https://ift.tt/3CTENy0 A Labelling Tool to Easily Extract and Label Wikipedia Data Build a training dataset from Wikipedia using DataQA ...
A Labelling Tool to Easily Extract and Label Wikipedia Data
Build a training dataset from Wikipedia using DataQA

Disclaimer: I am the developer of DataQA, a free and open-source tool for text exploration and labelling.
A very typical task of any data scientist is having to “enrich” some seed dataset by finding additional attributes related to it. Questions like these arise on a regular basis:
- Where are the headquarters of this list of 2000 companies?
- What are the main side effects of these 500 drugs?
- What are the main products launched by these 400 companies?
- Who are the main friends of this list of 1000 celebrities?
Ok… maybe not the last one.
With almost 6.5 million of articles (and counting), Wikipedia is one of the largest repositories of human knowledge in the world, and thus the first place most of us go to look for answers. Good news is that it’s online and (mostly) free to use, the bad news is that it’s made out of mainly unstructured documents and it would take an unreasonable amount of time to have to extract this information manually. The open-source tool DataQA has just recently launched a new feature that allows you to extract information from Wikipedia in a fast and efficient way. We will take you through the basic steps in this tutorial.
Upload your data
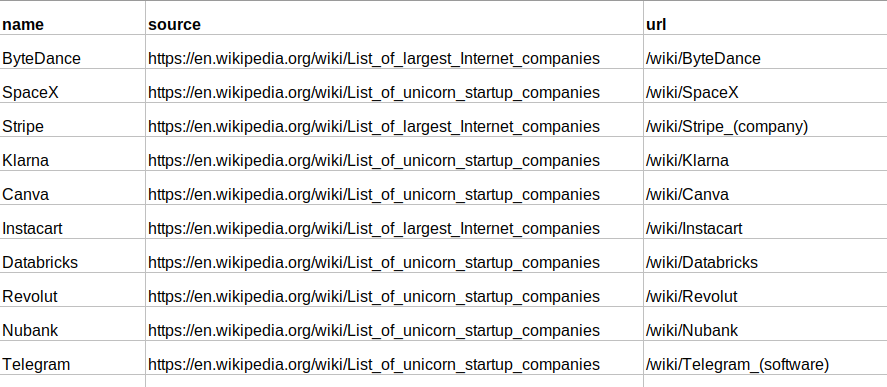
A prerequisite for this tutorial is to have a list of wikipedia urls (or subpaths) of the articles of interest. In this tutorial, we have a list of almost 400 companies, some of them private “unicorns” and others publicly listed, and we would like to extract all the names of the products launched by these companies. The input file needs to be a csv file.
Step 1: create a new project to extract entities from Wikipedia
Launch DataQA and create a new project. Instructions on how to install and launch DataQA can be found on the official documentation site. Installation is just a simple pip install command.
Step 2: Load the csv file with the page urls.
The next step is to load the file. DataQA only contacts the internet at startup, everything runs locally and none of your data ever leaves your computer.
The upload might take a few minutes depending on how many rows there are. A list of 400 urls takes about 10 minutes. DataQA extracts paragraphs and tables from Wikipedia and runs NLP pipelines on all the content. Each document in DataQA will only be a piece of the original article, a paragraph approximately. It is much easier to label a smaller chunk of text.
Step 3: Load the csv file with the entity names.
The next step is to upload a file with the names of the entities we would like to tag. In this example, there is only one type called “products” so our csv only has one line besides the column name.

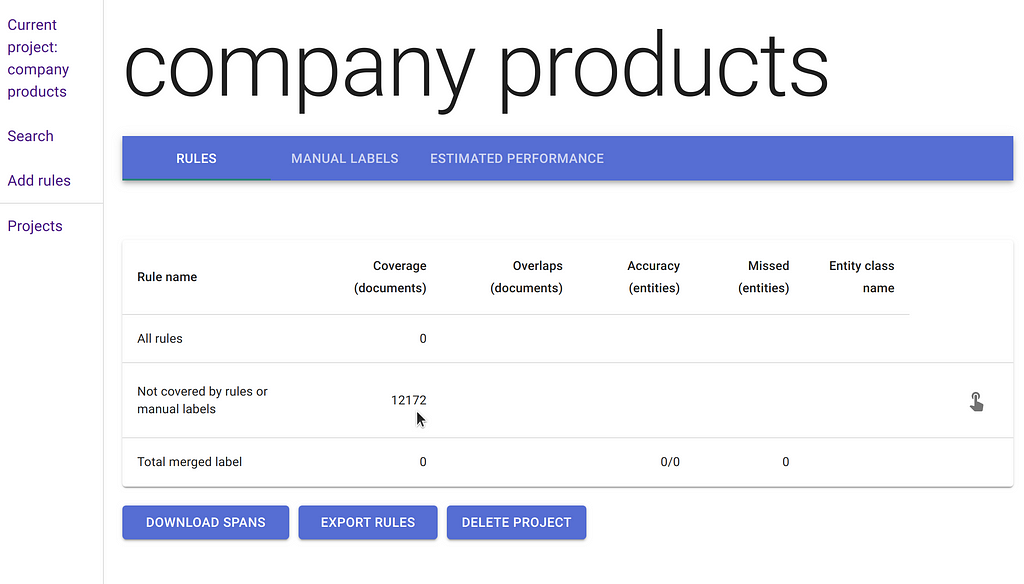
After this step is done, you land on the project’s summary table which contains information about the total number of documents processed.
