https://ift.tt/3nQ83Ay How to install and configure Hadoop and its components on Windows 11 running a Linux distro using WSL 1 or 2. Sour...
How to install and configure Hadoop and its components on Windows 11 running a Linux distro using WSL 1 or 2.

In the previous post, we saw how to install a Linux distro on Windows 11 using WSL2 and then how to install Zsh and on-my-zsh to make the terminal more customizable. In this post, we’ll see how we can install the complete Hadoop environment on the same Windows 11 machine using WSL.
Installing Dependencies
There are two important dependencies that you’ll need to install to make Hadoop work. These aren’t optional, unless you have them installed already. So make sure you install these dependencies.
Installing JDK
The first dependency is java development kit, or JDK. It’s recommended to go with Java 8, or Java 1.8 for Hadoop. This recommendation is coming from me, as I have had problems with newer versions of Java. But you can definitely give newer versions a shot.
Also, it doesn’t matter if you install Oracle JDK or Open JDK, or any other version of JDK. You just need to have it installed. I used the following command to install JDK 8 on the Debian Linux that I’ve installed on Windows 11:
sudo apt install adoptopenjdk-8-hotspot
For this package to be available in the apt repository, you’ll firs need to add the PPA. For that run the following command:
sudo add-apt-repository --yes https://adoptopenjdk.jfrog.io/adoptopenjdk/deb/
Once you have JDK installed, make sure you export the path of the JDK with the env variable name JAVA_HOME. The export command looks like this:
export JAVA_HOME=/usr/lib/jvm/adoptopenjdk-8-hotspot-amd64/bin/java
If you just run this command in your terminal, the variable will be exported only for the current session. To make it permanent, you’ll have to add this command to the .zshrc file.
Installing OpenSSH
The next dependency to install is OpenSSH so that Hadoop can SSH into the localhost. This also is a necessary dependency. Without SSH into localhost, most components of Hadoop wouldn’t work. To install OpenSSH, run the following commands in the terminal:
sudo apt install openssh-server openssh-client -y
Once we have both the server and the client installed for SSH, we have to generate keys for authentication. For this, run the following command and go through the instructions that you’ll get:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Once the keys are generated, you have to copy them over to the list of authorized keys so that you don’t have to enter a password each time you SSH into the machine. This is especially important because this is what Hadoop expects. At least I haven’t seen an option to change this behavior. So, run the following command to cat the file contents of the key file we just created, and then copy that to the authorized_keys file:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Now, make sure that the public key file has the right permission. This is because if the key file has more public access than needed, the system would think that the key can be copied or duplicated or tampered with, which would mean the key is not secure. This will make the system refuse the key and not allow SSH login. So run the following command to set the right permissions:
chmod 0600 ~/.ssh/id_rsa.pub
Next, start the SSH service so that we can test if the the server is working fine. For this, run the following command:
sudo service ssh start
If everything till here worked as expected, you’re golden. Finally, run the following command to make sure that SSH is working as expected:
ssh localhost
If everything works as expected, you should see something similar to the screenshot below:
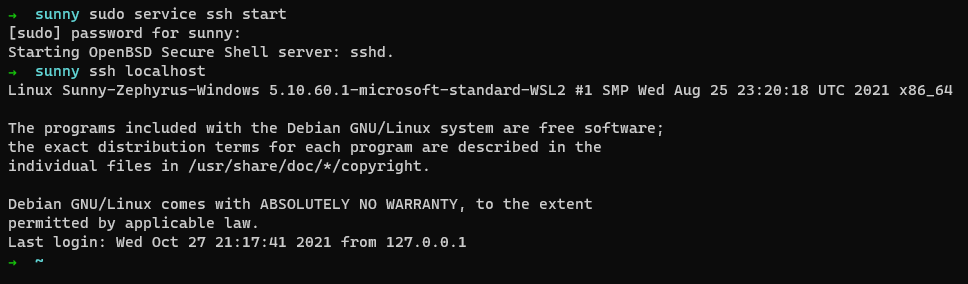
Awesome. You can exit back to your previous session by hitting the key combination CTRL + d. This concludes the dependency installation phase. Let’s now move on to installing Hadoop.
Installing Hadoop
Downloading Hadoop
First step to installing Hadoop is to actually download it. As of this writing, the latest version of Hadoop is version 3.3.1, and you can download it from here. You will be downloading a .tar.gz file from there. To decompress that file, use the following command:
tar xzf hadoop-3.3.1.tar.gz
This will create a directory named hadoop-3.3.1 and place all files and directories inside that directory. Because we’re installing Hadoop on our local machine, we’re going to do a single-node deployment, which is also known as pseudo-distributed mode deployment.
Setting the environment variables
We have to set a bunch of environment variables. The best part is, you have to customize only one variable. The others are just copy-paste. Anyway, following are the variables I’m talking about:
export HADOOP_HOME=/mnt/d/bigdata/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
As you can see, you only have to change the value of the first environment variable, HADOOP_HOME. Set it to reflect the path where you have placed the Hadoop directory. Also, it is a good idea to place these export statements in the .zshrc file so that these variables are exported every time automatically instead of you having to do it. Once you place it in the file, make sure you source it so that it takes effect immediately:
