https://ift.tt/3l2JTSR An overview and hands-on tutorial of the codeT5 model Photo by Pankaj Patel on Unsplash With the recent releas...
An overview and hands-on tutorial of the codeT5 model

With the recent release of the OpenAI Codex model, code generation is becoming a hot topic in the NLP world, and is it not just hype. If you watch one of the Codex demos, you will see how these models will shape the future of software programming. However, from a researcher’s perspective, working with a Codex model might be unreachable if the needs go beyond trying it via the API since the pre-trained models are not publicly available. Technically, you can replicate Codex using the published paper, but you will need a large GPU cluster that only a few have access to or can afford. This limitation will, in my opinion, slows down research. Imagine how many fewer BERT downstream applications we would have if the authors did not share the pre-trained weights. Hopefully, Codex is not the only code generation model out there.
This post will overview codeT5, an encoder-decoder code generation model with publicly available pre-training checkpoints that you can try today. Moreover, this post contains a hands-on tutorial on how to use this model.
CodeT5 Overview
CodeT5 [1], as the name suggests, is based on the T5 [2] encoder-decoder model. Compared to other code generation models, it uses a novel identifier-aware pre-training objective that leverages code semantics rather than treating the source code like any other natural language (NL) text. This model shows promising results in code generation and other tasks like code summarization, code translation, clone detection, and defect detection in many programming languages.
The authors released two pre-trained models: a small version with 60 million and a base version with 220 million. They also released all their fine-tuning checkpoints in their public GCP bucket. Furthermore, both pre-trained models are accessible from the popular huggingface library.
Pre-training
CodeT5 is pre-trained using two distinct objectives sequentially. In the first 100 epochs, the model is optimized with an identifier-aware denoising objective that trains the model to differentiate between identifiers (i.e., variable names, function names, etc.) and specific programming language (PL) keywords (e.g., if, while, etc.). Then, optimized using a bimodal dual generation objective for 50 epochs. The last objective aims to improve the alignment between the NL descriptions and code.
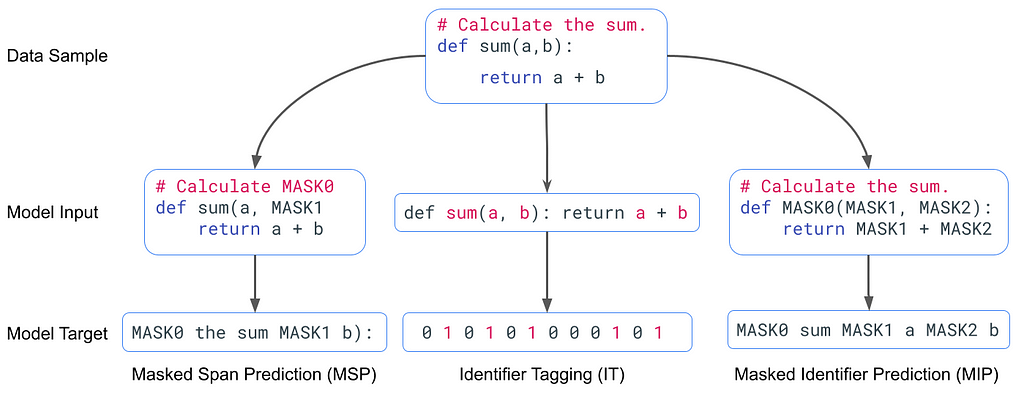
Identifier-aware denoising objective. A denoising objective in Seq2Seq models masks the input sequence with a noising function. Then, the decoder tries to recover the original input. The identifier-aware denoising alternates with an equal probability between three tasks:
- Masked Span Prediction (MSP). This task is similar to the one used in T5 pre-training, with the exception that they used whole work masking to avoid masking sub-tokens (.e.g, ##ing). This task improves the model’s ability to capture PLs syntactic information, which improves code generation performance.
