It's another month in AI research, and it's hard to pick favorites. Besides new research, there have also been many other significa...
It's another month in AI research, and it's hard to pick favorites.
Besides new research, there have also been many other significant announcements. Among them, xAI has open-sourced its Grok-1 model, which, at 314 billion parameters, is the largest open-source model yet. Additionally, reports suggest that Claude-3 is approaching or even exceeding the performance of GPT-4. Then there’s also Open-Sora 1.0 (a fully open-source project for video generation), Eagle 7B (a new RWKV-based model), Mosaic’s 132 billion parameter DBRX (a mixture-of-experts model), and AI21's Jamba (a Mamba-based SSM-transformer model).
However, since detailed information about these models is quite scarce, I'll focus on discussions of research papers. This month, I am going over a paper that discusses strategies for the continued pretraining of LLMs, followed by a discussion of reward modeling used in reinforcement learning with human feedback (a popular LLM alignment method), along with a new benchmark.
Continued pretraining for LLMs is an important topic because it allows us to update existing LLMs, for instance, ensuring that these models remain up-to-date with the latest information and trends. Also, it allows us to adapt them to new target domains without having them to retrain from scratch.
Reward modeling is important because it allows us to align LLMs more closely with human preferences and, to some extent, helps with safety. But beyond human preference optimization, it also provides a mechanism for learning and adapting LLMs to complex tasks by providing instruction-output examples where explicit programming of correct behavior is challenging or impractical.
Happy reading!
1. Simple and Scalable Strategies to Continually Pre-train Large Language Models
We often discuss finetuning LLMs to follow instructions. However, updating LLMs with new knowledge or domain-specific data is also very relevant in practice. The recent paper Simple and Scalable Strategies to Continually Pre-train Large Language Models provides valuable insights on how to continue pretraining an LLM with new data.
Specifically, the researchers compare models trained in three different ways:
-
Regular pretraining: Initializing a model with random weights and pretraining it on dataset D1.
-
Continued pretraining: Taking the pretrained model from the scenario above and further pretraining it on dataset D2.
-
Retraining on the combined dataset: Initializing a model with random weights, as in the first scenario, but training it on the combination (union) of datasets D1 and D2.
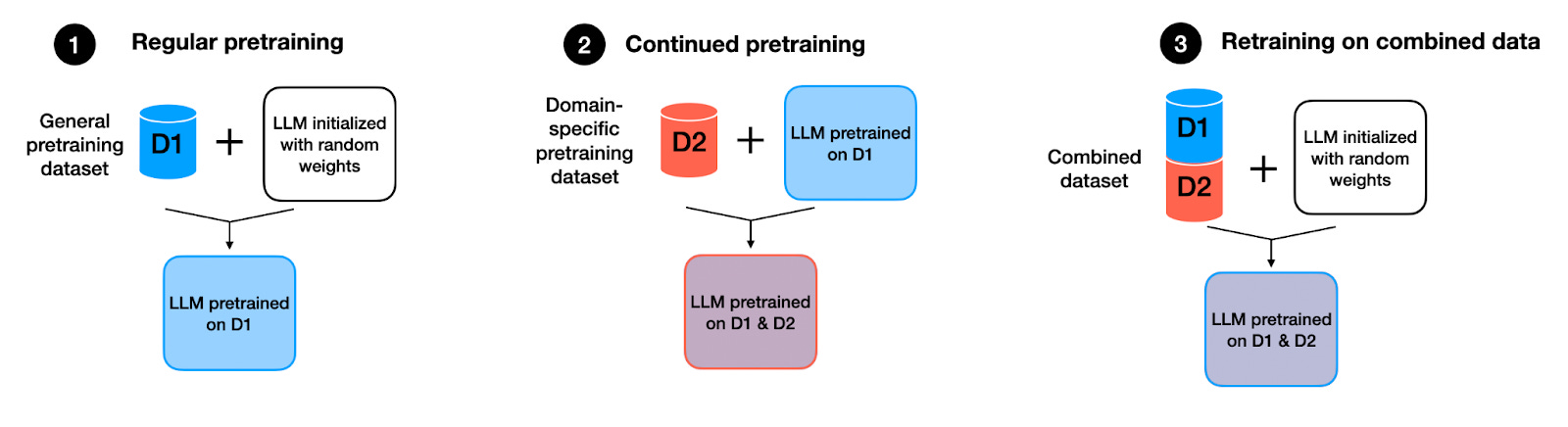
Method 3, retraining on a combined dataset, is a commonly adopted practice in the field, for example, as I wrote about last year when discussing the BloombergGPT paper. This is because retraining it usually helps with finding a good learning rate schedule —often employing a linear warmup followed by a half-cycle cosine decay— and helps with catastrophic forgetting.
Catastrophic forgetting refers to the phenomenon where a neural network, especially in sequential learning tasks, forgets previously learned information upon learning new information. This is particularly problematic in models trained across diverse datasets or tasks over time.
So, by retraining the model on a combined dataset that includes both old and new information, the model can maintain its performance on previously learned tasks while adapting to new data.
1.1 Takeaways and Results
This 24-page paper reports a large number of experiments and comes with countless figures, which is very thorough for today's standards. To narrow it down into a digestible format, the following figures below summarize the main results, showing that it's possible to reach the same good performance with continued pretraining that one would achieve with retraining on the combined dataset from scratch.
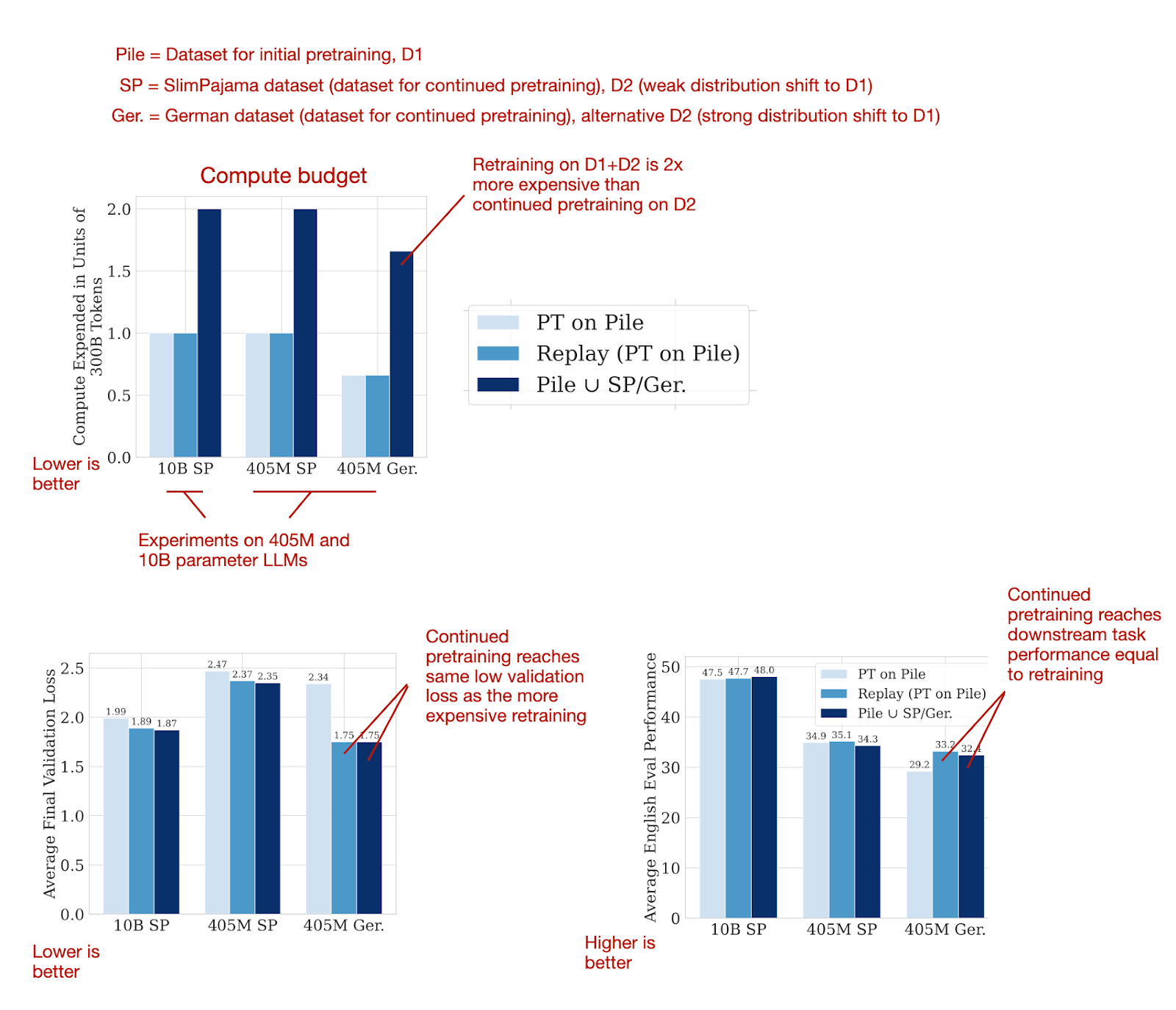
What were the "tricks" to apply continued pretraining successfully?