In our case, even though the original file only had 400 wikipedia urls, the total number of final uploaded text “chunks” is slightly over 12,000.
Start labelling your documents
Once the data has been uploaded, you can click on “Search” on the left-hand side to start exploring the data extracted from Wikipedia.
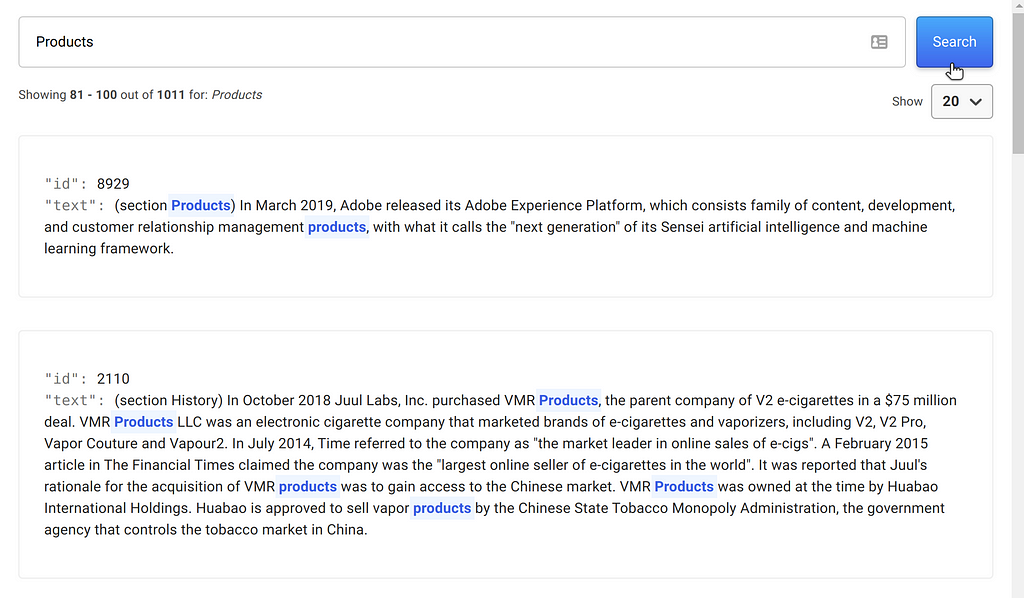
Labelling 12,000 documents by hand is not really a feasible task. Thankfully, DataQA offers some ways to narrow down on the documents that most likely contain the desired information. Every paragraph starts with the name of the page section, and we notice that it is very common to find a section named “Products” in these wikipedia pages. You can enter regular expressions to match specific documents or entities and automatically extract entities.
