https://ift.tt/3o2DJ6S Part 3 -Leaderless Replication In the modern era of the internet, data replication is everywhere. From bank account...
Part 3 -Leaderless Replication
In the modern era of the internet, data replication is everywhere. From bank accounts to Facebook profiles to your beloved Instagram pictures, all data that people deem important are almost for sure to be replicated across multiple machines to ensure data availability and durability. Previously I’ve talked about single-leader replication and multi-leader replication. In this article, we will explore one of the most common replication strategies called leaderless replication.
Leaderless replication adopts a philosophy that is contrary to that of leader-based replications. Nodes in the leaderless setting are considered peers and all of them accept writes and reads from the client. Without a leader that handles all write requests, leaderless replication offers better availability.
Theory
Figure 1 demonstrates the basic data flow of leaderless replication. Upon write, the client broadcasts the request to all replicas instead of a special node (the leader) and waits for a certain number of ACKs. Upon read, the client contacts all replicas and waits for some number of responses. Because the client waits for many responses, this approach is also called a quorum. As we shall see later, how we configure the quorum is of critical importance as it determines the consistency of our database.
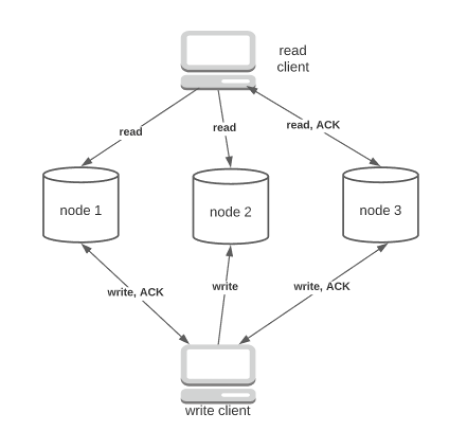
The write request in Fig. 1 is completed two out of the three replicas sent ACK to the client. The read request is completed when one out of the three replicas returns the latest value. You would probably notice by now that the read and write numbers are entirely hyperparameters chosen by the application. The natural question is how we determine the read/write number.
Deep Dive
First, I want to define some parameters for a concise discussion. Denote the read number as r, the write number as w, and the total replica as T. For instance, the quorum in fig. 1 has r=1, w=2, T=3.
The quorum configuration used in fig.1 is seriously flawed as it can return stale values. Consider the following case:
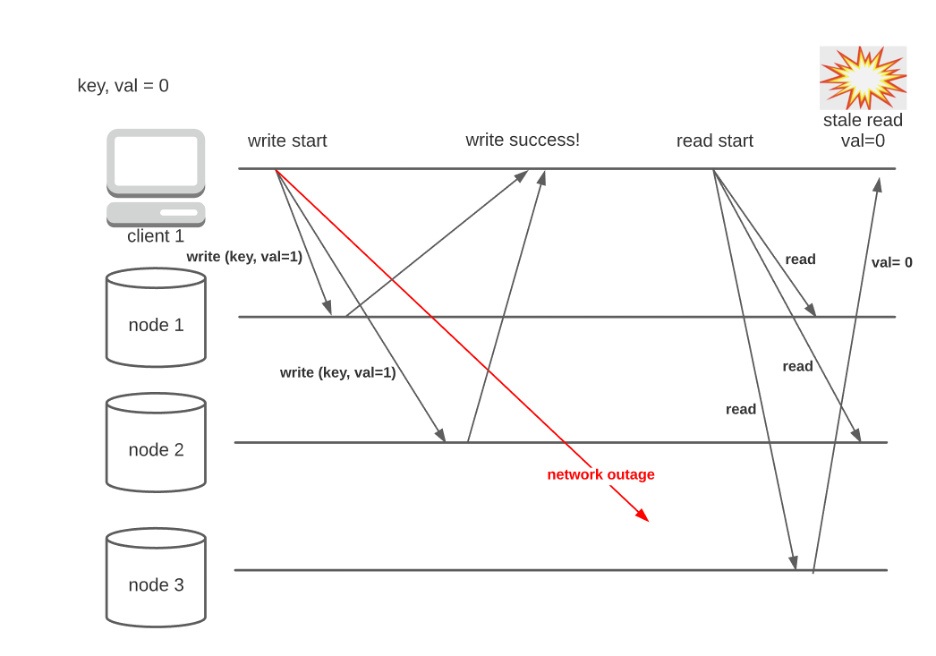
As you can see, ill-chosen r and w can lead to stale reads even after a successful update. So how do we configure the quorum to achieve better consistency?
Strict Quorums
If someone puts three apples into five buckets, with each bucket having a capacity of one apple, how many buckets do I need to check to get an apple? The best scenario is one, if I’m lucky. In the worse-case scenario, I need to check no more than three buckets. Now change the context into database. If I successfully update w=3 replicas out of T=5, how many nodes do I need to contact (r) for the updated value? The answer is r=3.
