https://ift.tt/3pN0FXB Distillation of BERT-Like Models: The Theory Exploring the mechanisms behind the approach of DistilBERT The proce...
Distillation of BERT-Like Models: The Theory
Exploring the mechanisms behind the approach of DistilBERT
If you’ve ever trained a large NLP model like BERT or RoBERTa, you know that the process is excruciatingly long. Training such models may drag on for days because of their gargantuan size. And when it comes time to run them on small devices, you might find that you’re paying today’s ever-increasing performances with humongous memory and time costs.
Fortunately, there are ways to alleviate those pains with little effect on your model’s performances, techniques called distillation. In this article, we’ll explore the mechanisms behind the approach of DistilBERT [1], which can be used to distill any BERT-like model.
First, we’ll talk distillation in general and why we chose DistilBERT’s approach, then how to initialize the process, on with the special loss that’s used during the distillation, and finally some additional details that are relevant enough to mention separately.
Summary
I. A short introduction to DistilBERT
II. Copying the teacher’s architecture
III. Distillation loss
IV. Additional details
V. Conclusion
I. A short introduction to DistilBERT
What is distillation?
The concept of distillation is quite intuitive: it is the process of training a small student model to mimic a larger teacher model as close as possible. Distillation would be useless if we only run machine-learning models on the cluster we use to fine-tune them, but sadly, it isn’t the case. Therefore, distillation comes in whenever we want to port a model onto smaller hardware, such as a limited laptop or a cellphone, because a distilled model runs faster and takes less space.
The necessity of BERT distillation
As you might have noticed, BERT-based models are all the rage in NLP, since they were first introduced in [2]. And with increasing performances came many, many parameters. Over 110 million for BERT, to be precise, and we aren’t even talking about BERT-large. Thus, the need for distillation was apparent, since BERT was so versatile and well-performing. Furthermore, models that came after were basically built the same way, akin to RoBERTa [3], so by learning to properly distill BERT, you could kill two birds with one stone.
DistilBERT’s approach
The first paper about the distillation of BERT is the one we’ll use as inspiration, namely [1]. But others came after, like [4] or [5], so it’s only natural to wonder why we’re limiting ourselves to DistilBERT. The answer is threefold: first, it is quite simple, so it is a good introduction to distillation; second, it leads to good results; and third, it also allows for the distillation of BERT-based models.
DistilBERT’s distillation has two steps, which we’re going to detail below.
II. Copying the teacher’s architecture
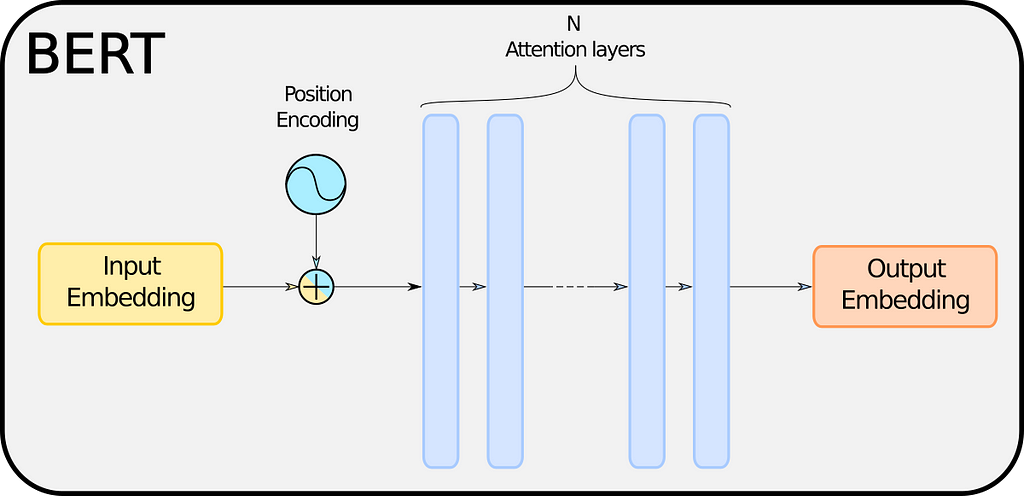
BERT’s mainly based on a succession of attention layers stacked on top of each other. Therefore, it means that the ‘hidden knowledge’ BERT learns is contained in those layers. We won’t concern ourselves with how these works, but for those who want more details, apart from the original paper [1], I can recommend this TDS article that does a wonderful job [6]. For now, we can treat attention layers as a black box, it won’t really matter to us.