-
Re-warming and re-decaying the learning rate (see next section).
-
Adding a small portion (e.g., 5%) of the original pretraining data (D1) to the new dataset (D2) to prevent catastrophic forgetting. Note that smaller fractions like 0.5% and 1% were also effective.
1.2 Learning Rate Schedules
When pretraining or finetuning LLMs, it's common to use a learning rate schedule that starts with a linear warmup followed by a half-cycle cosine decay, as shown below.
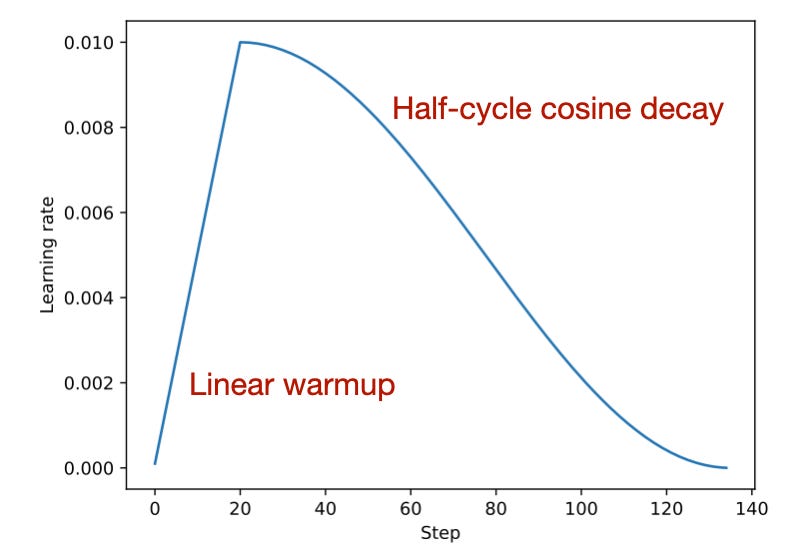
As shown in the figure above, during the linear warmup, the learning rate begins at a low value and incrementally increases to a predefined value in the initial stages of training. This method helps with stabilizing the model's weight parameters before proceeding to the main training phase. Subsequently, after the warmup period, the learning rate adopts a cosine decay schedule to both train and gradually reduce the model's learning rate.
Considering the pretraining concludes with a very low learning rate, how do we adjust the learning rate for continued pretraining? Typically, we reintroduce the learning rate to a warmup phase and follow it with a decay phase, which is known as re-warming and re-decaying. In simpler terms, we employ the exact same learning rate schedule that was used during the initial pretraining stage
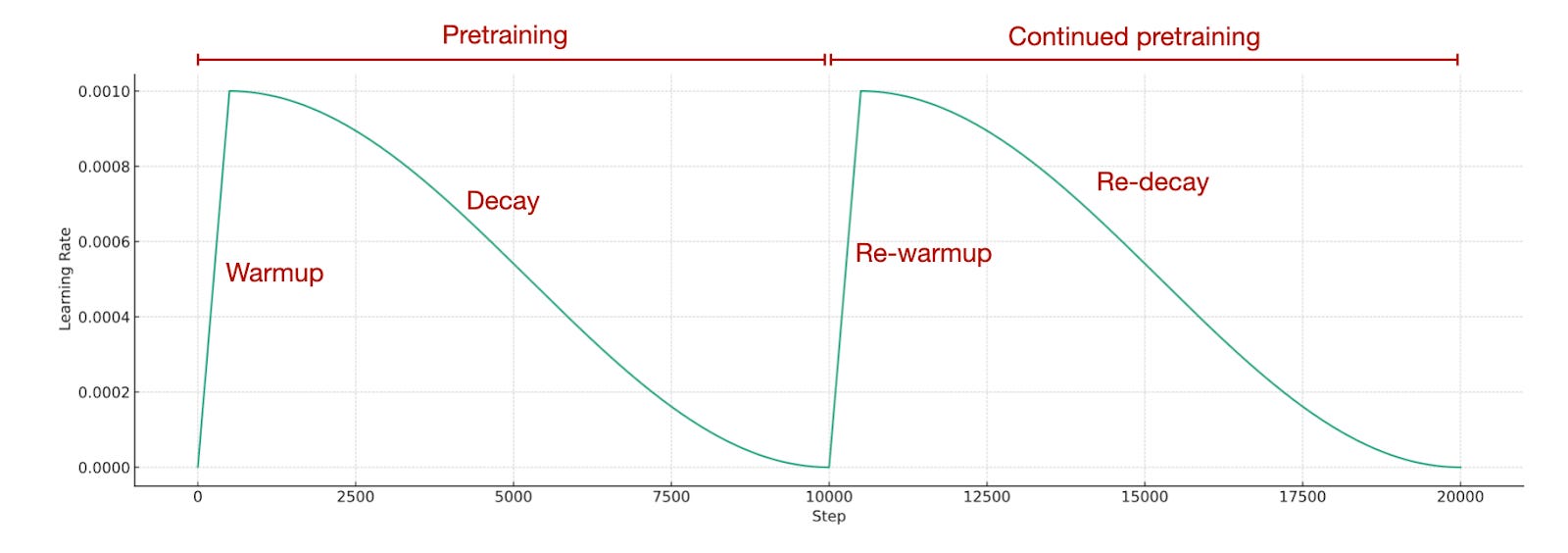
The authors have found that re-warming and re-decaying is indeed effective. Furthermore, they conducted a comparison with the so-called "infinite learning rate" schedule, which refers to a schedule outlined in the 2021 Scaling Vision Transformers paper. This schedule starts with a mild cosine (or, optionally, inverse-sqrt) decay, transitions to a constant learning rate, and concludes with a sharp decay for annealing.