source ~/.zshrc
Configuring Hadoop
Next, we’ll have to edit a few files to change the config for various Hadoop components. Let’s start that with the file hadoop-env.sh. Run the following command to open the file in the editor:
sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Next, find the line that is exporting the $JAVA_HOME variable and uncomment it. Here, you have to provide the same path that you did when you installed Java earlier. For me, that's the following:
export JAVA_HOME=/usr/lib/jvm/adoptopenjdk-8-hotspot-amd64/bin/java
Next, we have to edit the core-site.xml file. Here we have to provide the temporary directory for Hadoop and also the default name for the Hadoop file system. Open the file in the editor using the following command:
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml
You’ll find an empty file here with a few comments and an empty configuration block. You can delete everything and replace it with the following:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/d/hdfs/tmp/</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
Make sure you create the temp directory that you configure here. Next, we have to edit the HDFS config file hdfs-site.xml. To do this, open the file in the editor using the following command:
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
In this configuration file, we are setting the HDFS data node directory, HDFS name node directory, and the HDFS replication factor. Here again you should get a file with an empty configuration block. Replace that with the following:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/mnt/d/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/mnt/d/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
And again, make sure you create the data node and name node directories. Next, we have the MapReduce config file. To open this in the editor, run the following command:
sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
You can replace the configuration block with the following:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
As you can see, it’s a simple configuration which specifies the MapReduce framework name. And finally, we have the YARN configuration file, yarn-site.xml. Open the file in the editor using:
sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
Add the following configuration to the file:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
There’s nothing to change in this configuration. And finally, we’re done configuring Hadoop. We can now move on to formatting the name node and starting Hadoop.
Formatting the HDFS name node
It’s important to first format the HDFS name node before starting the Hadoop service the first time. This, obviously, makes sure there’s no junk anywhere in the name node. And once you start using HDFS more frequently, you’ll realize that you’re formatting the name node more often that you thought you would, at least on your development machine. Anyway, to format the name node, use the following command:
hdfs namenode -format
Once you get the shutdown notification for name node, the formatting is complete.
Starting all of Hadoop
Finally, we’re at the best part of this activity, starting and using Hadoop. Now, there are many ways of starting Hadoop depending on what components you actually want to use. For example, you can start only YARN, or HDFS along with it, etc. For this activity, we’ll just start everything. To do this, the Hadoop distribution provides a handy script. And because you have already exported a bunch of environment variables earlier, you don’t even have to search for that script, it’s already in your path. Just run the following command and wait for it to finish:
start-all.sh
This will take a few seconds, as the script just waits for the first 10 seconds without doing anything to give you an option to cancel the operation if you started it by mistake. Just hold on and you should see output similar to the following screenshot:

This tells us that all components of Hadoop are up and running. To make sure, if you want to, you run the jps command to get a list of all the processes running. You should see at least the following services:
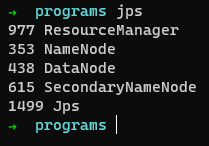
And that’s it. You’re now running Hadoop on your Windows 11 PC using a Linux distro on WSL 1 or 2. To make sure, you can use the following simple HDFS command:
hdfs dfs -ls /
This command will list all files and directories at the root HDFS directory. If it’s a brand new deployment, you shouldn’t find much there. You’ll get a list similar to the one shown below:

That’s pretty much it. We’re done!
And if you like what you see here, or on my personal blog and Dev.To blog, and would like to see more of such helpful technical posts in the future, consider following me on Github.
Originally published at https://blog.contactsunny.com on November 1, 2021.
Installing Hadoop on Windows 11 with WSL2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3k1Cx1o
via RiYo Analytics









No comments