https://ift.tt/308QqUw Forget soap, we will wash their mouth out with the power of data science Photo by Tyler Nix on Unsplash People...
Forget soap, we will wash their mouth out with the power of data science

People say bad words. If you or your company happen to have any type of user generated content, these people will say bad words on your website, social media, reviews, comments, etc. They will sit anonymously behind their little screens and cuss like Marines all over your website!
Fortunately, I used to be a Marine, so I consider myself a bit of an expert in cussing. I’m going to teach you how to catch profanity with just a few lines of R.
The problem is bigger than you think
Before we dive into the code, lets first reflect on how difficult of a problem this is to solve. No matter how clever we may think we are, there is simply no match for the ingenuity of people finding new ways to cuss. There are thousands of variations of the f-bomb alone, with new ones being created every day (I created several new ones while writing this article!).
Here are just a few examples of what you are up against:
- symbol replacements: cat = c@t
- phonetic replacements: duck = duc
- capitalization replacements: dog = DrOuGht
- letter separation: goose = g o o s e
- character repetition: mouse = moooouuuusssse
- inner word masking: horse = seahorses
- language replacement: bird = pajaro
- letter reversals: rat = tar
- and many, many, many others…
This excludes everyone’s personal favorite, words and phrases that were benign yesterday might suddenly become offensive today. Bonus points for this being a word that can be used appropriately in both profane and non-profane contexts.
So do we stand a chance? Well, sort of.
We can certainly fight the problem with blacklists, pattern matching (regex to the rescue!), machine learning, and post mortem measures (e.g. suspending or banning toxic users). But nothing really beats human moderation.
Language changes faster than our algorithms can keep up, and our ML models will always struggle with that last example (a good word becoming bad overnight).
The best approach is usually a combination of all of the above measures. You want blacklists (with new words being added daily by human moderators), pattern matching to catch all the permutations of a given word, ML models flagging potential bad content, and suspension/banning measures that are strict enough to dissuade users from crossing that line. Combine all of this with removing anonymity through identity verification and you might just stand a chance.
Today, we will just focus on the first item, catching profanity through blacklists.
BLT = BAD
To spare you from having to read a bunch of naughty words, we are going to play a little thought experiment. Let’s pretend, just for today, that the words ‘bacon’, ‘lettuce’, and ‘tomato’ are the most vile, terrible, and profane words in the English language.
If you stump your toe on the foot of the bed, you might say ‘bacon!!!’. If you say ‘tomato’ at your grandmothers house, she might disown you and write you out of the will. If you say the word ‘lettuce’… well you get the idea.
Now don’t worry that you won’t learn how to actually catch profanity. We are going to build our own lexicon of bad words (aka blacklist), but you will be able to use my code to catch actual profanity by swapping out a single variable.
Pretty tomato’ing cool right?!
Getting The Data
Now that we have established that BLT is BAD, we need to find some BLT. Where might we find these ingredients? How about in food recipes! Kaggle has a free dataset of food recipes (Shuyang Li, “Food.com Recipes and Interactions.” Kaggle, 2019, doi: 10.34740/KAGGLE/DSV/783630.) which you can download from their site here.
Writing The Code
Start by opening RStudio and creating a new R Project called ‘ProfanityFinder’. Drop the RAW_recipes.csv into the folder of your project. Also create a new R Script in this project called ‘BadWords.R’.
In your BadWords.R script, install these packages you you don’t already have them. Tidyverse allows us to use some sweet piping syntax to manipulate data, and sentimentr has some great NLP & profanity functions.
Next, we import the recipe data into a tibble (Tidyverses’ version of an R dataframe).
Now that our data is imported, lets clean it up a bit. First, we only need the name and ingredients columns for our purpose, so lets select that.
Next we clean up the ingredients column by removing punctuation. This column has some special characters like brackets that can cause havoc with our profanity functions. We will use a simple line of code to remove all of this.
Finally, the recipes data has over 230,000 rows! While we can exercise our patience and process all that data, its much better to limit it to just 100 rows. It turns out you cant get far into recipe data without running into some bacon, lettuce, and tomatoes (pardon my French!).
Now we get to the cool part. We need a list of the bad words we care about. Companies refer to these lists as blacklists or blocklists. In NLP land, we usually refer to lists of words as ‘lexicons’. Whatever terminology you prefer lets build that now.
Our lexicon is a character vector consisting of our 3 naughty words, and they are assigned to a variable called customCussWords.
Pay attention! This is where the magic sauce gets stirred in. Our lexicon may be a simple list of 3 words, but the sentimentr package happens to have quite a few lexicons of actual bad words. Want to see for yourself? In RStudio, simply type our variable into the console to read its contents.
customCussWords

Now a warning here, the following commands will show some pretty terrible words in you console. Its time to start working on that iron stomach though, because it turns out the way you stop profanity is with profanity!
Typing the following commands into the console, after you have ran the import(sentimentr) command, will show you the contents of the character vectors, just like our ‘customCussWords’ variable.
lexicon::profanity_alvarez
lexicon::profanity_banned
lexicon::profanity_arr_bad
These are just a few lexicons of bad words. There are many many more ready to be used. For better results, why not combine them all. Even better, define your own!
So what does all of this mean and what exactly is the magic sauce I mentioned? Easy. Anywhere you see our BLT lexicon ‘customCussWords’ you can just swap that out with any of the above profanity lexicons and now your code magically catches cuss words!
For example:
do_stuff(customCussWords)
Can become:
do_stuff(lexicon::profanity_alvarez)
So how do we actually catch profanity? The sentimentr package has a convenient function called ‘profanity’! This handy function has 2 inputs. The first input is text, and the second input is a lexicon of words to compare the text to!
Lets give the profanity function a whirl. First we will use a phrase that doesn’t contain a cuss word.