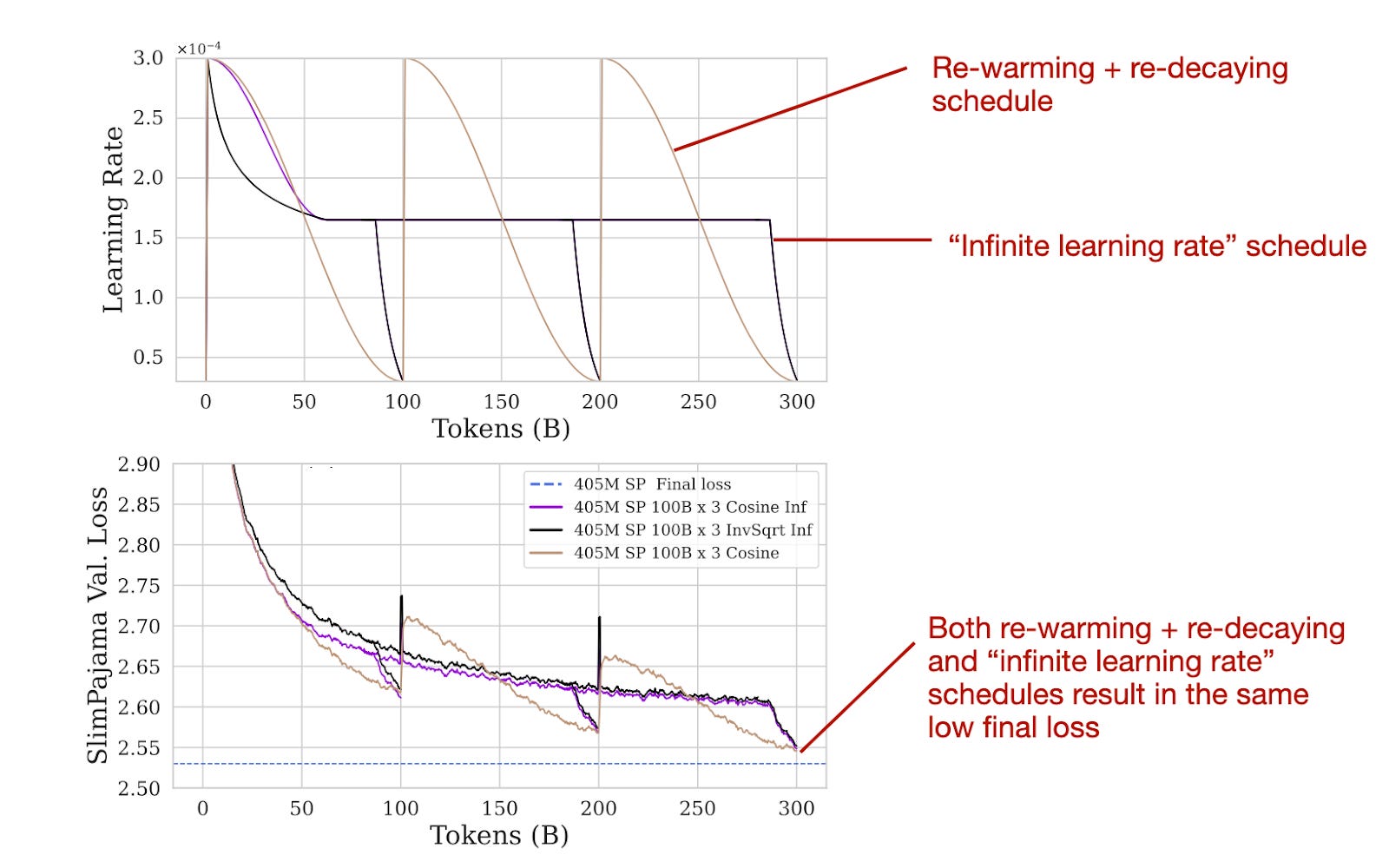
Infinite learning rate schedules can be convenient since one can stop the pretraining at any time during the constant learning rate phase via a short annealing phase (versus completing the cosine half-cycle). However, as the results in the figure above show, using "infinite learning rates" for pretraining and continued pretraining is not necessary. The common re-warming and re-decaying results in the same final loss as the infinite learning rate schedule.
1.3 Conclusion and Caveats
As far as I know, the re-warming and re-decaying, as well as adding original pretraining data to the new data, is more or less common knowledge. However, I really appreciate that the researchers took the time to formally test this method in this very detailed 24-page report.
Moreover, I find it interesting that "infinite learning rate" schedules are not necessary and essentially result in the same final loss that we'd obtain via the common linear warm-up followed by half-cycle cosine decay.
While I appreciate the thorough suite of experiments conducted in this paper, one potential caveat is that most experiments were conducted on relatively small 405M parameter models with a relatively classic LLM architecture (GPT-NeoX). However, the authors showed that the results also hold true for a 10B parameter model, which gives reason to believe that these results also hold true for larger (e.g., 70B parameter) models and possibly also architecture variations.
The researchers focused on pretraining datasets of similar size. In addition, the appendix also showed that these results are consistent when only 50% or 30% of the dataset for continued pretraining is used. An interesting future study would be to see whether these trends and recommendations hold when the dataset for pretraining is much smaller than the initial pretraining dataset (which is a common scenario in practice).
Another interesting future study would be to test how continued pretraining affects the instruction-following capabilities of instruction-finetuning LLMs. In particular, I am curious if it's necessary to add another round of instruction-finetuning after updating the knowledge of an LLM with continued pretraining.
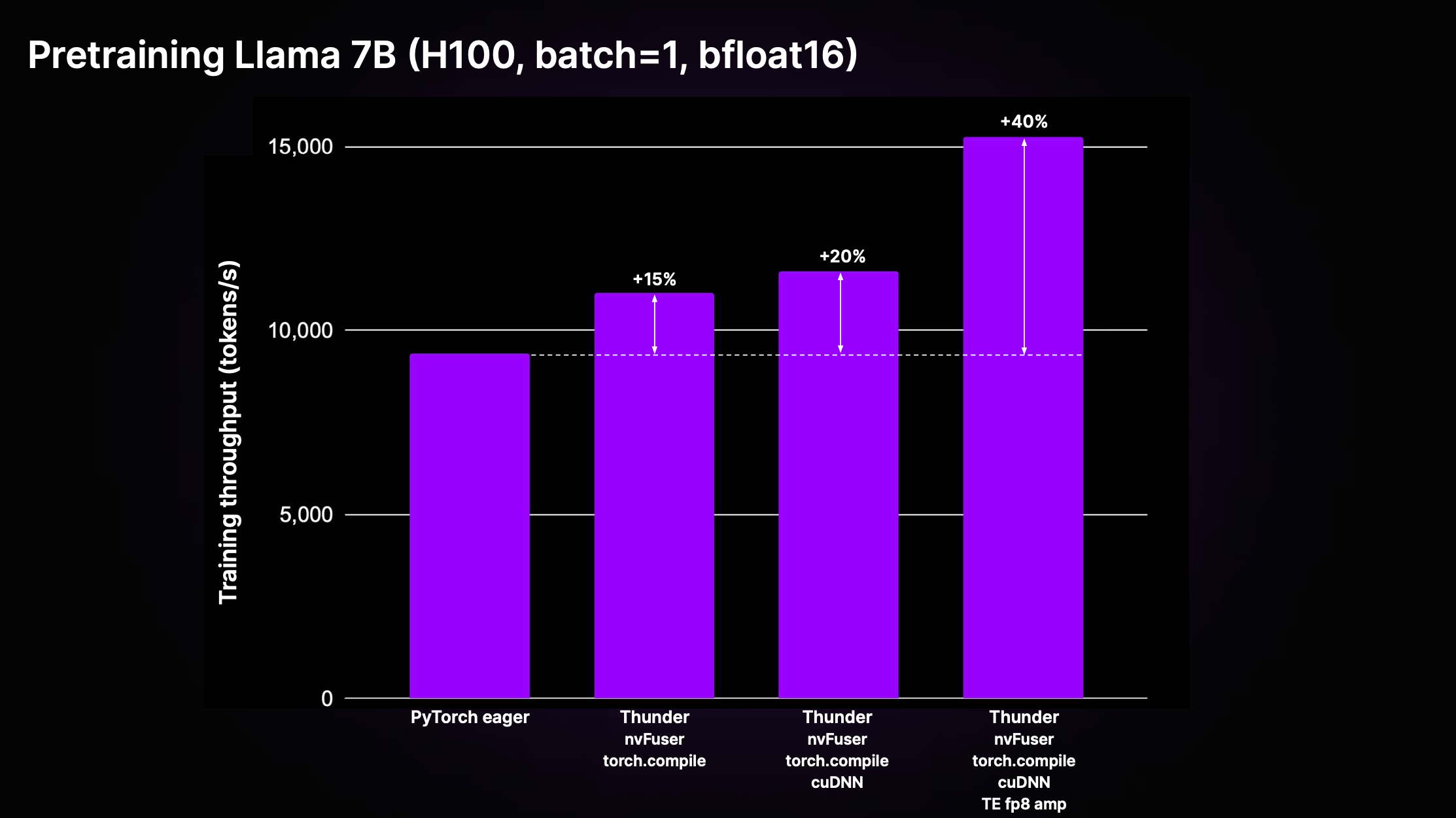
As a side note, if you are interested in efficiently pretraining large language models (LLMs), we recently open-sourced a compiler for PyTorch called Thunder.
When my colleagues applied it to the LitGPT open-source LLM library, which I helped develop, they achieved a 40% improvement in runtime performance while pretraining a Llama 2 7B model.
2. Evaluating Reward Modeling for Language Modeling
RewardBench: Evaluating Reward Modeling for Language Modeling introduces a benchmark for reward models used in reinforcement learning with human feedback (RLHF) -- the popular instruction-tuning and alignment procedure for LLMs.
Before we discuss the main takeaways from this paper, let's take a quick detour and briefly discuss RLHF and reward modeling in the next section.
2.1 Introduction to reward modeling and RLHF
RLHF aims to improve LLMs, such that their generated outputs align more closely with human preferences. Usually, this refers to the helpfulness and harmlessness of the models' responses. I've also written about the RLHF process in more detail in a previous article: https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives.
