https://ift.tt/3Hn7ve8 Predicting is difficult, but it can be solved in small bits, like predicting the next few words someone is going to ...
Predicting is difficult, but it can be solved in small bits, like predicting the next few words someone is going to say or the next characters to complete a word or sentence being typed. That's what we are going to attempt to do.

The complete code for this article can be found HERE
What is an N-gram
An N-gram is a sequence of n items(words in this case) from a given sample of text or speech. For example, given the text “ Susan is a kind soul, she will help you out as long as it is within her boundaries” a sample n-gram(s) from the text above starting from the beginning is :
unigram: [‘susan’, ‘is’, ‘a, ‘kind’, ’soul’, ‘she’, ‘will’, ‘help’………….]
bigram: [‘susan is’, ‘is a’, ‘a kind’, ’kind soul’, ‘ soul she‘, ‘she will’, ‘will help’, ‘ help you’………….]
trigram: [‘susan is a’, ‘is a kind’, ‘a kind soul’, ’kind soul she’, ‘soul she will‘, ‘she will help you’………….]
From the examples above, we can see that n in n-grams can be different values, a sequence of 1 gram is called a unigram, 2 grams is called a bigram, sequence of 3 grams is called a trigram.
Trigram models
We will be talking about trigram models in this article.
A bigram model approximates the probability of a word given all the previous words by using only the conditional probability of the preceding words while a trigram model looks two words into the past.
So based on the above, to compute a particular trigram probability of a word y given a previous words x, z, we’ll compute the count of the trigram C(xzy) and normalize by the sum of all the trigrams that share the same words x and z, this can be simplified using the equation below:
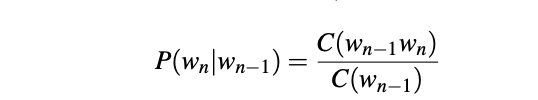
That is, to compute a particular trigram probability of the word “soul”, given the previous words “kind”, “hearted”, we’ll compute the count of the trigram C(“kind hearted soul”) and normalize by the sum of all the trigrams that share the same first-words “kind hearted”.
We always represent and compute language model probabilities in log format as log probabilities. Since probabilities are (by definition) less than or equal to 1, the more probabilities we multiply together, the smaller the product becomes. Multiplying enough n-grams together would result in numerical underflow, so we use the log probabilities, instead of the raw probabilities. Adding in log space is equivalent to multiplying in linear space, so we combine log probabilities by adding them.
Code
We will be using a corpus of data from the Gutenberg project. This contains passages from different books. We will be predicting character character-level trigram language model, for example, Consider this sentence from Austen:
Emma Woodhouse, handsome, clever, and rich, with a comfortable home and happy disposition, seemed to unite some of the best blessings of existence; and had lived nearly twenty-one years in the world with very little to distress or vex her.
The following are some examples of character-level trigrams in this sentence:
Emm, mma, Woo, ood, …
First, we will do a little preprocessing of our data, we will combine the words in all the passages as one large corpus, remove numeric values if any, and double spaces.
def preprocess(self):
output = ""
for file in self.texts:
with open(os.path.join(os.getcwd(), file), 'r', encoding="utf-8-sig", errors='ignore') as suffix:
sentence = suffix.read().split('\n')
for line in sentence:
output += " " + line
return output
Next is the code for generating our n-grams, we will write a general function that accepts our corpus and the value describing how we would like to divide our n-grams. See below:
Next, we build a function that calculates the word frequency, when the word is not seen we will for this example smooth by replacing words with less than 5 frequency with a general character, in this case, UNK.
def UNK_treated_ngram_frequency(self, ngram_list):
frequency = {}
for ngram in ngram_list:
if ngram in frequency:
frequency[ngram] += 1
else:
frequency[ngram] = 1
sup = 0
result = {}
for k, v in frequency.items():
if v >= 5:
result[k] = v
else:
sup += v
result["UNK"] = sup
return result
Next, we have our trigram model, we will use Laplace add-one smoothing for unknown probabilities, we will also add all our probabilities (in log space) together:
Evaluating our model
There are two different approaches to evaluate and compare language models, Extrinsic evaluation and Intrinsic evaluation. We will be evaluating intrinsically because it is a useful way of quickly evaluating models. We will evaluate with a metric called Perplexity, this is an intrinsic evaluation method, not as good as evaluating intrinsically though, the article HERE can explain the evaluation concepts better.
We will measure the quality of our model by its performance on some test data. The perplexity of a language model on a test set is the inverse probability of the test set, normalized by the number of words. Thus the higher the conditional probability of the word sequence, the lower the perplexity, and maximizing the perplexity is equivalent to maximizing the test set probability according to the language model.
For our example, we will be using perplexity to compare our model against two test sentences, one English and another French.
Perplexity is calculated as:

Implemented as:
def perplexity(total_log_prob, N):
perplexity = total_log_prob ** (1 / N)
return perplexity
Testing both sentences below, we get the following perplexity:
perp = self.perplexity(sum_prob, len(trigram_value))
print("perplexity ==> ", perp)
English Sentence: perplexity of 0.12571631288775162
If we do not change our economic and social policies, we will be in danger of undermining solidarity, the very value on which the European social model is based.
The rapid drift towards an increasingly divided society is happening not only in Europe but also on a much wider scale. An entire continent, Africa - about which you made a highly relevant point in your speech, Prime Minister - has lost contact even with the developing world.
We must do everything in our power to stop this unjust development model and to give voices and rights to those who have neither.
Ladies and gentlemen, Prime Minister, the Laeken Summit and declaration are also vitally important for another reason.
Laeken must determine how we are to structure the second stage of the 'Future of Europe' debate.
French Sentence: perplexity of 0.21229602165162492
Je suis reconnaissante à la Commission d' avoir adopté ce plan d' action.
Cependant, la condition de son applicabilité est que les personnes atteintes d' un handicap puissent disposer des moyens financiers nécessaires, et qu' elles aient la possibilité purement physique de passer les frontiÚres.
Il serait intéressant de savoir si la Commission est aussi disposée à débloquer des fonds en faveur des personnes handicapées, pour qu' elles puissent, elles aussi, parcourir le monde, aussi loin que pourra les emmener le fauteuil roulant.
J'ai mentionné la directive que la Commission a proposée pour l'aménagement des moyens de transport collectifs, afin que les handicapés puissent les utiliser.
Le Conseil n'a pas encore fait avancer cette question, qui en est au stade de la concertation.
As expected, our model is quite perplexed by the french sentence, This is good enough at the moment, however, our model can be improved on.
Comments and feedbacks are welcome.
Don't forget to click the follow button.
Implementing a character-level trigram language model from scratch in python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3opyuNI
via RiYo Analytics








No comments