https://ift.tt/3xC4Tor Illustration Photo by Lucas Fonseca from Pexels Easy Kaggle Offline Submission With Chaining Kernel Notebooks ...

Easy Kaggle Offline Submission With Chaining Kernel Notebooks
A simple guide on facilitating your Kaggle submission for competitions with restricted internet access using Kaggle kernel as an intermediate step as data storage.
Are you new to Kaggle? Have you found it a fascinating world for data scientists or machine learning engineers but then you struggle with your submission? Then the following guide is right for you! I will show you how to make your experience smoother, reproducible, and extend your professional life experiences.
Best Practices to Rank on Kaggle Competition with PyTorch Lightning and Grid.ai Spot Instances
Quick Kaggle introduction
Kaggle is a widely known data science platform connecting machine learning (ML) enthusiasts with companies and organizations proposing challenging topics to be solved with some financial motivation for successful solutions. As an ML engineer, you benefit from an already prepared (mostly high-quality) dataset served for you ready to dive in. In addition, Kaggle offers discussions and sharing & presenting their work as Jupyter notebooks (called Kernels) and custom datasets.
In the end, if you participate in a competition and want to rank on the leaderboard, you need to submit your solution. There are two types of competitions they ask the user to (a) upload generated predictions in the given submission format or (b) prepare a kernel that produces predictions in the submission format. The first case is relatively trivial and easy to do, so we’ll focus only on kernel submissions.
These competitions include just a minimal testing dataset for user verification of his prediction pipeline. For data leaking and other security reasons running kernels are not allowed to use the internet (as users could upload all test data to their storage and later overfit the dataset). On the other hand, this makes submissions not easy if your kernel needs to install additional dependencies or download your latest trained model.

The dirty way with datasets
The intuitive and first-hand solution is to create storage with required extra packages and a trained model. For this purpose, you can use/create a Kaggle dataset and upload all data there. I ques that even you can see that it is banding one tool for a different purpose.
We have described this process in our previous post. In short, the process to create such a dataset is (1) downloading all your dependencies locally, (2) renaming all source packages ending with .tar.gz as Kaggle perform recursive extraction of all archives to folders, and (3) uploading packages to the new dataset. Then on the inference kernel, (4) rename source packages back and (5) install all packages with pip sourced from the Kaggle dataset.
Submitting Model Predictions to Kaggle Competitions
You feel how many steps are required. Even you make it all, you may face some compatibility issues as packages downloaded for your local environment may not be compatible with your later Kaggle kernel environment. And there are several more corner cases.
Chaining kernels to build one above another
Let us think a bit about how a good data scientist workflow would be. The three main steps are (1) Exploratory Data Analysis, (2) Modeling and problem-solving, and (3) Inference (and predictions submission). A the beginning of this workflow, we have an input dataset, and at the end, we expect to be the competition submission.
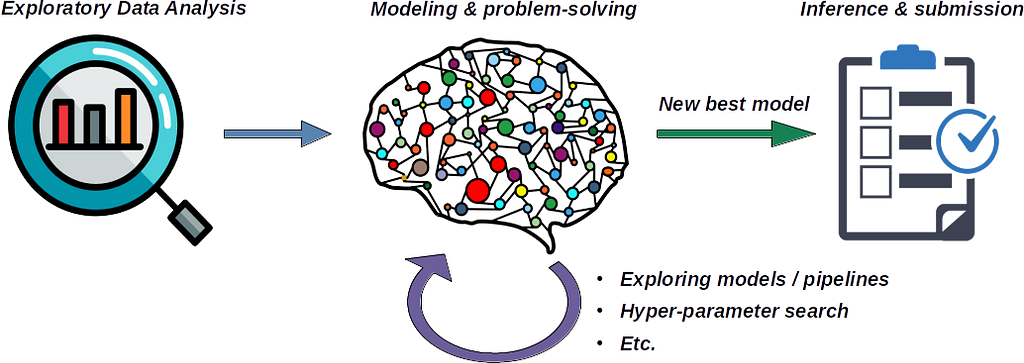
We can have all three steps in a single notebook (which would make it heavy, and usually a user doesn’t need to run all) or cover each step with a single kernel. The decoupled research stages in consecutive notebooks allow us faster iteration and also partial saving intermediate results. For example, you will do EDA only once, then you will iterate on training models (extending pipeline or performing a hyper-parameter search), and when you obtain the new best model and you run your inference for submission.
The great news is that Kaggle kernels preserve some (limited) outputs from their run. We will rely on this feature in our proposed solution. In short, we can save our model and download all needed packages in the training kernel (which has an internet connection) and load them in the following inference kernel with is cut from the internet.