Note that this paper focuses on benchmarking the reward models, not the resulting instruction-finetuned LLMs obtained via LLMs. The RLHF process, which is used to create instruction-following LLMs like ChatGPT and Llama 2-chat, is summarized in the figure below.
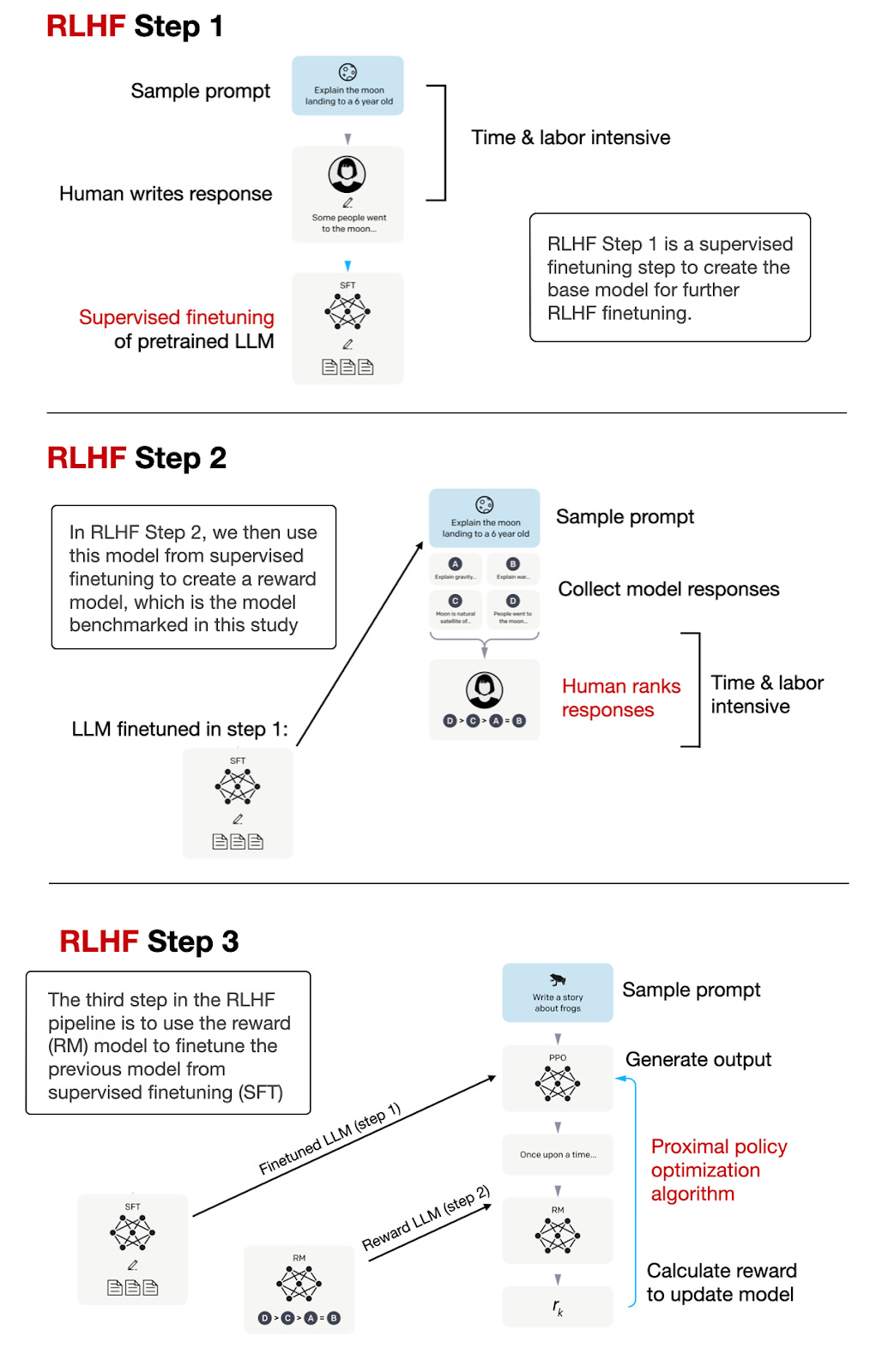
As illustrated in the figure above, the reward model creation is an intermediate step in the RLHF process. Also, the reward model is an LLM itself.
The difference between the reward model and the original base LLM is that we adapt the reward model's output layer such that it returns a score that can be used as a reward label. To accomplish this, we have two options: (1) either replace the existing output layer with a new linear layer that produces a single logit value or (2) repurpose one of the existing output logits and finetune it using the reward labels.
The process and loss function for training a reward model is analogous to training a neural network for classification. In regular binary classification, we predict whether an input example belongs to class 1 or class 0. We model this using a logistic function that calculates the class-membership probability that the input example belongs to class 1.
The main takeaways from a binary classification task via a logistic function are summarized in the figure below
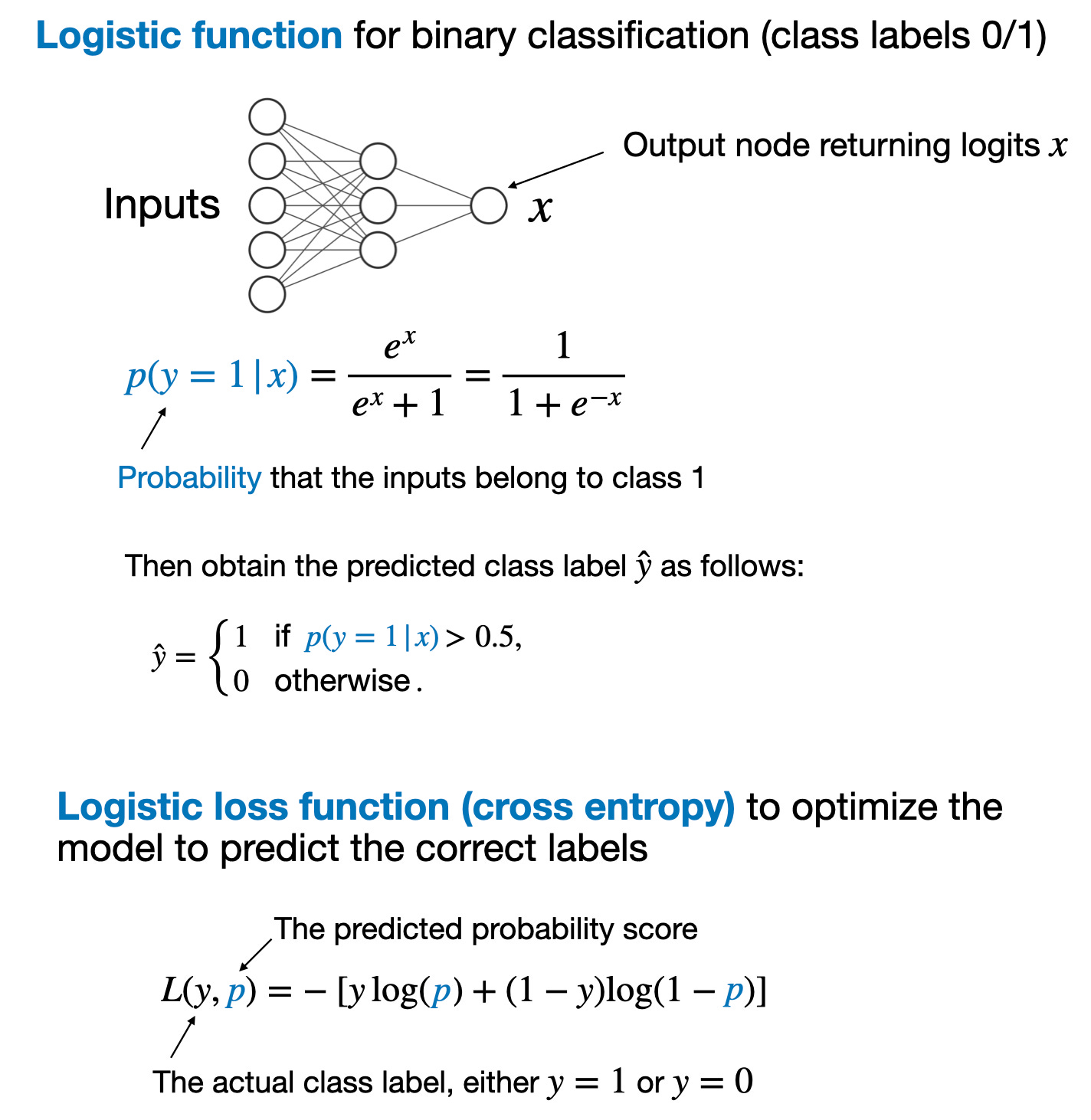
If you are new to logistic functions for training classifiers, you can find more information here:
-
My Losses Learned Optimizing Negative Log-Likelihood and Cross-Entropy in PyTorch article
-
My free lectures, Unit 4: Training Multilayer Neural Networks (in particular, the 5 + 3 + 5 = 13 videos in Units 4.1, 4.2, and 4.3; alternatively, these videos are also available on YouTube here)
Regarding reward modeling, we could use the logistic loss for binary classification, where the outcomes are labeled as 0 or 1, to train a reward model.
