https://ift.tt/3kJ1kr7 ARTIFICIAL INTELLIGENCE IS HARD Listing sets of things using NLP Image by GraphicMama-team from Pixabay at this...
ARTIFICIAL INTELLIGENCE IS HARD
Listing sets of things using NLP

In this article, we are going to dive into the automation of tasks performed by and between human “actors” in a computerized system.
During one of the lockdowns in 2020, I created a simple memory game for my kids to play before bedtime. The memory game goes like this:
- Pick a topic (e.g., foods)
- Take turns naming things that fit into that topic (e.g., cucumber, tomato). We later added a rule that you can only name unprocessed things because we were getting near-duplicates (e.g., sesame bun, onion bun, cinnamon bun, hot cross bun, etc.).
- Each thing you name is hidden from view so that you have to remember what things were already named. It gets extra hard if you play a few games in a row and remember hearing a thing named but can’t remember if it was this game or a previous one.
- If you say something that someone else already said during this game, you are out and can no longer take turns.
The kids are motivated to make up answers in order to delay bedtime. Here is the code for the game:
Yes, 10 lines. That’s all you need. It runs in a jupyter notebook.
Here is a brief example of the game in action:
Player 1: Cucumber
Player 2: Lettuce
Player 1: Banana
Player 2: Celery
Player 1: Apple
Player 2: Cucumber
Computer: Cucumber was on the list! You are OUT!
And then player 1 wins.
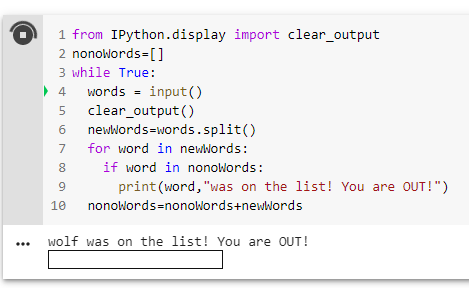
We eventually added a second game that was more focused on vocabulary than memory, where you have to guess if a word is real or fake. The real words come from a big list and the fake words come from another big list.
Here is the code for the second game:
Like the first game, everyone takes a turn at the start, and progressively fewer players survive until there is only one player left (the winner).
This year I thought to myself that these games could be useful as a testing ground for a machine learning project. The second game can be solved with a dictionary or a few other memory-based appraoched. However, the first thing you notice about the first game (the memory game), is that there is no rule in the code for what is a good word to pick. That was just me enforcing what I think makes sense as a new word as we play.
Automating the memory game
The first thing we need to do is prepare the memory game for a more structured implementation. Topic selection (e.g., food) is outside the scope of the code. In the version with a computer that plays against people, we need to make the topic selection explicit. Rather than making lists of every possible topic and the words in that topic, we can pick 5 words from within the topic at the start of each game in order to define the topic. This is referred to in the academic literature as a seed set. There are plenty more examples of research work in this area such as this and this.
To enable our code to play the game, we need to have our computer game player pick words within the topic that it has not yet seen. You may be wondering what is new about this task. Why not simply use embedding vector similarity and get sets of similar words to some starting word? For example, word2vec and fasttext have similar words methods:
word_vectors.most_similar in gensim
model.get_nearest_neighbors in fasttext
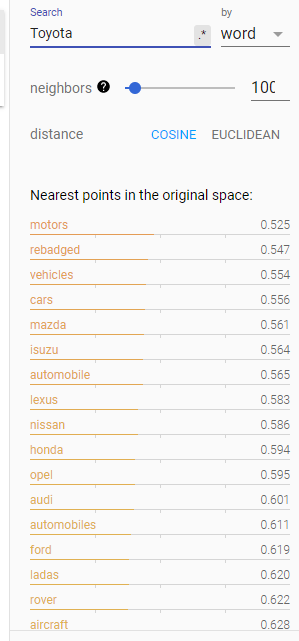
The answer is that similar word context does not mean similar topic. When looking for words in the same topic as ‘Honda’, we don’t want the word ‘reliable’. Rather, we want words like ‘Toyota’ and ‘Tesla’. Although sematic similarity is on the way to getting us where we want to go, similar context alone is not descriptive enough to generate a topic from our seed set of topic words.
Recent work called FUSE with a nice MIT license is available here, from the paper “FUSE: Multi-Faceted Set Expansion by Coherent Clustering of Skip-grams”. Although they don’t provide the dataset, we can try and use our own dataset from wikipedia or a similar open source text dataset. We start off by grabbing pretrained models for gloVe and BERT as instructed in the FUSE installation instructions. The complete code for this adventure is available here:
My first attempt was to use the supplied dataset of 45,471 sentences for training the set expansion model. It was too small and so, as noted in the code’s instructions, it fails to generate clusters. The clustering code deletes small clusters. I did not try to contact the third part mentioned in order to access their dataset, which seems to be a private dataset.
