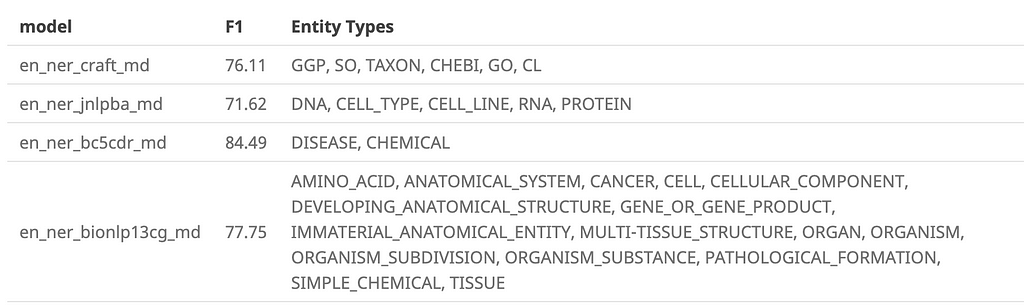
Knowing the entity types and what they represent will be useful soon. But for now, let us install the necessary libraries and dive into the code.
Installing libraries and models
To use scispacy, we’ll need spacy to be at least version 3.0.1
Then, we’ll install scispacy and the four models.
Load Libraries
We’ll then import the necessary libraries, and the models as well.
Import the data
The csv files are seperated by tabs, so we use the sep parameter to specify that.
EDA
Abstract data
From the output, we have exactly 400 title and abstract data to use for predicting entity types.
Entities Data
A peek at our entities data shows us we have over 13k entities that were extracted from the title and abstract string.
Checking for missing values
Using a helper function I coded, there are no missing values in the dataset.
How many Entity types are there?
With a simple bar plot, it seems that GeneOrGeneProduct is the most common type.
Now that we understand our data a little bit better, let’s start looking at what scispaCy can do.
scispaCy in action
Let’s start with taking the first title and abstract string.
The first string has 717 characters.
Printing it below, we can see that string.
Loading the model
Now let’s load up the first model which is trained on the BioNLP13CG Corpus — bionlp13cg_md, and pass our text into the model.
We now have a document object that contains information about the entities.
Getting entities
Calling .ents on it, we can see the entities it extracted.
Visualizing entities with labels
We can even have spaCy visualize the entities and the labels right on our title+abstract string. This is done with the displacy function
The document entities also has the attributes text, label_, start_char, and end_char which are important information we need for this challenge.
And voila! You’ve extracted entities from a biomedical paper title and abstract with a pretrained NER model from scispaCy!
Now let’s see what entities the other 3 models extracts.
CRAFT Corpus model
JNLPBA corpus model
BC5CDR corpus model
Now let’s take all these entity categorizations and put them all together.
Now let’s create a data frame for our combined extracted entities, with the text, label, starting character, and the ending character.
Then, we compare it with the entity type given in our training data.
We can compare them side by side with an inner join between the two data frames.
As for determining which to map to, you need to go through the biolink model, along with the documentation of the four corpus.
For example, based on the CRAFT corpus article, these are what the entity types stand for
- GGP — GeneOrGenePhenotype
- SO — Sequence Ontology
- TAXON — NCBI Taxonomy
- CHEBI — Chemical Entities of Biological Interest
- GO — Gene Ontology (biological process, cellular component, and molecular function)
- CL — Cell Line
To change the values in the data, we can use the map function from pandas.
Note: SO, TAXON, and DNA are mapped to the same value because map function requires all values to be mapped to something.
The end product is similar to what you need to submit to the competition, except it’s still missing id, abstract_id, and the column names need to be renamed.
The challenge now is to do that for the rest of the title and abstracts.
Conclusion
Note that this article introduced just one approach to this problem, and I do not advocate that it’s the best solution.
Here are a some ways to improve upon the given approach
- Use the data to tune the frequency of concepts per sentence/abstract
- Correct some misclassifications based on how some categories are done in the data and from reading the CORPUS and biolink documentation
- Use data to know which ontologies to search specifically
All the best in this competition and I’ll see you in the second phase!
Want to discuss about the challenge with other data scientists? Join the discord server!
Follow the Bitgrit Data Science Publication for more articles like this!
Follow Bitgrit’s socials 📱 to stay updated on workshops and upcoming competitions!
LitCoin NLP Challenge by NCATS & NASA was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3GCvTYh
via RiYo Analytics






ليست هناك تعليقات