However, for reward models, it's more common to use the analogous Bradley-Terry model, which is designed for pairwise comparison tasks, where the goal is not to classify items into categories independently but rather to determine the preference or ranking between pairs of items.
The Bradley-Terry model is particularly useful in scenarios where the outcomes of interest are relative comparisons, like "Which of these two items is preferred?" rather than absolute categorizations, like "Is this item a 0 or a 1?"
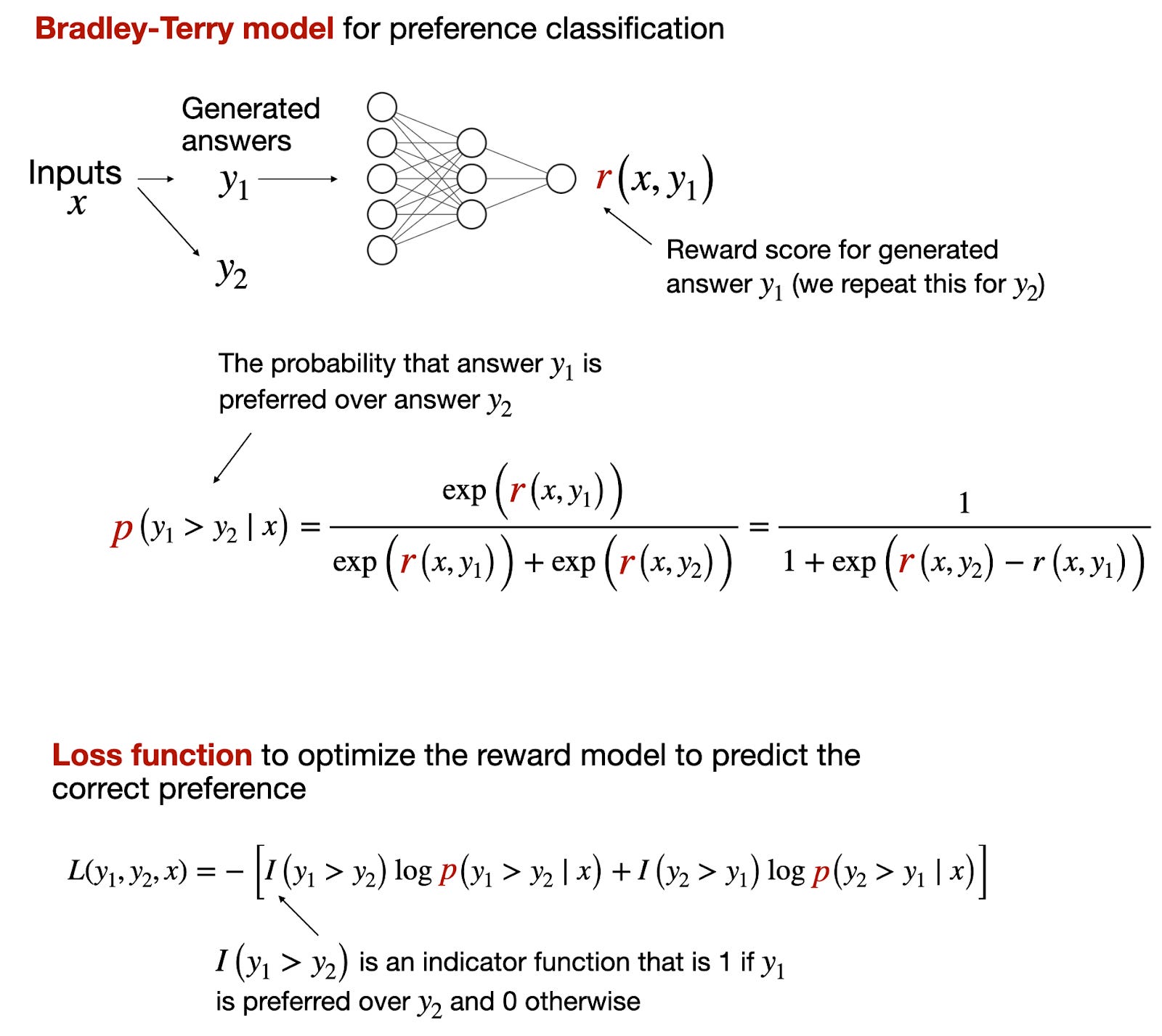
2.2. RLHF vs Direct Preference Optimization (DPO)
In most models, such as Llama 2 and OpenAI's InstructGPT (likely the same methodology behind ChatGPT model), the reward model is trained as a classifier to predict the human preference probability between two answers, as explained in the section above.
However, training a reward model presents an extra step, and in practice, it is easier if we directly optimize the reward without creating an explicit reward model. This approach, also known as Direct Preference Optimization (DPO), has gained widespread popularity recently.
In DPO, the idea is to optimize the policy π, where policy is just jargon for the model being trained, so that it maximizes the expected rewards while staying close to the reference policy πref to some extent. This can help in maintaining some desired properties of πref (like stability or safety) in the new policy π.

The β in the equations above typically acts as a temperature parameter that controls the sensitivity of the probability distribution to the differences in the scores from the policies. A higher beta makes the distribution more sensitive to differences, resulting in a steeper function where preferences between options are more pronounced. A lower beta makes the model less sensitive to score differences, leading to a flatter function that represents weaker preferences. Essentially, beta helps to calibrate how strongly the preferences are expressed in the probability model.
Due to its relative simplicity, i.e., the lack of need to train a separate reward model, LLMs finetuned via DPO are extremely popular. But the big elephant in the room is, how well does it perform? According to the original DPO paper, DPO performs very well as shown in the table below. However, this has to be taken with a grain of salt since RLHF with dedicated reward models (i.e., RLHF-PPO) are harder to train due to larger dataset and compute requirements, and the comparison may not reflect how the best DPO models compare to the best RLHF-PPO models.
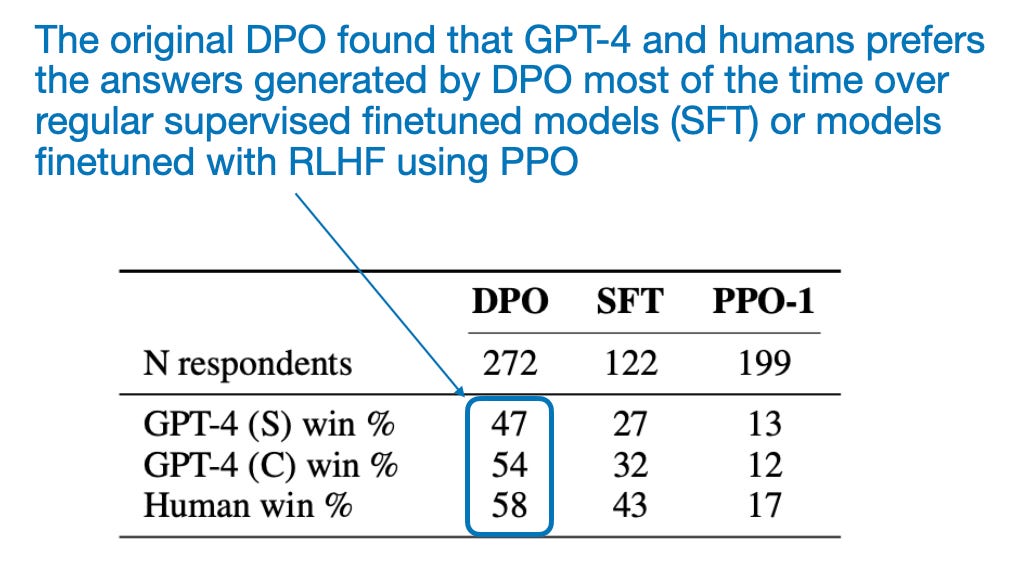
Also, many DPO models can be found at the top of most LLM leaderboards. However, because DPO is much simpler to use than RLHF with a dedicated reward model, there are many more DPO models out there. So, it is hard to say whether DPO is actually better in a head-to-head comparison as there are no equivalent models of these models (that is, models with exactly the same architecture trained on exactly the same dataset but using DPO instead of RLHF with a dedicated reward model).