From one BERT to another, the number N of layers varies, but of course the size of the model is proportional to N. It follows that the time taken to train the model and the duration of forward passes also depend on N, along with the memory taken to store the model. The logical conclusion to distill BERT is thus to reduce N.
DistilBERT’s approach is to half the number of layers, and to initialize the student’s layers from the teacher’s. Simple, yet efficient:
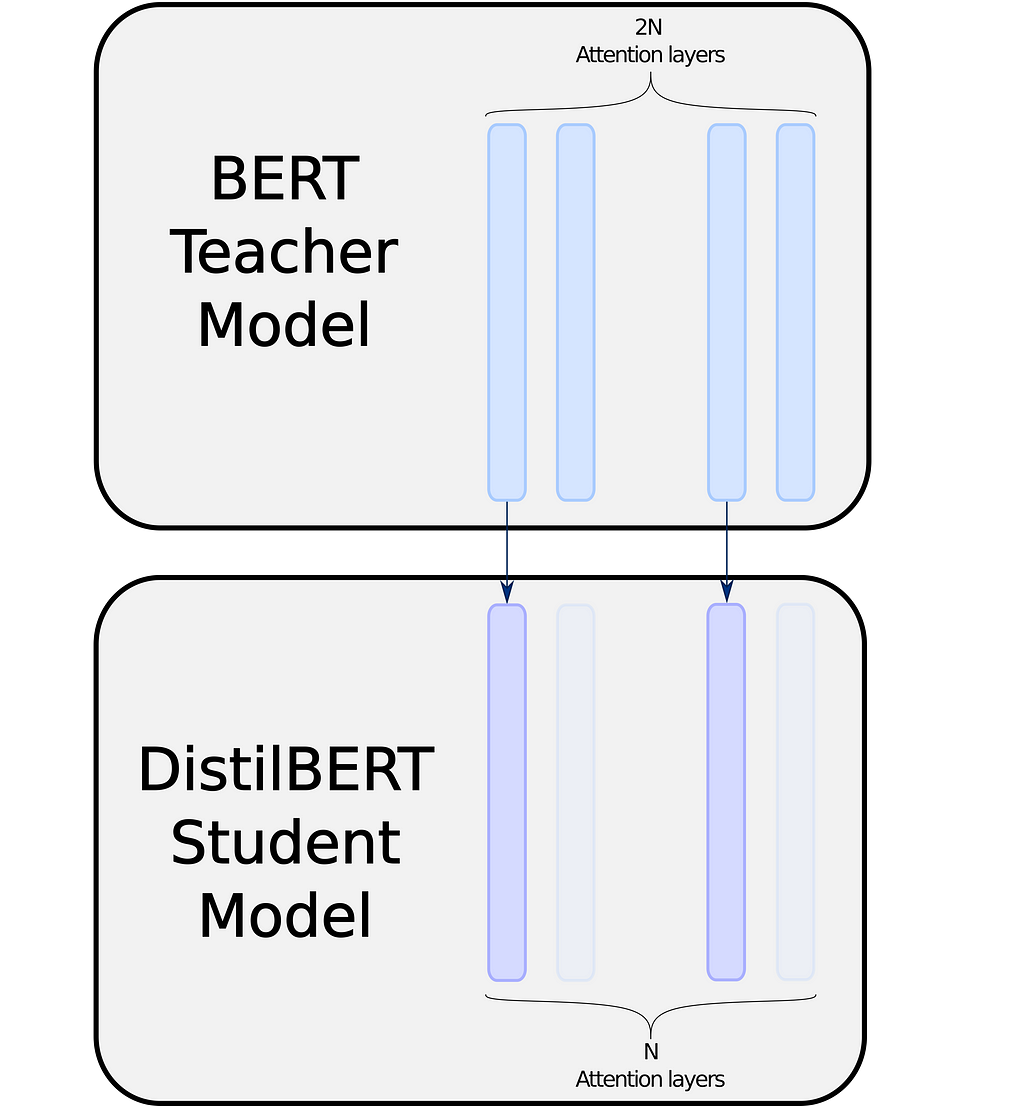
DistilBERT alternates between one copied and one ignored layer, which seems to be the best heuristic according to [4], which tried copying top or bottom layers in priority.
