https://ift.tt/3m1ZHWu Experiments with the new API Endpoint Image: www.pexels.com Embeddings are a way of finding numerical representa...
Experiments with the new API Endpoint

Embeddings are a way of finding numerical representations for texts that capture the similarity of texts to others. This makes them the ideal basis for applying clustering methods for topic analysis. In this article, I would like to test the embeddings of the language model GPT3, which has recently become available via API, by comparing them with topics in documents. OpenAI was rolling out Embeddings to all API users as part of a public beta. We can now use the new embedding models for more advanced search, clustering, and classification tasks. The embeddings are also used for visualizations.
The Data Set
The 20 Newsgroups dataset (License: Public Domain / Source: http://qwone.com/~jason/20Newsgroups/) is a collection of approximately 20,000 newsgroup documents classified into 20 categories. The data set was collected by the Stanford Natural Language Processing Group over the course of several years. It is a standard data collection often used in natural language processing to evaluate procedures.
We use the training part of the dataset (60% of the data) and filter out articles that are too long to avoid problems with the context length of the GPT3 model. Only documents with less than 2000 tokens are used.
The data is loaded using “Scikt Learn” and checked with the GPT2 Tokenizer to see if the length fits. Then a Pandas data frame is created with the texts of the posts and a number that refers to the origin of the newsgroup.
Download the embeddings
To retrieve data from the OpenAI API you need an API Key. There are costs for the retrievals, which depend on the model used. The embedding models will be free through the end of 2021.
Currently, they offer three families of embedding models for different functionalities: text search, text similarity, and code search. Each family includes up to four models on a spectrum of size:
- Ada (1024 embedding dimensions),
- Babbage (2048 embedding dimensions),
- Curie (4096 embedding dimensions),
- Davinci (12288 embedding dimensions).
Davinci is the most capable but is slower and more expensive than the other models. Ada is the least capable but is significantly faster and cheaper.
We use the Babbage model for similarity “babbage-similarity” for our test.
The documentation of the endpoint for embeddings can be found at:
With the help of the Python package from OpenAI and an auxiliary function from the documentation of GPT3, we can now download the numerical representation for each document and add it as a column in the data frame.
Clustering based on the Embeddings
For clustering, we use the KMeans algorithm. This is a partitioning algorithm that groups objects into k clusters so that the sum of distances between all pairs of objects within a cluster is minimized. To find the optimal number of clusters for the dataset we calculate the clusters für a range of k-values and then select the one with the lowest Silhouette Score.
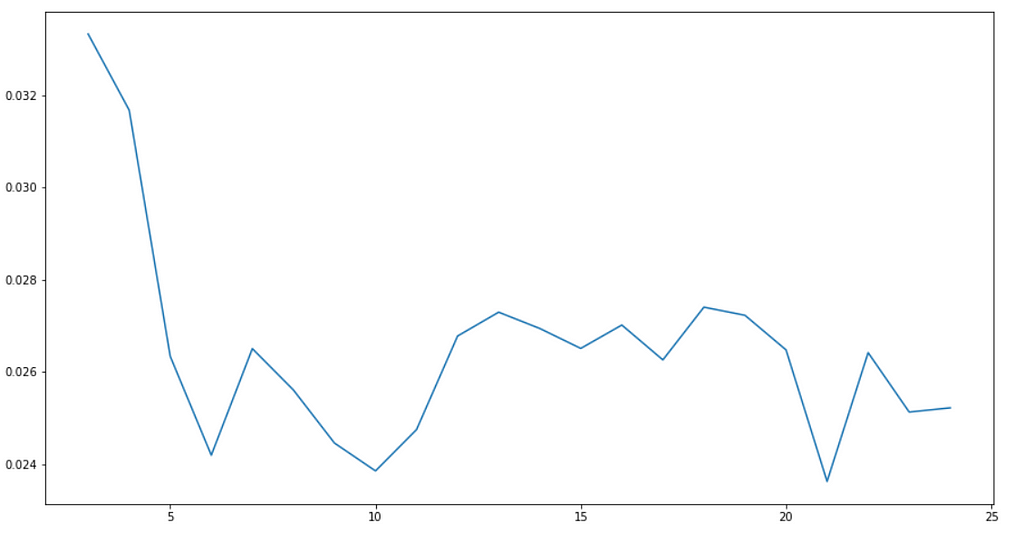
In this example, 21 is found as a minimum in the range. This corresponds to 21 different topics in the corpus. The sizes of the clusters vary from 125 to 791.