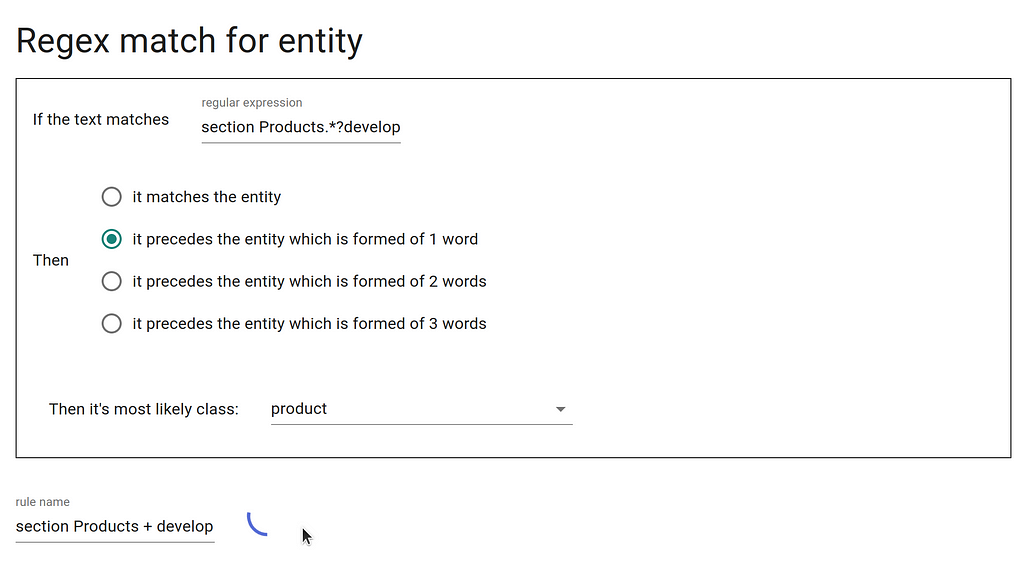
- We can create a rule that extracts entities that come after the regular expression section Products.*?develop,
- and also section Products.*?release.
Other rules that we can also use to narrow down the documents to label:
- Label any table with a column named “Products”.
- Get any paragraph with a sentence that has the word “develop” and a noun phrase containing upper case letters.
- Get any paragraph with a sentence that has the word “release” and a noun phrase containing upper case letters.
After adding these simple rules, our summary table looks like this:
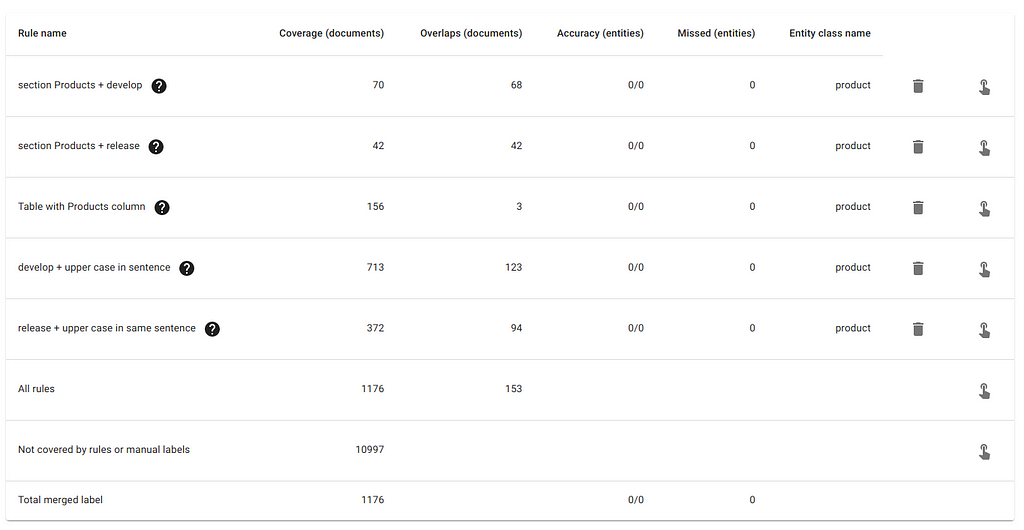
Now we’re ready to label these documents. Clicking on the hand icon on the same row as a rule will only show documents that have been selected by that rule.

Clicking on the hand icon above will take you to documents containing Wiki tables that have a column called “Products”. With DataQA, it’s possible to extract entities from both tables and paragraphs alike. In many cases, these tables will contain specific product names, which is what we would like to extract for this project.