- Identifier Tagging (IT). In this task, the model is trained to predict whether a token is a code identifier, forcing the model to learn code syntax and data flow.
- Masked Identifier Prediction (MIP). All the identifiers (i.g., variable name, function names, etc.) are hidden in this task. Also, all the occurrences of the same identifier are masked using the same sentinel token (i.e., MASK0). The model is trained to predict the sequence composed of the identifiers and the matching sentinel tokens in an auto-regressive manner. MIP aims to improve PL semantic understanding, which is helpful for defect detection tasks.
The figure below shows an example of the model input and target for each task of the identifier-aware denoising objective for the same data sample.
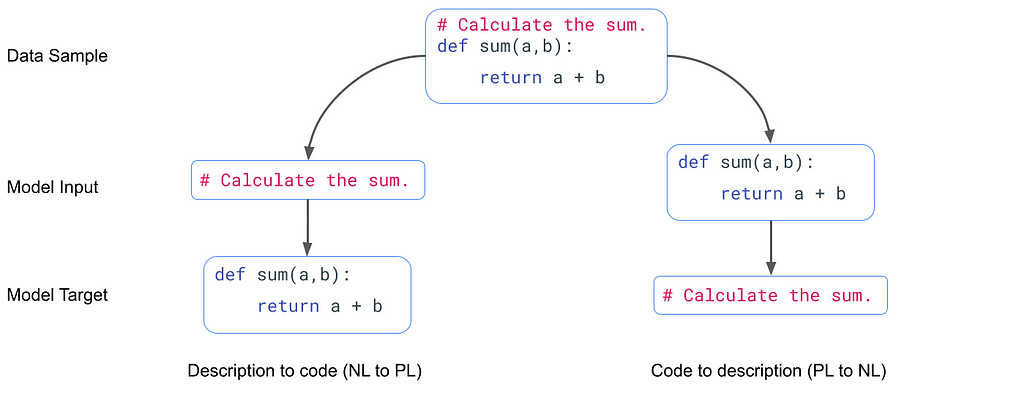
Bimodal dual generation. The model is trained for bidirectional conversion, either from code to NL description or from NL description to code simultaneously. This objective is similar to T5’s span masking, where here, the masked span is either the entire NL description tokens or code tokens. This objective aims to close the gap between pre-training and fine-tuning. In pre-training, the decoder sees only discrete masked spans and identifiers, while in fine-tuning, the decoder generates the full NL descriptions or code. The figure below shows an example of the model input and target for each task for the same data sample.
Tokenizer
CodeT5 uses a code-specific tokenizer since the default T5 tokenizer encodes some common code tokens as unknown tokens. For example, the curly bracket { is mapped to the unknown token <unk>.
The CodeT5 tokenizer is a Byte-Pair Encoding (BPE) [3] tokenizer with a vocabulary size similar to T5 (32k) plus some special tokens. During pre-trainer, this tokenizer skips all non-printable characters and tokens that occur less than three times, which results in a reduction of up to 45% of the tokenized sequence. There are two advantages to a shorter target sequence. First, it accelerates training. Second, it makes the generation tasks easier.
Pre-training Dataset
CodeT5 is pre-trained on the publicly available CodeSearchNet dataset [4] containing about 2 million training samples consisting of code and description pairs in six PLs (Javascript, Java, Go, Python, Ruby, and PHP). Moreover, the authors collected C and C# datasets from BigQuery. However, note that C and C# dataset is not released to the public. But, the fine-tuned models are available.