Thanks to huggingface’s transformers module and a little knowledge of its inner workings, this can be achieved quite easily. We will show how in another article, as we will limit ourselves to theory only in this one.
Of course, if you’re using a BERT-based model for a specific task, let’s say sequence classification, then you will also need to duplicate the teacher’s head for the student, but generally speaking, the size of BERT’s head pales in comparison to the size of its attention layers.
We now have a student model that is ready to be taught. However, the distillation process isn’t a classic fitting routine: we aren’t teaching the student to learn one pattern as we would normally do, we’re also aiming for imitation of the teacher. We’ll have to adapt our training routine in consequence, especially our loss function.
III. Distillation loss
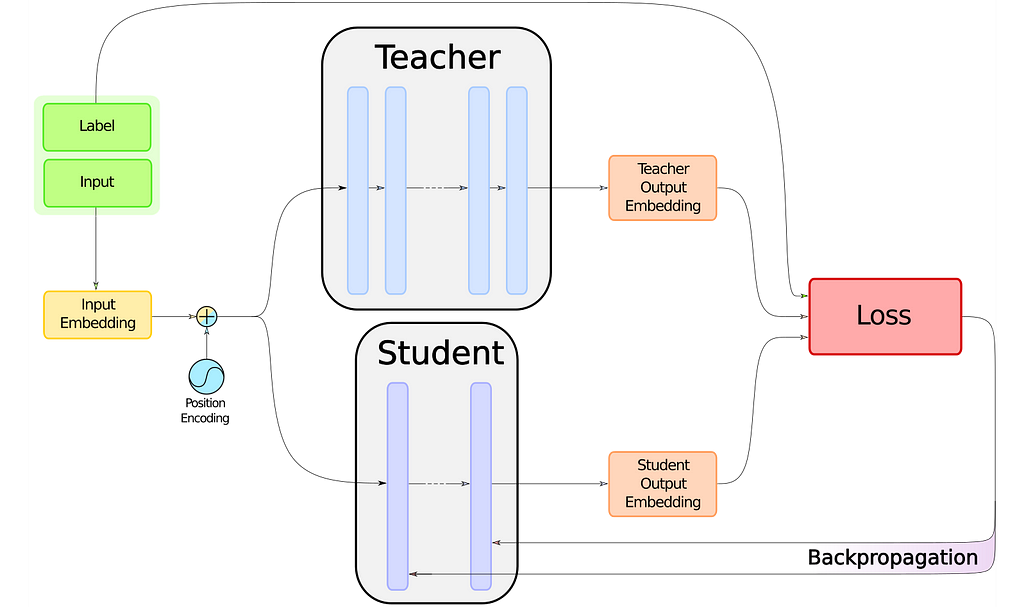
The distillation routine is illustrated by the image at the top of this article.
Our training routine is going to be based on the loss, which as said earlier seeks to achieve a couple of goals: minimize the classic loss function which the teacher trained on and mimic the teacher itself. And to make matters worse, imitating the teacher is going to require a mix of two loss functions. Therefore, we’ll start with the simpler goal: minimizing a classic loss.
Classic loss
There is not much to be said about that part: BERT-like models all work the same way, with a core outputting an embedding to a problem-specific head. The task for which the teacher was fine-tuned comes with its own loss function. To compute that loss, since the model is made of attention layers with the same problem-specific head as the teacher, we just have to plug in the student’s embeddings and the labels.
