https://ift.tt/3cleAO5 My experience working as a Software Engineer and a Data Scientist, and the solutions to the challenges that I faced ...
My experience working as a Software Engineer and a Data Scientist, and the solutions to the challenges that I faced
I am pretty sure that many of the readers question or think of what they do in their professional lives. Besides, they also compare their projects, development practices, managers, and even colleagues. Since I have completed my 6 years and had a chance to work at both Software Engineering and Data Science project developments, I would like to write a blog post to mention similarities, differences and essentials.

In the following parts of the post, SW and DS stand for Software and Data Science respectively.
Project Management
As you might guess, the phases Business Goal or Demand, Planning, Tech Design, Implementation, and Maintenance/Monitoring have been the same or similar for both types of projects as far as I have worked. Project managers or product owners, depending on the size of the company or the aspect, finalizes the business goal after many meetings, functional and technical requirements are defined and estimation is done with both product and technical teams, then application is developed. Finally, the released application has been monitored and required changes/features are developed later on.
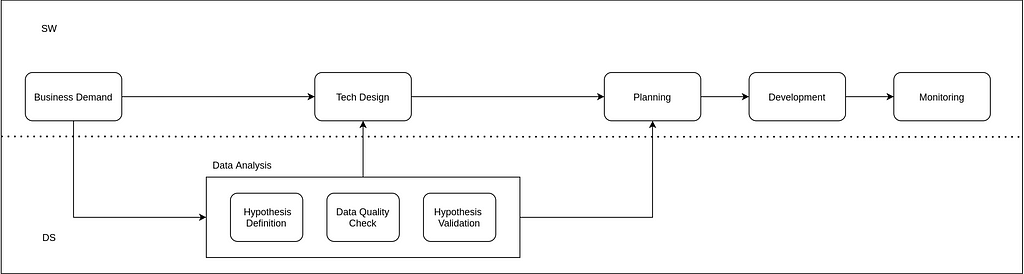
Data Analysis
With great planning and clean implementation with a smart design, great software can be released. For the DS projects, I would like to add a data analysis section between Demand and Planning phases. In this phase, first, the hypothesis is defined, existing or possible data sources are checked and validated, and the validation of the hypothesis is done. At any step of this process, I have seen that the project can be stopped or modified. As in life, unless we have any basis, it is one of the best decisions to give up on our hypothesis as soon as it falters.
In data source validation, a low quality data may maintain an average software but it’s critical for the DS projects. If the company wants to make some decisions from the output of the DS application, accuracy of the model must be acceptable or negligible for the first iterations. Creating a base model would be great to observe how a new proposed model is better or worse. Even this base model may be employed if it has a reasonable accuracy, then the complexity is increased in order to outperform the naive model in the further developments. Despite the accuracy being great, data quality must be verified. So, the alignment between data engineers and data scientist or ML engineers is significant for the data applications. Because the training data and the prediction data must be the same for a data application. For example, if there is a batch prediction, data migration must be verified before the prediction. Otherwise, prediction and training parts would be differ and it may cause some catastrophic conclusions for the company.
Tech Design
Using a clear software design such as Hexagonal Architecture makes adding new features or changing the technology stack for both SW and DS projects. Data sources, frameworks and even programming languages can change before the development. For example, if we want to implement a very short response time application for payment processes, cache can be implemented to keep this crucial information and we can reduce the workload of DB.
For DS projects, application flow is similar with SW projects except model training, model selection and prediction phases. So, in the tech design, the complexity of the MLOps can be defined. Initially, starting with the simplest way in which Model Training, Model Selection and Model Deployment can be handled manually, then these steps can be automated. Besides the MLOps, algorithm type and the complexity of the model is another important actor for the tech design.
Planning
If all validations are done and the requirements are finalized, we can initiate the planning section. Since the team starts to know dynamics and the development environment better, this phase gets better as I observed. The tasks can be created as granular as possible, each team member can give better and similar sprint points, and the overall estimation and planning can be finalized.
At the software side, there might be some underestimations for the DevOps operations. Operations on the servers and the permissions between the applications or the data sources may last longer the estimation. A new application may need to call an endpoint from an existing application or a new field may need to be added into the response. Hence, these communications should be done before the planning to make better estimations.
At the data side, the details at the software side are generally similar. Besides, the planning for Feature Engineering, Model Training, and Model Selection steps can be overestimated and it’s also normal since they are data related processes. Better data analysis and starting with a simple approach may help with better planning. In addition to them, some simpler thresholds can be assigned for models to outperform them at these steps. For example, if the F1 Score of the classifier is higher than X value, we can stop there and keep our excitement for the further model training.
Development
The development part where I enjoy most for both sides is the last step before the final step which is the monitoring. Implementation of the services, handling the unit-integration-functional tests, and preparing the server for the application are the common phases for both applications.
In the SW applications, implementation of the tests for a non-exceptional application is a bit easier than the one in the DS applications. Testing the result of the AI model is not a good approach if we employ a complex model. However, mocks can be implemented for these models as it can be implemented for external services in the applications.
Feature Engineering, Model Training, and Model Selection are the distinguishing phases apart from the SW projects. As it is mentioned in the previous session, there might be some thresholds with 2 dimensions. One dimension is a success criteria to stop and the other dimension is the time criteria. Since these steps are one of the most willing and the most hyped developments nowadays, these developments and research should be limited to increase productivity. If this new application brings some success and it requires better accuracy these three phases can continue for further developments.
Monitoring
Finally, it’s time to reap the fruits for both sides. Using the monitoring tools such as Splunk and Datadog (I only worked for them) which extract information from the application logs has a significant role. After a new release, it would be the first place to validate that the new release works seamlessly. Metrics of the software such as number of the requests and response time and error types can be extracted by writing good logs. It is also great to do data checks in the controller class where the requests are received and forwarded to desired services before starting the operations for both SW and DS projects unless the UI side doesn’t do any check. Regex validations and data type checks can literally save the applications at both performance and security sides. An easy SQL injection may be prevented by a simple validation and it can even save the company’s future.
On the DS side, there should be further monitoring besides the software metrics. Distribution of the model features and the model predictions are vital. If the distribution of any data column changes, there might be a data-shift and a new model training can be required. If the prediction results can be validated in a short time, these results must be monitored and warn the developers if the accuracy is below or above from a given threshold.
Common Practices
Before the conclusion, I would like to mention some common practices which help me for both types of projects.