Strict quorum is a type of configuration that requires w + r>T. Strict quorum implies that, since w + r > T, read consistency is almost guaranteed (not 100%, I’ll explain later) due to the overlap between nodes with updated value and those who returned the read request (fig 3).
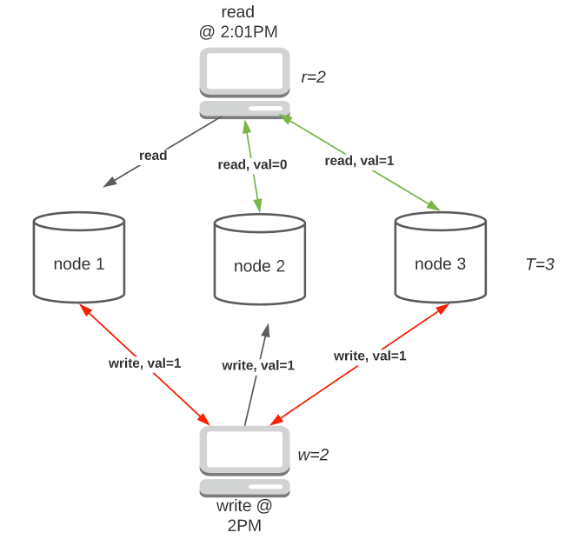
Leaderless replication is highly available because all nodes accept read/writes. With strict quorum, the system still works when min(T-w, T-r) nodes are down. For instance, the configuration in Fig.3 can tolerate min(3–2, 3–2)=1 node outage.
Sloppy Quorums and Hinted Handoff
While strict quorum offers high availability and low latency (only waiting for the fastest few nodes), it is certainly possible that the client can be cut off from many nodes and hence unable to reach quorums during a network partition. For systems with an even lower tolerance for downtime, sloppy quorum might be a good alternative.
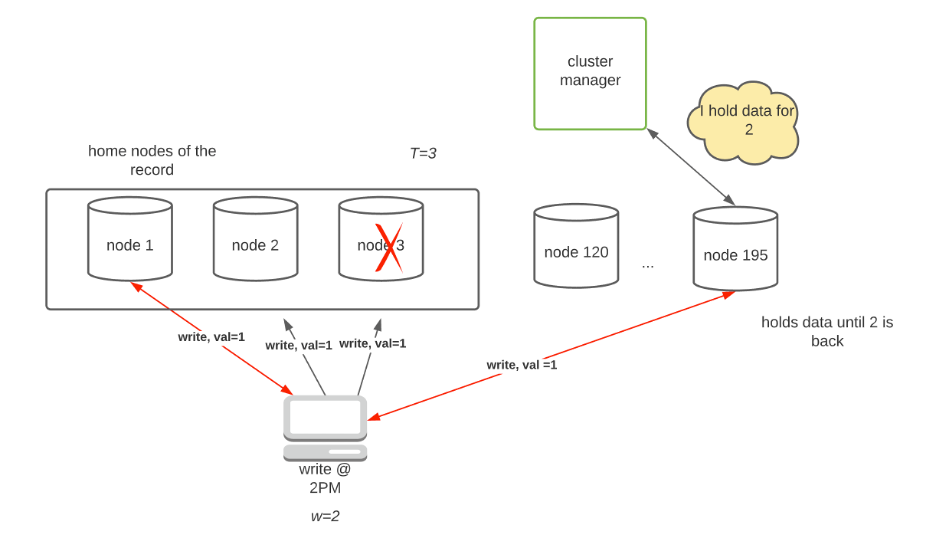
In a large system, there are many nodes (N) serving different partitions of the database with each row of data replicated on T nodes. If too many home nodes are down, leading to insufficient quorums, others from the remaining (N-T) nodes will step in to accept writes requests temporarily until the home nodes are back online (handoff).
In Fig. 4, node 195 accepts the write request when nodes 2 and 3 are unreachable. Once they rejoin the cluster, the cluster manager will ask node 195 to transfer all writes to the home nodes.
It is important to note that there are two options when it comes to read requests. We can enforce strict quorum (read-only from home nodes), which offers better consistency. If higher availability is needed, one can enable sloppy quorum for reads as well (for instance, Riak does this). However, this trade-off leads to potential stale reads as W + R > T does not guarantee an overlap between writes and reads.
How W and R impact availability
W and R are two interesting parameters to tweak. When W/R is large, it takes longer for the system to complete the request, since it must wait for ACK from more nodes. For systems with a balanced read/write ratio such as online chat Apps, it is sensible to set W and R to T/2 + 1 for good performance. However, for systems that are read-heavy, we can choose a small R and large W.