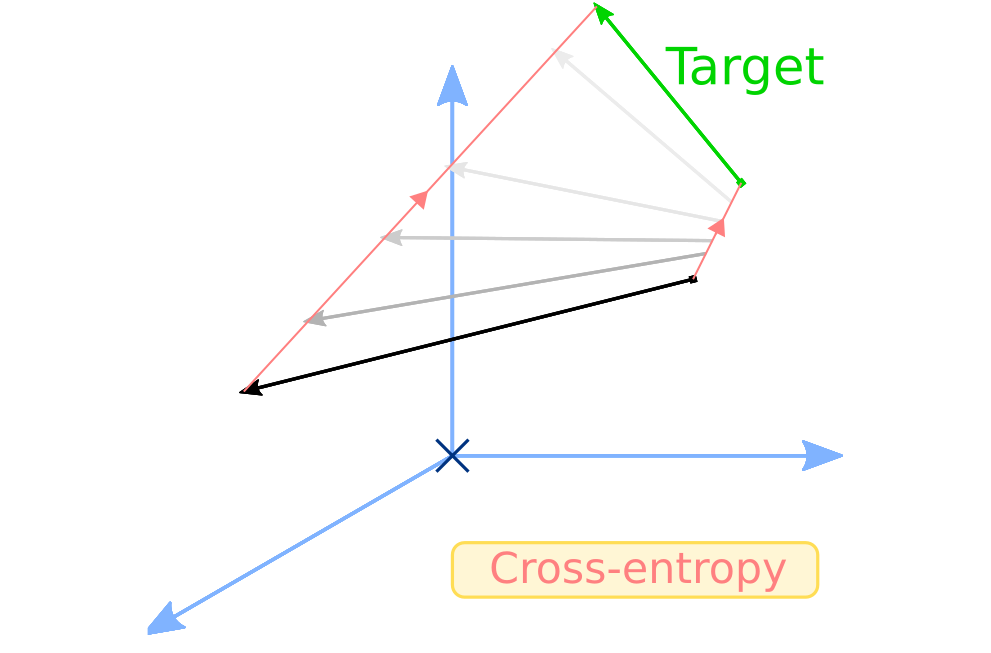
Teacher-Student cross-entropy loss
This is the first loss that aims to reduce the gap between student and teacher probability distributions. When a BERT-like model does a forward pass on an input, whether it is for masked language modeling, token classification, sequence classification, etc… it outputs logits, that are then converted through a softmax layer to a probability distribution.
For an input x, the teacher outputs:
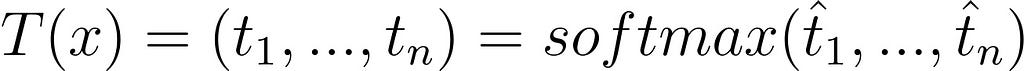
And the student outputs:
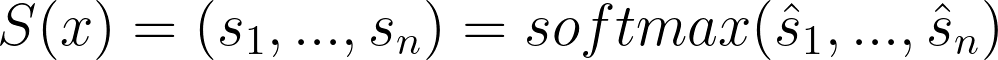
Keep in mind that softmax and the notations that come with it, we’ll get back to it later. Regardless, if we want T and S to be close, we can apply a cross-entropy loss to S with T as a target. That is what we call teacher-student cross-entropy loss:
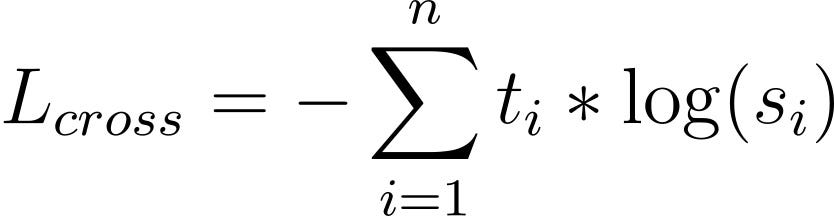
Teacher-student cosine loss
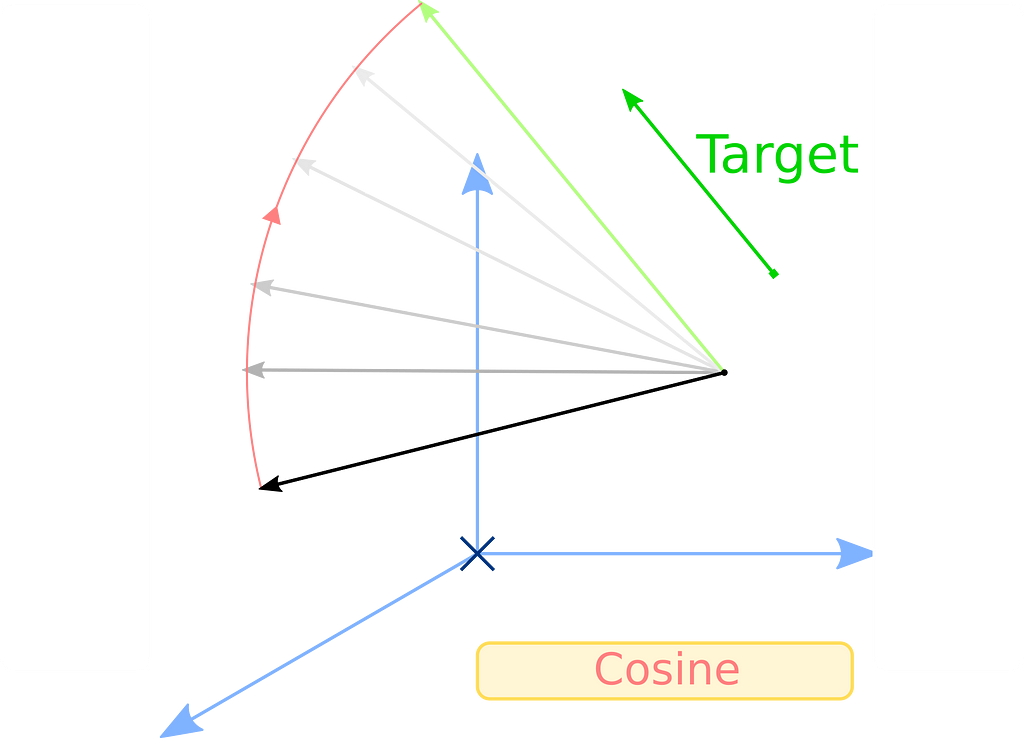
The second loss that helps the student become the master is a cosine loss. Cosine loss is interesting because rather than trying to bring a vector x equal to a target