- Having great business domain knowledge: It is indispensable for both sides. In order to acquire this knowledge, we must understand the client requirements. This knowledge can provide benefits such as implementation of significant edge cases in the SW projects and extraction of great features in the DS projects. It also helps to write better tests and prepare better environment for the application
- Using OKRs for the project output: In order to give a better business value in the applications, it’s better to talk with business language. We should transform the goals from ‘reduce the response time by x’ to ‘accelerate the onboarding process by y’ or ‘reduce the fraud rate by x’ to ‘increase the payment conversion rate by y’. These transformations would help the teams in different departments to have better communication and reduce the technical terms in the communication between technical and non-technical teams.
- Application of development practices: Clean coding, designing a great service architecture, pair programming, and the reviews are the most common ones as far as I remember. For the maintenance code quality is ineluctable. Even for a one Jupyter-Notebook file, another person should understand the script as much as possible to understand and implement new features. Pair programming and the reviews are also important to increase productivity and reduce overlooked errors.
- Great documentation: During the planning and the design sessions, it’s also significant to have great documentation which can be counted as a legal document before starting the implementation. It can be used as a source for the development and contain brief explanations and flow charts for other technical and non-technical members in the company.
Conclusion
I tried to mention what I faced while I was working on both my SW and DS projects. I hope some of them will be useful for some readers. It would help some as the ones that I used to get benefit from and I am currently benefiting. As it’s mentioned above, better planning, great and visible communication, a great analysis, an efficient development, and a great monitoring phases generally drive me to work in great developments.
Before saying goodbye, I would like to mention that it is not a blog post that I want to give advice to people by going beyond the limits with a work experience that is over 6 years and not long and I am also a bit biased with data projects since I have been working at data projects for more than 3 years. These are the only challenges that I faced and I just wanted to share my experiences. These inferences may be useful for some other developers.
Before saying goodbye, I would like to say thank you to first reader of this post Mustafa Kirac!
To say me “hi” or ask me anything:
linkedin: https://www.linkedin.com/in/ktoprakucar/
github: https://github.com/ktoprakucar
e-mail: toprakucar@gmail.com
References
- https://www.amazon.com/gp/product/149204511X/ref=x_gr_w_bb_sin?ie=UTF8&tag=x_gr_w_bb_sin-20&linkCode=as2&camp=1789&creative=9325&creativeASIN=149204511X&SubscriptionId=1MGPYB6YW3HWK55XCGG2
- https://www.educative.io/courses/grokking-the-system-design-interview/m2yDVZnQ8lG
- https://eugeneyan.com/writing/writing-docs-why-what-how/
- https://eugeneyan.com/writing/first-rule-of-ml/
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#devops_versus_mlops
- https://www.amazon.fr/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882
- https://alistair.cockburn.us/hexagonal-architecture/
- https://microservices.io/patterns/decomposition/decompose-by-business-capability.html
Software Engineering XOR Data Science was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3oBZmdu
via RiYo Analytics







ليست هناك تعليقات