https://ift.tt/3rawz2B A Nontrivial Elevator Control System in a Train Station by Reinforcement Learning Why elevators in train stations a...
A Nontrivial Elevator Control System in a Train Station by Reinforcement Learning
Why elevators in train stations are different and how RL can optimise the overall service quality

Motivation
Today’s urban life is out of imagination without the presence of elevators and the elevator controller algorithm has been well studied by different techniques including reinforcement learning [1]. A glance over the references gave the impression that the majority of studies has focused on elevators installed in high-rise buildings while those in train stations are barely discussed. Elevators in train stations, however, deserve their own attention because of their obvious difference from systems in buildings.
An elevator-train-station system usually has the following properties:
- The train platforms of different train lines are located in different floors. People having entered the station want to go to one specific floor to take the trains while those having arrived on train would either exit the station or change the train on another floor.
- In rush hours, there does not exist one direction that everyone goes to as happens in buildings. Some might want to exit the train station while others might want do a train change on another floor.
- People having arrived in the station on train wait in front of the elevator almost at the same time while those coming from outside of the station not necessarily fall into this case.
- Elevators are usually reserved for people with heavy luggage or baby strollers so that they might not have a huge capacity. Moreover, those with baby strollers might not have a second choice other than staying in the elevator waiting list until being transported.
A good example is the Gare de Lyon in Paris, a station with 2 underground floors on which you find 2 different train lines’ platforms respectively.
From my personal experience, it usually takes quite a while to get to floor -2 from floor -1 for a train change with my baby stroller by elevator.
In the following, I am going to simulate an elevator- train-station environment that can be easily modified for your own purpose and reused and implement reinforcement learning to get the optimal policy for the elevator controller.
An elevator — train station system
Consider an elevator in a train station with 3 floors such that floor 0 is the ground floor as entrance/exit and floor 1, 2, 3 are train platforms. People waiting for the elevator on floor 0 are coming from outside, willing to go upstairs to take trains while people on other floors are brought by scheduled trains, either exiting the station or going to another floor to for a change. We suppose that people can arrive at floor 0 from outside at any moment while people arrive at a positive floor on train at the same time.
For the sake of simplicity, we consider one single elevator in the first place. This simplification indeed does not remove much generality because it is always the case that only one elevator is available on a train platform.
The three positive floors are train platforms of different railway lines: line A on floor 1, line B on floor 2 and line C on floor 3. Every 10 minutes, line A arrives at the first minute, line B the second and line C the third. In addition, every time a train arrives, 5 people will join the waiting list of the elevator together. This makes sense because in general, only those with luggage or baby strollers want to take the elevator while others will take this time-consuming choice. For every person having arrived on train he will have {0.2, 0.2, 0.6} probability to go to the two other floors and the ground floor respectively. Meanwhile, we suppose that every 30 seconds, there is 0.9 probability that one person will join the waiting list on floor 0 during the first 3 minutes of every 10 minutes. For every person on the ground floor, he will have 1/3 probability to go to each of the three underground floors.
The max capacity of the elevator is 5 people. It looks like a small capacity but remember, they have their luggage as well! Moreover, the elevator need 10 seconds every time it stops and 2 seconds to travel from one floor to another.
To resume, we have:
- One ground floor, three positive floors.
- Three groups of 5 scheduled people in the elevator waiting list and one group of non spontaneous people.
- An elevator with a capacity of 5 people.
The figure blow is a sketch of the system (forget about my bad drawing, I did not make any progress from kindergarten).
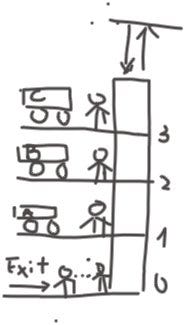
Building the RL environment
Before going on step further, I give at the beginning of this section some necessary elements for reinforcement learning.
Briefly, in RL, an agent interacts with the environment in discrete time or continuously. At time step, the agent applies an action according to the current state of the environment according to certain policy, leading to a new state and receiving a reward which measures the quality of the state transition. The goal of RL is to learn a policy, either deterministic or probabilistic to maximise the accumulative reward.
Let us go back to the elevator controller system.