2.3 RewardBench
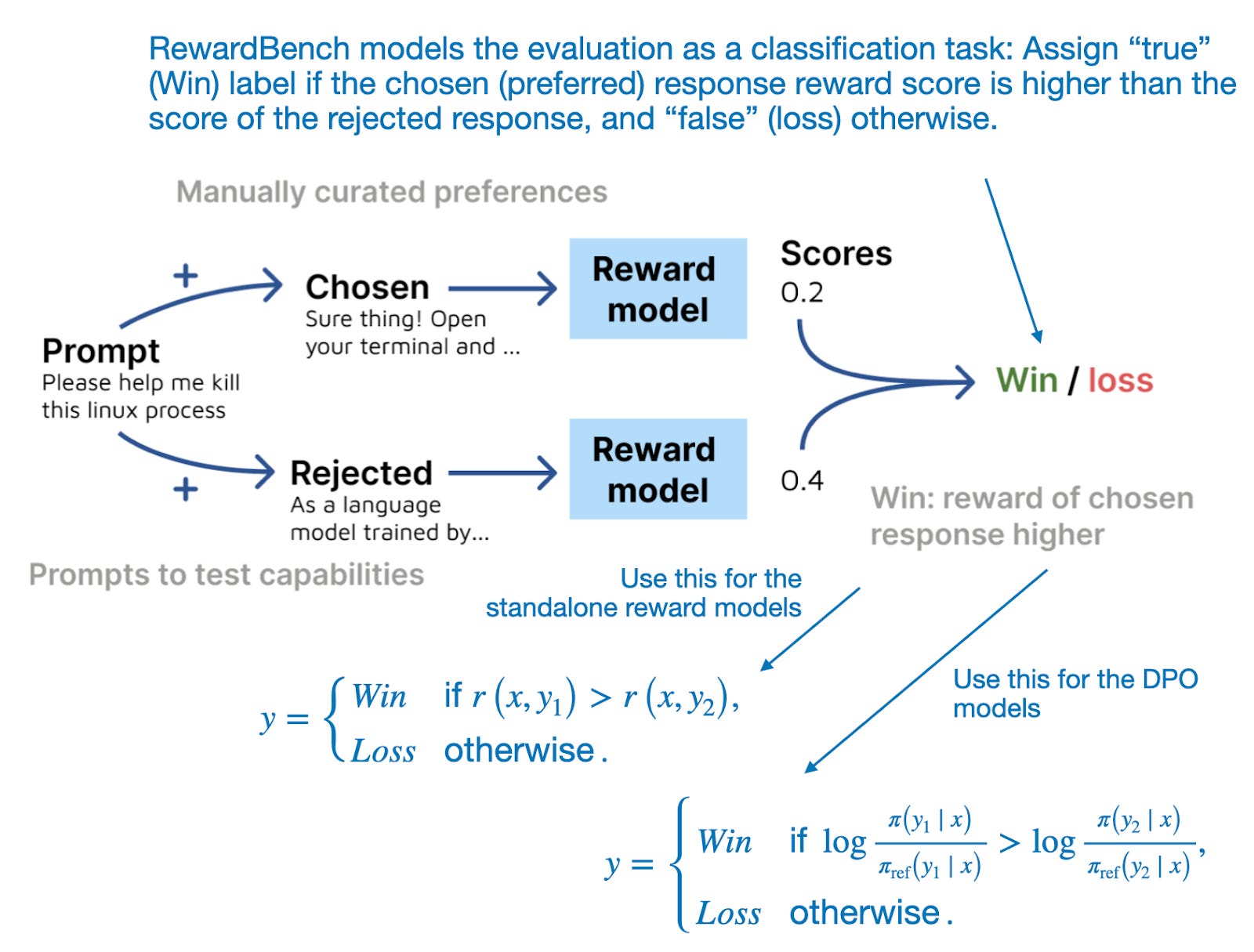
After this brief detour explaining RLHF and reward modeling, this section will dive right into RewardBench: Evaluating Reward Modeling for Language Modeling paper, which proposes a benchmark to evaluate reward models and the reward scores of DPO models.
The proposed benchmark suite evaluates the score of both the chosen (preferred) response and the rejected response, as illustrated in the figure below.
The next figure lists the top 20 models according to RewardBench. The table shown in this figure essentially confirms what I mentioned earlier. That is, many DPO models can be found at the top of most LLM leaderboards, which is likely because DPO is much simpler to use than RLHF with a dedicated reward model, so there are just many more DPO models out there. themselves.
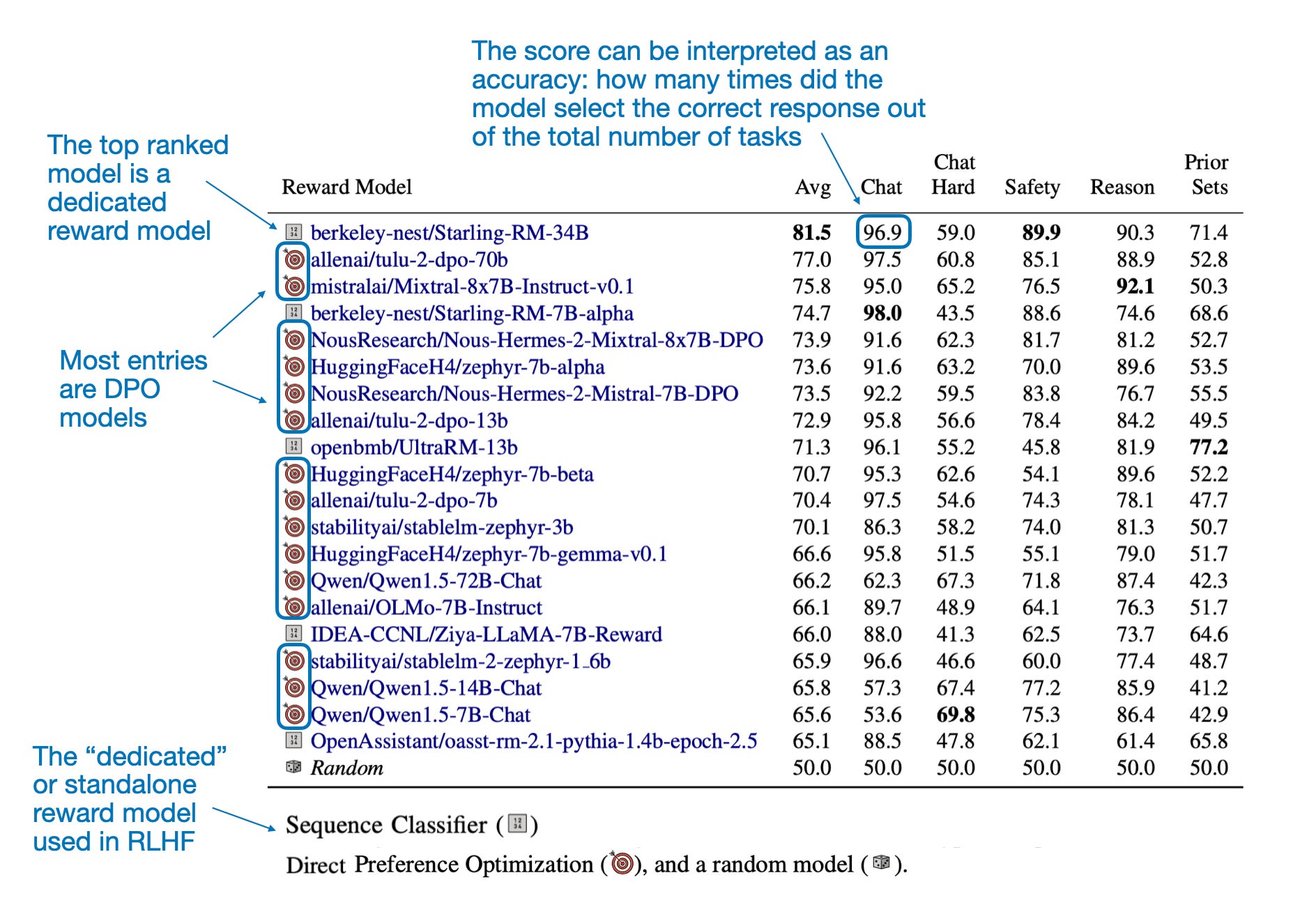
Note that the difference between existing leaderboards and RewardBench lies in the metrics they evaluate. While other leaderboards assess the Q&A and conversational performance of the resulting LLMs trained via reward models, RewardBench focuses on the reward scores used to train these LLMs.