y, it merely tries two align x with y, not minding their respective norms or origin in space. We use this loss so that the hidden vectors in teacher and student models align. With the same notations as before:
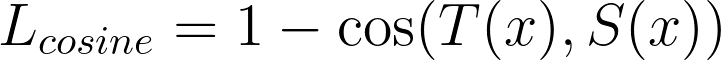
Actually, there are two versions of the cosine loss, one to align vectors and one to pull one towards the opposite of the other. In this article, we’re only interested in the first one.
Full distillation loss
The full distillation loss is a combination of the three losses mentioned above:
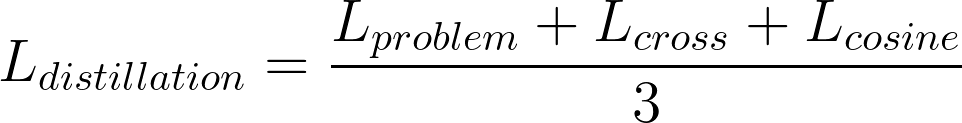
IV. Additional details
Distillation routine
After explaining the loss, the rest of the distillation routine is pretty straightforward. The model trains pretty much like any other, the only thing is that you have to run two BERT-like models in parallel. Thankfully for your GPU’s health and memory, the teacher model needn’t gradient, because backpropagation is only done only on the student. Of course, implementing the loss still needs to be done, as the distillation process, but we’ll cover it in an article down the road.