Visualization of the Embeddings and the Clusters
For visualization, we use the TSNE algorithm. This is a nonlinear dimensionality reduction technique that projects high-dimensional data into two or three dimensions. This can be helpful to get a better overview of the data and to identify patterns.
First, we visualize the embeddings with their newsgroup affiliation as the color code.
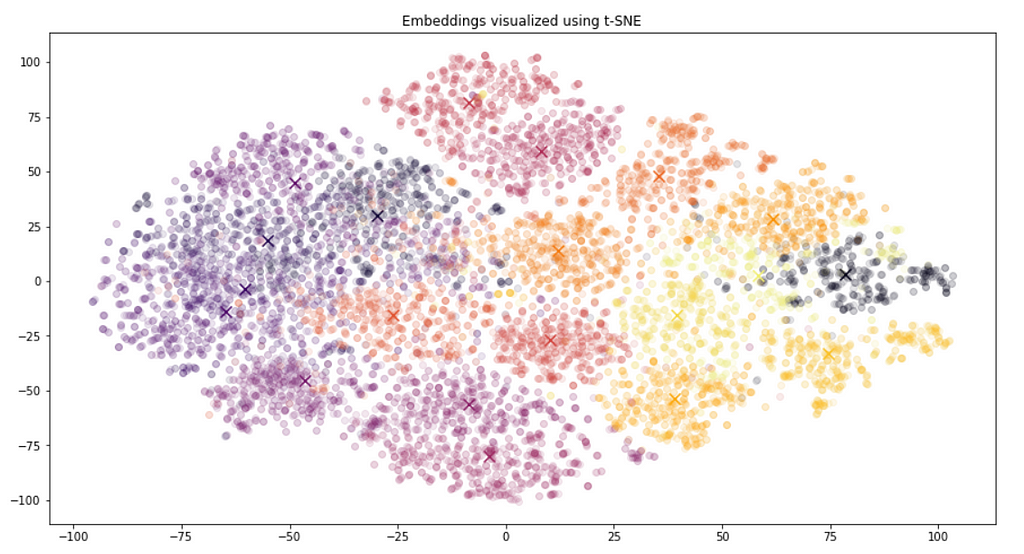
This shows that the position in space reflects the content of the documents and the similarity between them very well if you take the newsgroup membership as a measure. We have used only the embeddings of GPT3 as the representation for the documents, and no further information from the texts, nor any further fine-tuning.
Secondly, we consider the same representation but with the clusters found by KMeans as the color code.
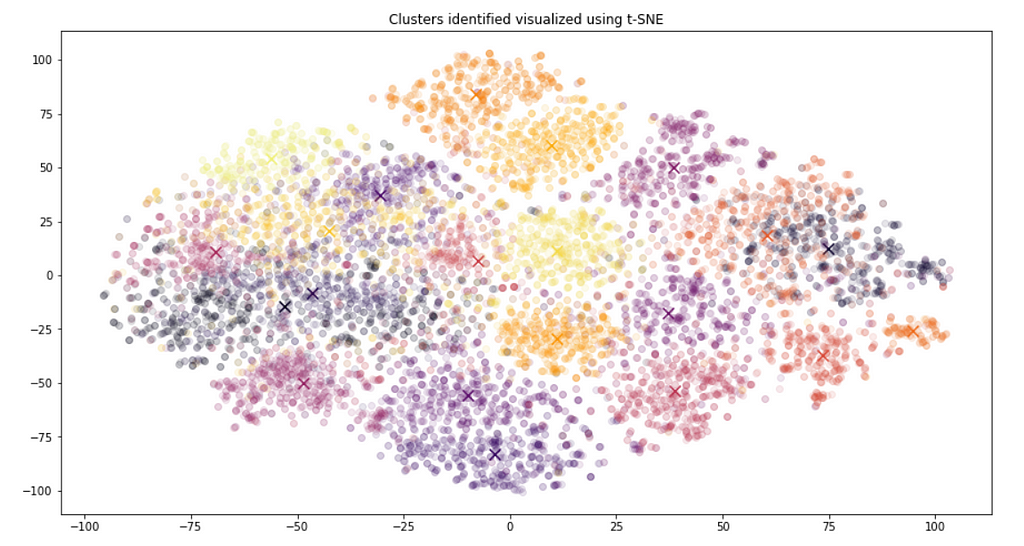
There are small differences, especially the colors used, but the structure and cluster centers are very similar. This also underlines that the thematic structure is well reflected by the embeddings.