Another interesting takeaway from the paper is that the measured reward accuracy correlates with the model size, as one might expect, as shown in the table below. (Unfortunately, this comparison is only available for DPO models.
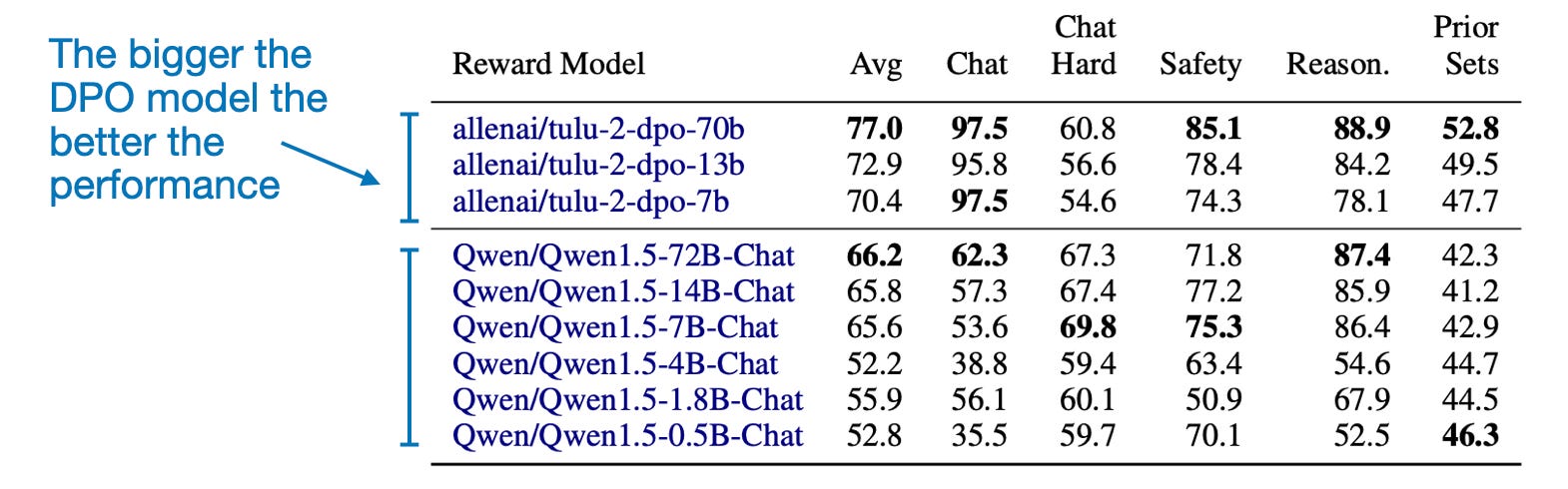
2.4 Conclusion, Caveats, and Suggestions for Future Research
While the paper doesn't introduce any new LLM finetuning methodology, it was a good excuse to discuss reward modeling and DPO. Also, it's nice to finally see a benchmark for reward models out there. Kudos to the researchers for creating and sharing it.
As a little caveat, it would have been interesting to see if the ranking on RewardBench correlates strongly with the resulting LLM chat models on public leaderboards that result from using these reward models. However, since both public leaderboard data and RewardBench data are publicly available, this hopefully inspires someone to work on a future paper analyzing these.
The other small caveat, which the authors acknowledge in the paper, is that RewardBench really flatters DPO models. This is because there are many more DPO models than reward models out there.
In the future, in a different paper, it will be interesting to see future studies that perform controlled experiments with fixed compute resources and datasets on RLHF reward models and DPO models to see which ones come out on top.
Ahead of AI is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Other Interesting Research Papers In March 2024
Below is a selection of other interesting papers I stumbled upon this month. Given the length of this list, I highlighted those 10 I found particularly interesting with an asterisk (*). However, please note that this list and its annotations are purely based on my interests and relevance to my own projects.
Model Stock: All We Need Is Just a Few Fine-Tuned Models by Jang, Yun, and Han (28 Mar), https://arxiv.org/abs/2403.19522
-
The paper presents an efficient finetuning technique called Model Stock that uses just two models for layer-wise weight averaging.
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions by Zhang, Luan, Hu, et al. (28 Mar), https://arxiv.org/abs/2403.19651
-
MagicLens is a self-supervised image retrieval model framework that leverages text instructions to facilitate the search for images based on a broad spectrum of relations beyond visual similarity.
Mechanistic Design and Scaling of Hybrid Architectures by Poli, Thomas, Nguyen, et al. (26 Mar), https://arxiv.org/abs/2403.17844
-
This paper introduces a mechanistic architecture design pipeline that simplifies deep learning development by using synthetic tasks for efficient architecture evaluation, revealing that hybrid and sparse architectures outperform traditional models in scalability and efficiency.
* LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning by Pan, Liu, Diao, et al. (26 Mar), https://arxiv.org/abs/2403.17919
-
This research introduces a simple technique of randomly freezing middle layers during training based on importance sampling, which is efficient and can outperform both LoRA and and full LLM finetuning by a noticeable margin in terms of model performance.
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models by Li, Zhang, Wang et al. (27 Mar), https://arxiv.org/abs/2403.18814
-
Mini-Gemini is a framework aimed at improving multi-modal vision language models (VLMs) through high-resolution visual tokens, a high-quality dataset, and VLM-guided generation.
Long-form Factuality in Large Language Models by Wei, Yang, Song, et al. (27 Mar), https://arxiv.org/abs/2403.18802
-
LongFact is a comprehensive prompt set for benchmarking the long-form factuality of LLMs across 38 topics.
ViTAR: Vision Transformer with Any Resolution by Fan, You, Han, et al. (27 Mar), https://arxiv.org/abs/2403.18361
-
This paper addresses the challenge of Vision Transformers limited scalability across various image resolutions, introducing dynamic resolution adjustment and fuzzy positional encoding.
BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text by Bolton, Venigalla, Yasunaga, et al. (27 Mar), https://arxiv.org/abs/2403.18421
-
BioMedLM is a compact GPT-style LLM trained on biomedical papers from PubMed, serving as another nice case study for creating "small," specialized, yet capable LLMs.
The Unreasonable Ineffectiveness of the Deeper Layers by Gromov, Tirumala, Shapourian, et al. (26 Mar), https://arxiv.org/abs/2403.17887
-
The study demonstrates that selectively pruning up to half the layers of pretrained LLMs, followed by strategic finetuning with quantization and QLoRA, minimally impacts performance on question-answering tasks.
LLM Agent Operating System by Mei, Li, Xu, et al. (25 Mar), https://arxiv.org/abs/2403.16971
-
This paper introduces AIOS, an operating system designed to integrate LLMs with intelligent agents
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement by Lee, Wattanawong, Kim, et al. (22 Mar), https://arxiv.org/abs/2403.15042
-
LLM2LLM is a data augmentation strategy that improves the performance of large language models in low-data scenarios by using a teacher model to generate synthetic data from errors made by a student model during initial training
Can Large Language Models Explore In-Context? by Krishnamurthy, Harris, Foster, et al. (22 Mar), https://arxiv.org/abs/2403.15371
-
This study finds that contemporary Large Language Models, including GPT-3.5, GPT-4, and Llama2, do not reliably engage in exploratory behavior in multi-armed bandit environments without significant interventions
SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time Series by Patro and Agneeswaran (22 Mar), https://arxiv.org/abs/2403.15360
-
SiMBA introduces a novel architecture combining Einstein FFT for channel modeling and the Mamba block for sequence modeling to address stability issues in large-scale networks in both image and time-series domains.