Let us demonstrate it on our two Kaggle kernels for Toxicity rating. For simplicity, we merged the trivial EDA and model training in a single notebook. So the first is 🙊Toxic comments with Lightning⚡Flash and the second is 🙊Toxic comments with Lightning⚡Flash [inference].
Downloading required packages
The package downloading is very similar to installing with a PyPI registry. In addition, we specify a folder for saved python wheels with the dest argument.
pip download lightning-flash[text] \
--dest frozen_packages \
--prefer-binary
Advanced users may need to install their packages or make some hotfix in their fork of a standard package. Such package is not registered on PyPI, but it is setuptools complete. For this case, you can still use pip and tell it to create a wheel package from the given source.
pip wheel 'https://github.com/PyTorchLightning/lightning-flash/archive/refs/heads/fix/serialize_tokenizer.zip' \
--wheel-dir frozen_packages
If you still need to install package extras, you add them at the end of the URL #egg=lightning-flash[text] . Moreover, you can also prune your downloaded wheels from existing packages in the base environment, such as PyTorch.
rm frozen_packages/torch-*
Linking kernels as data-source
The second part is adding the previous kernel as a data source for the following one. We open configuration in the top right corner in the inference kernel and select the “Add data” option.
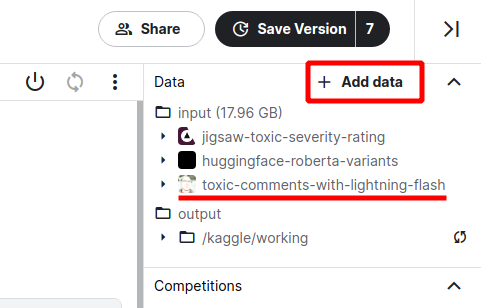
Then we need to find our kernel. We can search by name or browse our past work, as we show in the following diagram:
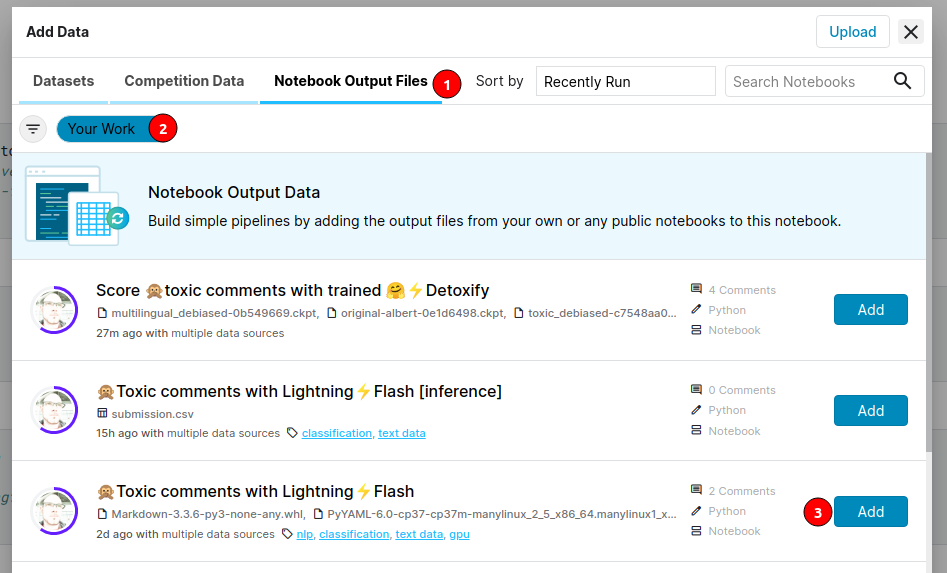
We are almost done! We initialize the environment with connected past kernel’s outputs by installing the required packages from the “local” path. We disable indexing with the following command as we are offline anyway and set the path to the folder with all packages.
pip install lightning-flash[text] \
--find-links /kaggle/input/toxic-comments-with-lightning-flash/frozen_packages \
--no-index
Using additional data and checkpoints
It can still happen that we need some additional online sources. If the data are publically available, we can download them, for example, released checkpoint:
mkdir checkpoints
wget https://github.com/unitaryai/detoxify/releases/download/v0.1-alpha/toxic_original-c1212f89.ckpt --directory-prefix=checkpoints
With a need for extensive model training and limited free Kaggle computing resources, you may still need to create a particular dataset just for your submission’s models.
HyperParameter Optimization with Grid.ai and No Code Change
About the Author
Jirka Borovec holds a Ph.D. in Computer Vision from CTU in Prague. He has been working in Machine Learning and Data Science for a few years in several IT startups and companies. He enjoys exploring interesting world problems and solving them with State-of-the-Art techniques, and developing open-source projects.
Easy Kaggle Offline Submission With Chaining Kernels was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3D4rif6
via RiYo Analytics








No comments