Temperature
As promised, let us get back to the notation used in III. Teacher-Student cross-entropy loss:
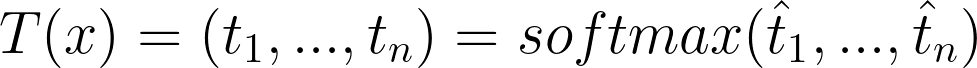
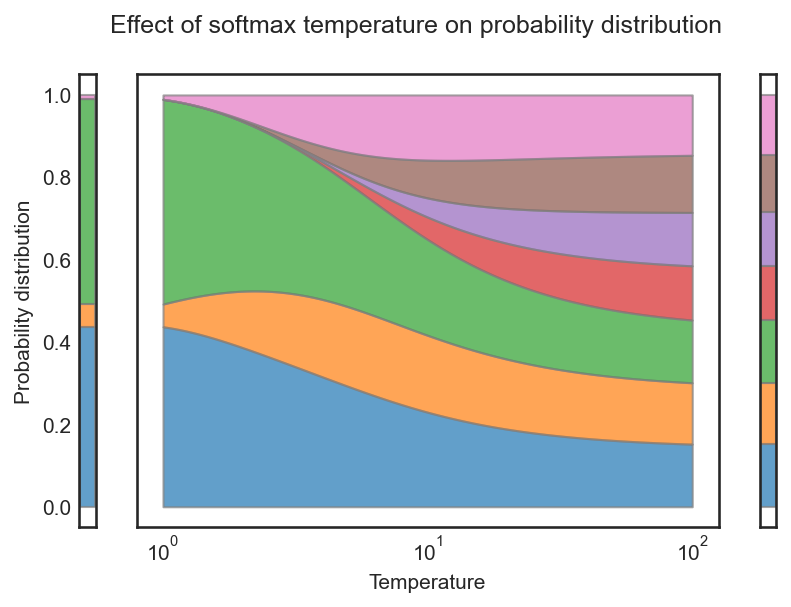
DistilBERT uses the notion of temperature as in [7] which helps to soften the softmax. The temperature is a variable θ ≥ 1 which lowers the ‘confidence’ of a softmax as it goes up. The normal softmax is described as follows:
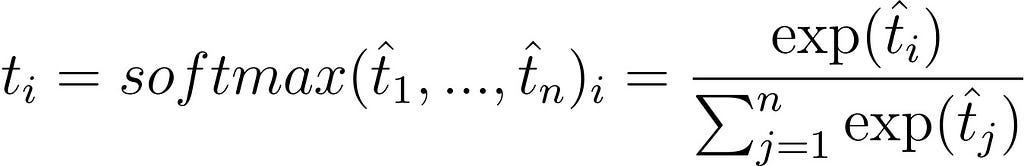
Now, let’s uselessly rewrite it as:
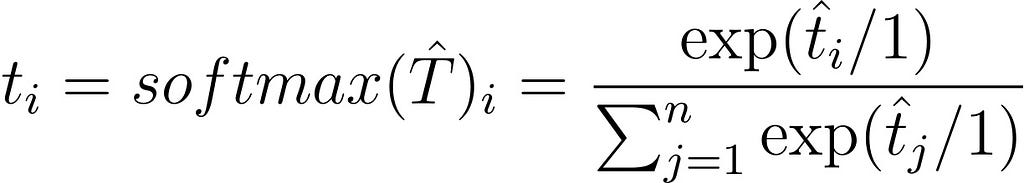
Which everyone will agree is correct. The 1 actually corresponds to the temperature θ. A normal softmax is a softmax with its temperature set to 1, and the formula for a softmax with a general temperature is:
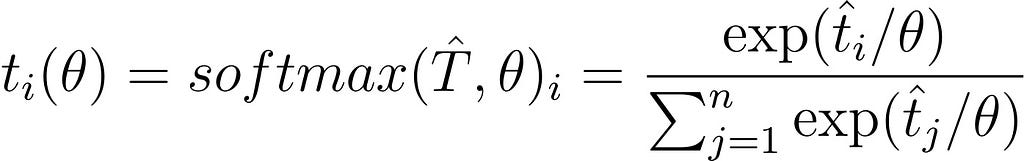
As θ goes up, the quotient over θ goes to zero, and thus the whole quotient goes to 1/n and the softmax probability distribution goes to a uniform distribution. This can be observed in the graph above.
In DistilBERT, both the student and the teacher’s softmax are conditioned by the same temperature θ during training, and the temperature is set to 1 during inference.
V. Conclusion
Now that you know how distillation of BERT-like models works for DistilBERT, the only thing to do is to choose a model and distill it!
Obviously, you still need to implement the distillation process, but we’ll cover how to do that soon.
References
[1] Victor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (2019), Hugging Face
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018), Google AI Language
[3] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019), arXiv
[4] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, TinyBERT: Distilling BERT for Natural Language Understanding (2019), arXiv
[5] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou, MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (2020), arXiv
[6] Raimi Karim, Illustrated: Self-Attention (2019), Towards Data Science
[7] Geoffrey Hinton, Oriol Vinyals, Jeff Dean, Distilling the Knowledge in a Neural Network (2015), arXiv
Distillation of BERT-like models: the theory was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3ygPGt9
via RiYo Analytics






ليست هناك تعليقات