Describe the Clusters
In order to describe what content the individual clusters stand for, we try to create a description of the clusters. To do this, we randomly take some documents from each cluster and use that as input for GPT3 itself to generate descriptions. We use the “davinci-instruct-beta-v3” model vom the OpenAI API because of its expressiveness.
For each cluster, we randomly take 3 documents (the first 1000 characters each, otherwise the prompt for GPT3 will be too long.) combine this with the question of what these documents have in common, send this to GPT3 and thus get a description per cluster.
This gives us the following results:
Cluster 0 Topic: -Internal modems in different Apple models-Different types of RAM in the same computer
Cluster 1 Topic: There must be a creator! (Maybe)Date: Tue, Apr 6 1993From: ingles@engin.umich.edu (Ray Ingles)Subject: Re: There must be a creator! (Maybe)Organization: University of Michigan Engineering, Ann Arbor
Cluster 2 Topic: MIT R5 on Sun with Rasterops TC ColorboardSubject: Xsun24 patches for supporting sun's 24bit frame buffersFrom: mark@comp.vuw.ac.nz (Mark Davies)Organization: Dept. of Comp. Sci., Victoria Uni. of Wellington, New Zealand.
Cluster 3 Topic: Motorcycles-All three documents are about motorcycles.-All three documents mention the CX500 Turbo.-All three documents mention the Ducati Mike Hailwood Replica.
Cluster 4 Topic: color managementAll three documents discuss color management in some way.
Cluster 5 Topic: What do the following documents have in common?The documents all have to do with cars.
Cluster 6 Topic: The documents have in common that they are all about different aspects of the Vietnam War.
Cluster 7 Topic: scientific researchThe documents have in common that they are all about scientific research.
Cluster 8 Topic: Miscellaneous Items For SaleFrom: battle@cs.utk.edu (David Battle)Subject: ChemLab EyeoftheBeholder2 ClueBook EthernetTransceiver NintendoControlSummary: Miscellaneous Items For SaleKeywords: Chemistry IBM PC Games Clue Book Ethernet Transceiver NintendoReply-
Cluster 9 Topic: Each document discusses a problem that a computer user is experiencing.
Cluster 10 Topic: What do the following documents have in common?The documents have in common that they are all responses to articles or postings.
Cluster 11 Topic: Admission to the United NationsThe documents have in common that they are about the admission of new members to the United Nations.
Cluster 12 Topic: The documents have in common that they are all responses to someone else's article.
Cluster 13 Topic: Bible contradictionsDate: 95-02-27 00:51:05 ESTFrom: af664@yfn.ysu.edu (Frank DeCenso, Jr.)Organization: Youngstown State/Youngstown Free-NetLines: 12NNTP
Cluster 14 Topic: international lawThe documents have in common that they discuss international law.
Cluster 15 Topic: The documents have in common that they are all about hockey.
Cluster 16 Topic: conspiracy, Occam's razor, greed, NSA, PKP, Democrats, Socialism, European Socialists, fascism, capitalism, Republicans, personal privacy
Cluster 17 Topic: baseballAll three documents are about baseball.
Cluster 18 Topic: Norton Desktop for Windows 2.2All three documents are about different versions of the Norton Desktop for Windows software.
Cluster 19 Topic: - The commonality of the documents is that they are all about space.- The documents also share the commonality of being written by different people.
Cluster 20 Topic: All three documents discuss the use of windows and graphics.
Some of the descriptions are quite good, e.g.
“The documents have in common that they are all about scientific research.”
or
“The documents have in common that they are all about hockey.”
others, however, are very strange, e.g.
“The documents have in common that they are all responses to someone else’s article.”
In order to achieve better results, it is necessary to pre-process the newsgroup texts, e.g. filter e-mail addresses, but also to condense the content to include more documents without reaching the prompt limit of GPT3.
Summary
The research in the article has shown that the embeddings that can be retrieved from GPT3 via the API are quite suitable for describing the content structure of a text corpus. Using the example of the 20 newsgroup dataset, it was shown by means of visualizations and KMeans clustering that the spatial structure formed by the embeddings reflects the topics of the newsgroups.
GPT3 can additionally be used to describe the contents of the individual clusters.
Clustering the 20 Newsgroups Dataset with GPT3 Embeddings was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3GJYrPF
via RiYo Analytics









No comments