The state of the environment is a R⁷ vector (floor_0_up, floor_1_up, …,floor_3__down, occupancy, position) where floor_i^{up/down} is either 1 or 0, being 1 iif there is a demand of going up/down at the floor i outside of the elevator, occupancy an integer as the total number of passengers inside the elevator and position the current floor on which the elevator is. Note that we only allow going up at floor 0 and down at floor 3.
The reward of function is defined as -(occupancy+sum_i floor_i^{up/down}), that is, the total number of the demands insider and outside of the elevator. In other words, the only situation for which the reward is 0 is when no passengers are waiting in the system, neither inside nor outside of the elevator.
To build the RL environment, I used open AI Gym, a toolkit for developing and comparing reinforcement learning algorithms. How to build a custom Gym environment is not the purpose of this article and readers can find instructions for their own RL environment in want [2]. Below is the __init__ and reset function of the Elevator class.
import gym
from gym import spaces
class Elevator(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
#observation space
# states0: floor_0_up
# states1: floor_1_up
# states2: floor_1_down
# states3: floor_2_up
# states4: floor_2_down
# states5: floor_3_down
# states6: occupancy
# states7: position
super(Elevator, self).__init__()
self.done = 0
self.reward = 0
self.states = np.zeros(8)
self.states[0]=1
self.last_time = 0
self.time = 0
self.max_occupancy = 5
self.action_space = spaces.Discrete(3) # 0 stop, 1 up, 2 down
self.observation_space = spaces.MultiDiscrete([2,2,2,2,2,2,6,4])
def reset(self):
self.states = np.zeros(8)
#suppose that there are already 2 people
# waiting on the first floor at the beginning of the session
self.states[0]=1
self.last_time = 0
self.time = 0
self.floor_0_waiting = 2
self.floor_0_waiting_list = [1,2]
self.floor_1_waiting = 0
self.floor_1_waiting_list = []
self.floor_2_waiting = 0
self.floor_2_waiting_list = []
self.floor_3_waiting = 0
self.floor_3_waiting_list = []
self.inside_list = []
self.done = 0
self.reward = 0
return self.states
The complete code in this article is available on Github for those who are interested in more details.
Training and results
To train the system, I will use the DQN: deep Q-network. Note that the total cumulative reward of the RL system is also called a Q-value for a given initial state and an action. The desired policy should be the one that maximise the Q-value which are in general unknown and thus yields Q-learning as a “cheatsheet” for the agent [3]. The DQN aims to approximate the Q-value by a deep neural network. In my implementation, I built a DQN with 2 layers of size 64 with the help of stable-baselines, a set of improved implementations of reinforcement learning algorithms based on OpenAI Baseline. This implementation requires only 3 lines of code:
elevator= Elevator()
elevator.reset()
model = DQN('MlpPolicy', elevator, verbose=0)
model.learn(total_timesteps=1e5)
Before training, I let the elevator do random actions and it takes more than 800 seconds to empty the waiting list from the beginning of the session. While after 1e5 training time steps, the elevator managed to empty the waiting list in 246 seconds on my local trial, that is, 4 minutes instead of more than 10 minutes (according my experience, I did wait for more than 10 minutes in a waiting line in a train station sometimes!). This stands out significant improvement of the elevator controller system.
Conclusions
Of course, I made many simplifications to the system, e.g. people on train join the waiting at the same time and no others will join when no train passes but the result of training is still exciting. Moreover, I suppose that there is only elevator in the system which might not be the case in some stations. As the next steps, it worth adding more elevators into the system and considering a multi agent RL system to do further optimisation.
References
[1] Xu Yuan Lucian Busoniu and Robert Babuska, Reinforcement Learning for Elevator Control, 2008. https://www.sciencedirect.com/science/article/pii/S1474667016392783
[2] Adam King, Create custom gym environments from scratch — A stock market example. https://towardsdatascience.com/creating-a-custom-openai-gym-environment-for-stock-trading-be532be3910e
[3] A Hands-On Introduction to Deep Q-Learning using OpenAI Gym in Python. https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
A non trivial elevator control system in a train station by reinforcement learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3lf4val
via RiYo Analytics








{kind=link}
No comments