Fine-tuning
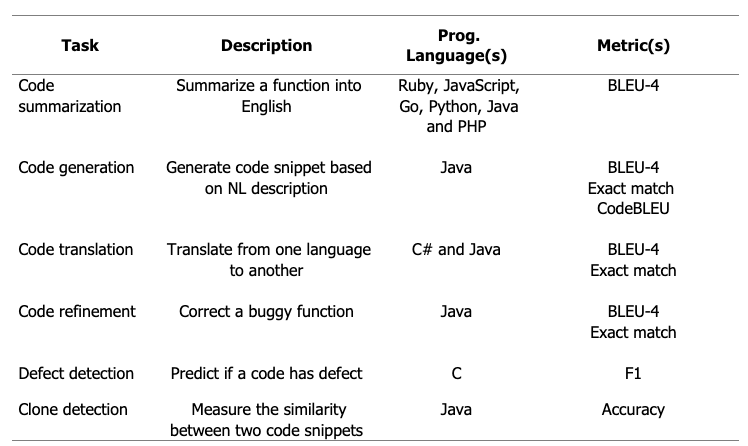
CodeT5 has been fine-tuned on a large set of downstream tasks in various PLs. The following table summarizes all the tasks.
My thoughts
In my opinion, CodeT5 is an interesting model since it can achieve good results in multiple downstream tasks with the same pre-trained model, especially with the multitask model. Also, the model requires less data for fine-tuning, which means a short training time. For example, the java code generation dataset contains only 100k training samples. Reducing the data requirement is a crucial aspect since, as you might know, data gathering is a time-consuming task. However, there are some points that I think the authors could have improved:
- The authors claim the superiority of the encode-decoder model compared to the encoder-only and decoder-only models. However, It would have been good to compare with the Codex model since it was available when this paper was released.
- The authors used CodeBLEU as an evaluation metric for code generation tasks, which is not ideal, as explained in the Codex paper. I understand that they chose the metric to compare with current results. However, it would have been nice to see the results on the Human Eval dataset [5], which evaluates functional correctness via unit tests.
Hands-on Tutorial
Using the Pre-trained Models
The following example shows how to use the pre-trained models using the huggingface library. This model can perform any of the pre-training tasks. However, you will only use the pre-trained model to do your own fine-tuning.
Using the Fine-tuned Models
To use the fine-tuned models, you have to download the model binary you want and the correct model configuration file. The following script downloads both.
Once downloaded, you are ready to use the model. The example below will predict the docstring a python function.
Fine-tune Your Model
On top of pre-trained and fine-tuned models, the authors also shared their source code, which means that you can fine-tune your model. The example below trains the python code summarization fine-tuning. For more information, check out their repository.
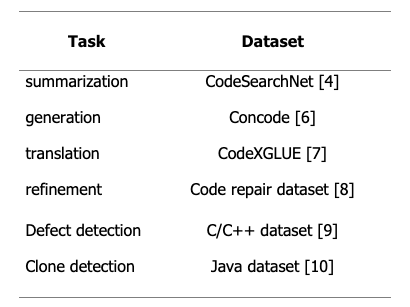
Note that the data used in the script above is a collection of existing public datasets shared by the authors of CodeT5 [1]. The following table describes the source of each sub-dataset.
Conclusion
This post overviewed the CodeT5 model and provided examples of using public checkpoints and training your model. Also, it contains my personal thoughts. For more details, I invite you to read the CodeT5 paper and go over their source code. I know that Codex is the new kid in town, but CodeT5 is the best model (I think) you can train on any reasonable infrastructure currently.
Also, I’m working on a VS code extension that lets you connect any code generation model to the VS code autocomplete. So, stay tuned!
*All the pictures are by the author unless stated otherwise.
Before You Go
Follow me on Twitter, where I regularly tweet about software development and machine learning.
References
[2] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
[3] Neural Machine Translation of Rare Words with Subword Units
[4] CodeSearchNet Challenge Evaluating the State of Semantic Code Search
[6] Mapping Language to Code in Programmatic Context
[7] CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
[8] An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation
[10] Detecting Code Clones with Graph Neural Network and Flow-Augmented Abstract Syntax Tree
Beyond Codex: A Code Generation Model That You Can Train was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/30VwEMc
via RiYo Analytics








ليست هناك تعليقات