The profanity function returns a table that has a few interesting columns. It has Ids for elements and sentences, a word count, profanity count, and finally the percentage of words in the provided text that contain profanity. Lets make it more interesting by pumping some cussin’ into the function!

The results mean we have 1 sentence with 3 words, 1 of which was found in our lexicon. Since 1/3 of our text consisted of cuss words, our profanity percent is 33%.
The profanity function doesn’t only return 1 row for a given text. It actually breaks words into sentences through a process called ‘sentence boundary disambiguation’. This is fancy NLP talk for looking for things in our language that might represent where a sentence begins and ends.
If you recall, we removed all of the punctuation from our text earlier. Periods are one of many ways of determining where a sentence ends. The following code will return multiple rows of results from the profanity function:

All of this is important to understand, but for our simple exercise, we will simply be looking at the profanity_count column. We can just sum() this column to make sure we capture all sentences that occur!
Using base R syntax, we can access a particular column like this:

And just in case there are multiple sentences, we can sum it like so:

Now we know everything we need to know to do this! Lets take our recipe data and use the Tidyverse to add a column with a mutate().
What is this doing?
- df- calls our recipe dataframe
- rowwise- for each row of data, do the following stuff
- mutate- add a new column that passes the ingredients column into sentimentr’s profanity function using our customCussWords lexicon
- filter- only show the records that have profanity

There we have it! Our new ProfanityCount column is finding and counting all occurrences of the words bacon, lettuce, and tomatoes!
Its great knowing where profanity exists in our text, but we can take it one step further. Lets add a column that returns the actual profanity our program found. Sentimentr does have a function that is supposed to do this (extract_profanity_terms), but at least on the build of R I have, this function appears to be broken. No worries, we will just write our own function!
Our objective is to pass text and a lexicon into a function, and have it return all of the bacon, lettuce, and tomatoes it can find. Once again, if you need to find actual profanity, just pass one of the lexicons mentioned above and it will work!
What is our function doing?
- we define an empty character called returnText
- we loop through the words in our lexicon (bacon, lettuce, tomatoes) and see if that word is in the text. Grepl will return a true or a false if it finds the word.
- If the word is found we append it to the returnText variable with the paste function
- We return all the cuss words we found.
Finally, we can add a new mutate to our code that passes recipe into this function and it will return the profanity like so:
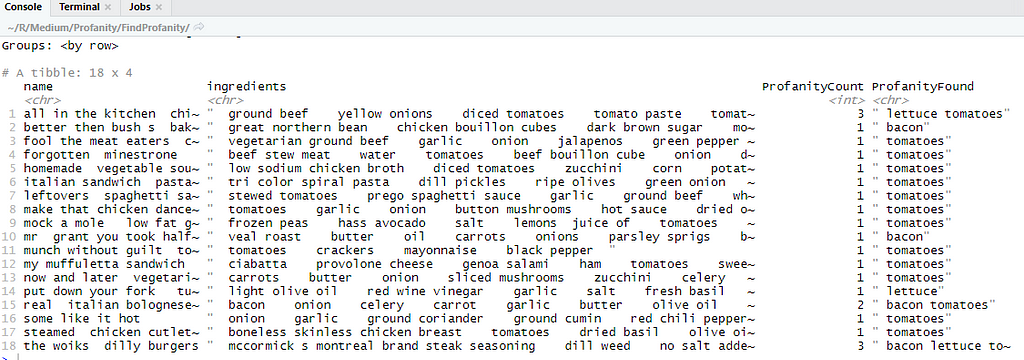
And that’s it! We have written code that finds profanity in text!
A note on efficiency
The code we have written here will work just fine on most small datasets, but there are some scenarios where this just wont work.
First off, sentence boundary disambiguation is a costly computation. If you have a larger dataset, you will want to preprocess all of your text into sentences. Sentimentr has a function called get_sentences that can do that. Also, removing all punctuation from our data maybe wasn’t the smartest thing. You’ll want to keep periods and exclamation points to help your code figure out where sentences start and end.
Second, that little loop we wrote to return the profanity found in text isn’t the most efficient way to do something like that. You may get more performance out of different methods such as lapply, sapply, etc.
Finally, if you are trying to flag real time data or chomp through billions of records, R really isn’t the language for that. R isn’t exactly the fastest programing language out there, and it’s parallel processing capabilities hover somewhere between ‘limited’ and ‘nonexistent’. If your use case involves big or real time data, you’ll want to pick a language that’s a little closer to the machine.
That’s a (BLT) wrap!
Now you know how to catch the bad guys! You can download all of the code from my GitHub!.
Did you know that you can hit the clap button up to 50 times on a single article? If you found this article informative, smash the lettuce out of that thing!
How to Catch Profanity with R was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3CXdHXD
via RiYo Analytics








No comments