Conflict Handling
Like multi-leader replication, conflicts arise from the inherent lack of request ordering of the leaderless architecture. I’ve explained some conflict resolution techniques in the last article about multi-leader replication — read repair, anti-entropy, and custom algorithm (versiong vector, siblings. etc)
Caveats of Leaderless Replication
The illusion of Strong Consistency
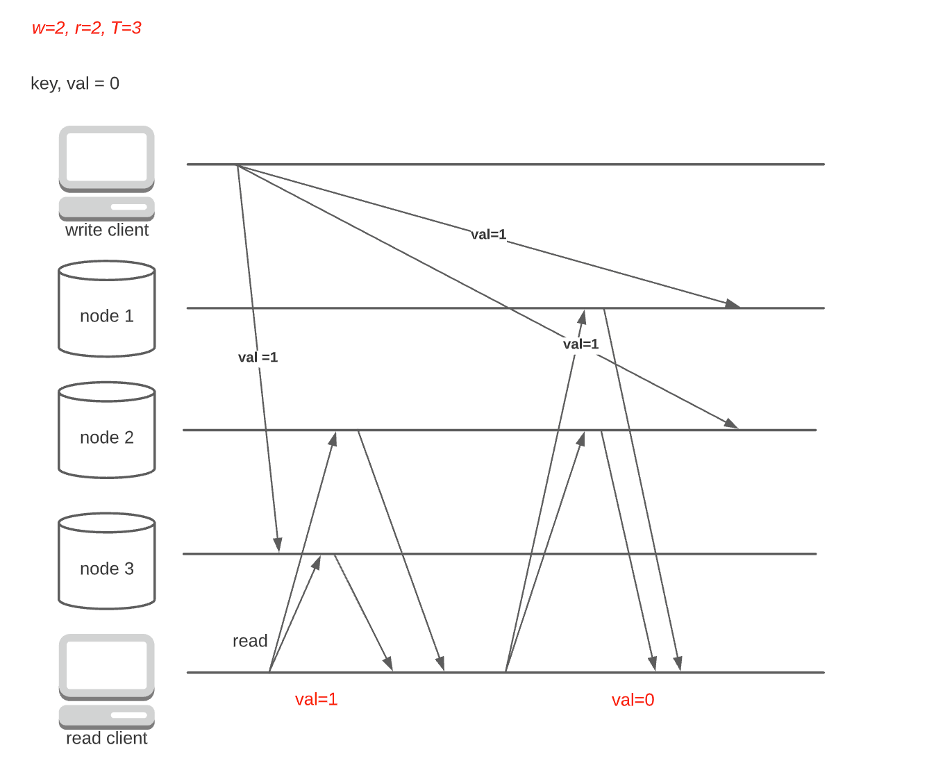
The strict quorum may leave a false impression that it’s a guarantee of strong consistency (linearizability). While it is true that strict quorums ensure updated read, it can also behave strangely in the event of network delays. Consider the following case:
Strong consistency (linearizability) mandates that no version-flipping is allowed (read twice, first get new value and then stale value). Even with strict quorum, the system cannot guarantee linearizability when the network is unstable.
Tricky Failure Handling
Another complication of leaderless replication is failure handling. Consider the case where a write request is received by all nodes, but some ACK are delayed(Fig 6). The write request is considered a failure, but the client might still be able to see the dirty value. This problem is inherent to leaderless architecture since individual nodes have no global information about the status of a request. For node 2, the failed request is no different from any other requests.
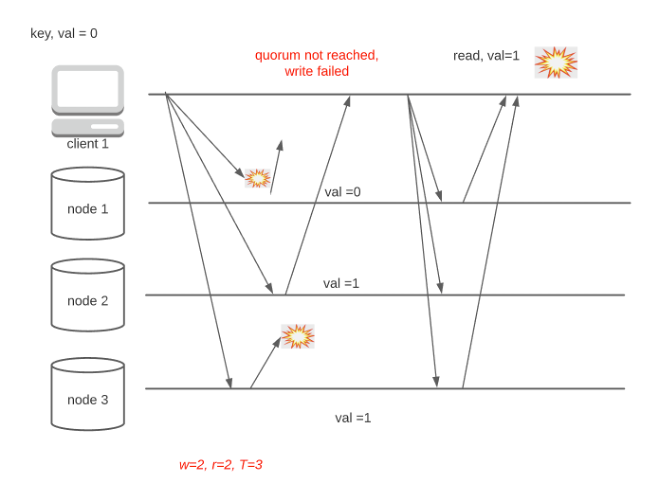
Implementing transactions is an effective technique to address the problem. However, transaction amplifies chatters several times between the nodes and significantly increases the system delay.
Summary
Like many engineering designs, picking the right replication strategy is all about trade-offs. When using multileader architecture, you should carefully evaluate the following questions to come up with the best configuration:
- What conflict resolution to use? You can’t get around with conflict resolution in this setting. There are algorithms such as last write win or smart routing that can resolve conflicts automatically by trading off data durability or availability. In addition, custom conflict resolution can be used to handle the tough choice of the clients. You should carefully evaluate the SLA of the system before making any decisions.
- How important is availability? If availability is crucial to your system, consider using leaderless replication or even sloppy quorum with hinted handoff.
- How important is consistency? Strict quorum does not guarantee linearizability. You can deploy strategies such as synchronous read repair to ensure strong consistency, but it reduces the overall availability of the system.
Database Replication Explained 3 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3o4thfm
via RiYo Analytics








No comments