For my second attempt, I merged the NLTK datastes gutenberg, inaugural, brown, and webtext into a corpus of 186,670 sentences. The FUSE clustering code still deleted small clusters, and so I removed the cluster deletion code. The results were poor. For example, given the seed words ‘apple’, ‘orange’, and ‘grape’, the expanded set that came back was [‘music’, ‘black’, ‘musical’, ‘grape’, ‘white’, ‘gold’, ‘live’, ‘celebrity’, ‘green’, ‘red’, ‘royal’, ‘star’, ‘best’, ‘rock’, ‘new’, ‘commercial’, ‘radio’, ‘country’, ‘tv’, ‘national’]. And so, I planned to try on an even bigger dataset.
For my third attempt, I was going to train on the much larger c4 dataset, but then I realized I could try another pretrained library, this time from Intel labs in Israel. I actually linked to this research above but tried FUSE first. I guess that was just my luck.
The Intel set expansion solution worked on the first try. There is also a server version and a user interface packaged with their demo. Here are some interesting results from my initial experiments:
- Seed words: ‘apple’, ‘orange’, ‘grape’. Expanded list: ‘pear’, ‘apricot’, ‘peach’, ‘hazelnut’, ‘pomegranate’, ‘cherry’, ‘strawberry’, ‘plum’, ‘lavender’, ‘almond’
- Seed words: ‘rabbit’, ‘horse’, ‘duck’. Expanded list: ‘hare’, ‘fox’, ‘boar’, ‘venison’, ‘dog’, ‘partridge’, ‘emu’, ‘pig’, ‘pigeon’, ‘hawk’
- Seed words: ‘chair’, ‘table’, ‘desk’. Expanded list: ‘desks’, ‘tables’, ‘chairs’, ‘a desk’, ‘the dressing table’, ‘boards’, ‘sofa’, ‘the chairs’, ‘a small table’, ‘drawers’. We can see now that the model does not recognize that singular and plural forms of an object are the same thing (e.g., ‘desk’ vs ‘desks’). The model also missed removing stopwords (e.g., ‘desk’ vs ‘a desk’ and ‘chair’ vs ‘the chairs’).This could be fixed up with a simple post-processing step.
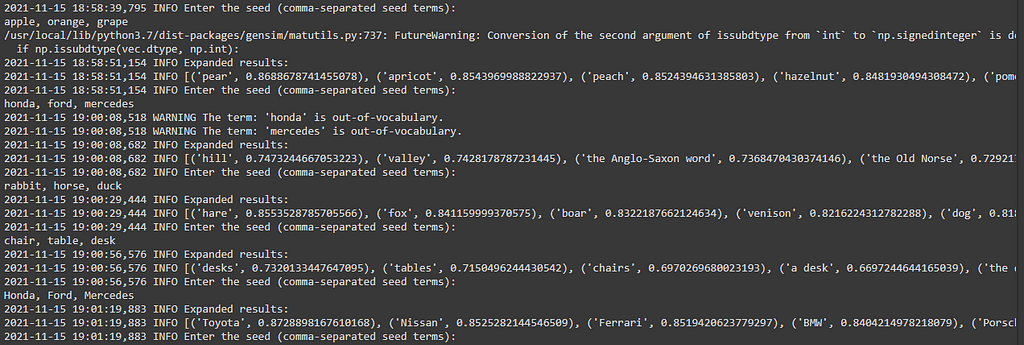
- Seed words: ‘honda’, ‘ford’, ‘mercedes’. Expanded list: ‘hill’, ‘valley’, ‘the Anglo-Saxon word’, ‘the Old Norse’, ‘a fortified place’, ‘a ford’, ‘glen’, ‘the Celtic word’, ‘the ford’, ‘a moor'. We can see this case failed pretty badly. The words ‘honda’ and ‘mercedes’ were not in the model vocabulary. This indicated that the model is case-sensitive. Since only the word ‘ford’ was left, the model found words with vectors near the word ‘ford’. If we instead capitalize the car brand names we get a better result. Seed words: ‘Honda’, ‘Ford’, ‘Mercedes’. Expanded list: ‘Toyota’, ‘Nissan’, ‘Ferrari’, ‘BMW’, ‘Porsche’, ‘Renault’, ‘Jaguar’, ‘Mazda’, ‘McLaren’, ‘Mercedes-Benz’
Note that the car names did not contain other things related to cars, like the word2vec results did. This is great!
Conclusion
We can now see that certain word games played by people can also be played by computers. To get there, the computers need to be trained to understand the words contained in a topic, and set expansion is a nice way to achieve that capability. These models can be fine-tuned and also can be trained from scratch.
The code for this article is available HERE.
If you liked this article, then have a look at some of my most read past articles, like “How to Price an AI Project” and “How to Hire an AI Consultant.” And hey, join the newsletter!
Until next time!
-Daniel
linkedin.com/in/dcshapiro
daniel@lemay.ai
Games for Bots was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3oDhxzi
via RiYo Analytics








No comments