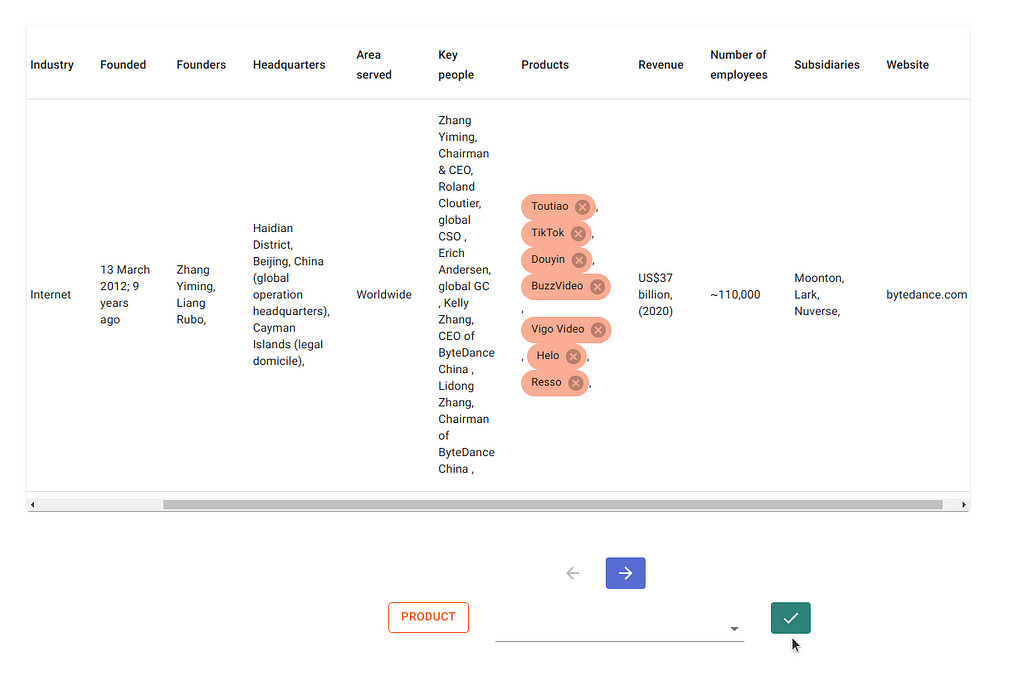
Only certain spans are valid entities. For example, it is not possible to label part of a word as an entity. The first time the check icon is clicked, the validity of the spans are verified. If happy, the second time it is clicked, these labels are confirmed and saved, and the next document is displayed.
Export the results as a csv
Once we’re happy with the amount of labels collected, we can export the labels as a csv file.
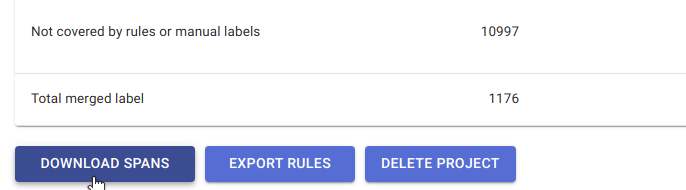
The output csv file will contain the following fields:
- row_id: index of the paragraph,
- url: original Wikipedia url,
- text: the document,
- is_table: True if the document is a Wiki table,
- manual_label: manually labelled spans,
- merged_label: all rule spans,
- [rule_name]: single rule spans.
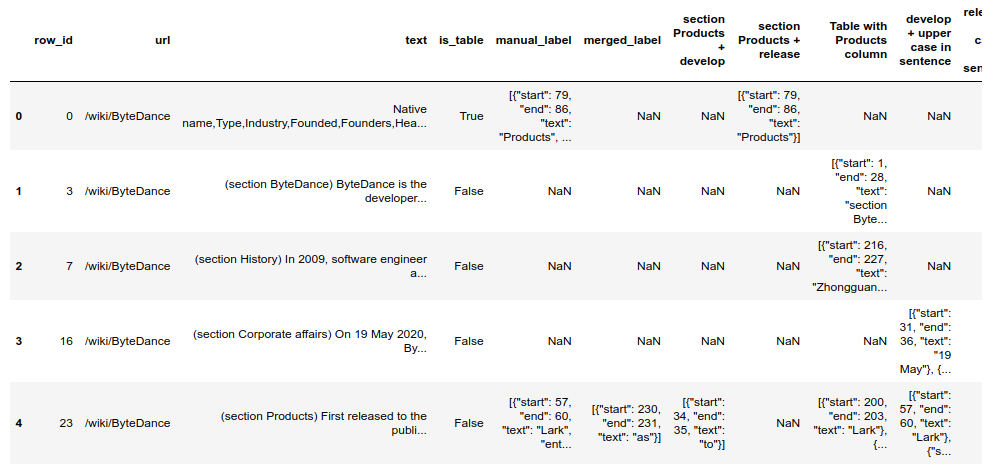
The manual_label column contains all the spans that have been manually labelled.

Whenever the paragraph is a table, the text is a csv-formatted version of that table, which can be loaded onto a pandas dataframe:

And that’s it for now!
In a future blog post, we will see how these labels can be used to train a NER model.
References
- Github repository: https://github.com/dataqa/dataqa
- Official documentation page: https://dataqa.ai/docs/latest
A labelling tool to easily extract and label Wikipedia data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3nU9Ju5
via RiYo Analytics








ليست هناك تعليقات