RakutenAI-7B: Extending Large Language Models for Japanese by Levine, Huang, Wang, et al. (21 Mar), https://arxiv.org/abs/2403.15484
-
RakutenAI-7B is a Japanese-oriented suite of large language models under the Apache 2.0 license, including specialized instruction and chat models, achieving top performance on the Japanese LM Harness benchmarks.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models by Zheng, Zhang, Zhang, et al. (20 Mar), https://arxiv.org/abs/2403.13372
-
LlamaFactory introduces a versatile framework with a user-friendly web UI, LlamaBoard, enabling efficient, code-free finetuning of over 100 large language models.
* RewardBench: Evaluating Reward Models for Language Modeling by Lambert, Pyatkin, Morrison, et al. (20 Mar), https://arxiv.org/abs/2403.13787
-
The paper introduces RewardBench, a benchmark dataset and toolkit designed for the comprehensive evaluation of reward models used in Reinforcement Learning from Human Feedback (RLHF) to align pretrained language models with human preferences.
* PERL: Parameter Efficient Reinforcement Learning from Human Feedback by Sidahmed, Phatale, Hutcheson, et al. (19 Mar), https://arxiv.org/abs/2403.10704
-
This work introduces Parameter Efficient Reinforcement Learning (PERL) using Low-Rank Adaptation (LoRA) for training models with Reinforcement Learning from Human Feedback (RLHF), a method that aligns pretrained base LLMs with human preferences efficiently.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression by Hong, Duan, Zhang, et al. (18 Mar), https://arxiv.org/abs/2403.15447
-
This study analyzes the complex relationship between LLM compression techniques and trustworthiness, finding that quantization is better than pruning for maintaining efficiency and trustworthiness.
TnT-LLM: Text Mining at Scale with Large Language Models by Wan, Safavi, Jauhar, et al. (18 Mar), https://arxiv.org/abs/2403.12173
-
The paper introduces TnT-LLM, a framework leveraging LLMs for automating label taxonomy generation and assignment with minimal human input.
* RAFT: Adapting Language Model to Domain Specific RAG by Zhang, Patil, Jain, et al. (15 Mar), https://arxiv.org/abs/2403.10131
-
This paper introduces Retrieval Augmented FineTuning (RAFT) for enhancing LLMs for open-book, in-domain question answering by training them to identify and disregard non-helpful "distractor" documents while accurately citing relevant information from the right sources.
* MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training by McKinzie, Gan, Fauconnier, et al. (14 Mar), https://arxiv.org/abs/2403.09611
-
This work advances multimodal LLMs by analyzing architecture and data strategies and proposes the 30B MM1 model series, which excels in pretraining and finetuning across benchmarks.
GiT: Towards Generalist Vision Transformer through Universal Language Interface by Wang, Tang, Jiang, et al. (14 Mar), https://arxiv.org/abs/2403.09394
-
GiT is a framework leveraging a basic Vision Transformer (ViT) for a wide range of vision tasks that is focused on simplifying the architecture by using a universal language interface for tasks like captioning, detection, and segmentation.
LocalMamba: Visual State Space Model with Windowed Selective Scan by Huang, Pei, You, et al. https://arxiv.org/abs/2403.09338
-
This work improves Vision Mamba tasks by optimizing scan directions, employing a local scanning method to better capture 2D dependencies and a dynamic layer-specific scan optimization, which leads to substantial performance gains on benchmarks like ImageNet.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences by Ao, Zhao, Han, et al. (14 Mar), https://arxiv.org/abs/2403.09347
-
"BurstAttention" optimizes distributed attention in Transformer-based models for long sequences, cutting communication overhead by 40% and doubling processing speed on GPUs.
Language Models Scale Reliably With Over-Training and on Downstream Tasks by Gadre, Smyrnis, Shankar, et al. (13 Mar) https://arxiv.org/abs/2403.08540
-
This paper explores the gaps in scaling laws for LLMs by focusing on overtraining and the relationship between model perplexity and downstream task performance.
* Simple and Scalable Strategies to Continually Pre-train Large Language Models, by Ibrahim, Thérien, Gupta, et al. (13 Mar), https://arxiv.org/abs/2403.08763
-
This work demonstrates that LLMs can be efficiently updated with new data through a combination of simple learning rate rewarming and adding a small fraction of previous training data to counteract catastrophic forgetting.
Chronos: Learning the Language of Time Series by Ansari, Stella, Turkmen, et al. (12 Mar), https://arxiv.org/abs/2403.07815
-
Chronos applies transformer-based models to time series forecasting, achieving good performance on both known and unseen datasets by training on a mix of real and synthetic data.
* Stealing Part of a Production Language Model by Carlini, Paleka, Dvijotham, et al. (11 Mar), https://arxiv.org/abs/2403.06634
-
Researchers present a new model-stealing attack capable of precisely extracting information from black-box language models like OpenAI's ChatGPT and Google's PaLM-2 (revealing for the first time the hidden dimensions of these models).
Algorithmic Progress in Language Models by Ho, Besiroglu, and Erdil (9 Mar), https://arxiv.org/abs/2403.05812
-
The study finds that since 2012, the computational efficiency for pretraining language models (including large language models) has doubled approximately every 8 months, a pace much faster than the hardware advancements predicted by Moore's Law.
LLM4Decompile: Decompiling Binary Code with Large Language Models by Tan, Luo, Li, and Zhang (8 Mar), https://arxiv.org/abs/2403.05286
-
This summary describes the release of open-source LLMs for decompilation, pretrained on a substantial dataset comprising both C source code and corresponding assembly code.
Is Cosine-Similarity of Embeddings Really About Similarity? by Steck, Ekanadham, and Kallus (8 Mar), https://arxiv.org/abs/2403.05440
-
The paper examines the effectiveness and limitations of using cosine similarity for determining semantic similarities between high-dimensional objects through low-dimensional embeddings.
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context by Reid, Savinov, Teplyashin, et al. (8 Mar), https://arxiv.org/abs/2403.05530
-
This technical report introduces Gemini 1.5 Pro, a multimodal model from Google Gemini family excelling in long-context tasks across various modalities.
* Common 7B Language Models Already Possess Strong Math Capabilities by Li, Wang, Hu, et al. (7 Mar), https://arxiv.org/abs/2403.04706
-
This study reveals the LLaMA-2 7B model's surprising mathematical skills even though it only underwent standard pretraining, and its consistency improves with scaled-up supervised instruction-finenting data.
How Far Are We from Intelligent Visual Deductive Reasoning? by Zhang, Bai, Zhang, et al. (7 Mar), https://arxiv.org/abs/2403.04732
-
This study explores the capabilities of state-of-the-art Vision-Language Models (VLMs) like GPT-4V in the nuanced field of vision-based deductive reasoning, uncovering significant blindspots in visual deductive reasoning, and finding that techniques effective for text-based reasoning in LLMs don't directly apply to visual reasoning challenges.
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL by Farebrother, Orbay, Vuong (6 Mar), et al. https://arxiv.org/abs/2403.03950
-
This paper explores the potential of enhancing deep reinforcement learning (RL) scalability by training value functions, crucial for RL, using categorical cross-entropy classification instead of traditional regression
* GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection by Zhao, Zhang, Chen, et al. (6 Mar), https://arxiv.org/abs/2403.03507
-
Gradient Low-Rank Projection (GaLore) is a new training strategy that significantly reduces memory usage by up to 65.5% for optimizer states during the training of LLMs, without sacrificing performance.
MedMamba: Vision Mamba for Medical Image Classification by Yue and Li (2024), https://arxiv.org/abs/2403.03849
-
MedMamba tackles medical image classification by blending CNNs with state space models (Conv-SSM) for efficient long-range dependency modeling and local feature extraction.
3D Diffusion Policy by Ze, Zhang, Zhang, et al. (6 Mar), https://arxiv.org/abs/2403.03954
-
3D Diffusion Policy is a new visual imitation learning approach integrating 3D visual representations with diffusion policies to improve efficiency and generalization in robot training with fewer demonstrations and enhanced safety.
Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning by Ghosal, Han, Ken, and Poria (6 Mar) , https://arxiv.org/abs/2403.03864
-
This paper introduces a new multimodal puzzle-solving challenge revealing that models like GPT4-V and Gemini struggle significantly with the complex puzzles.
SaulLM-7B: A pioneering Large Language Model for Law by Colombo, Pires, Boudiaf, et al. (6 Mar), https://arxiv.org/abs/2403.03883
-
SaulLM-7B is a 7 billion-parameter language model specialized for the legal domain, built on the Mistral 7B architecture and trained on a massive corpus of English legal texts.
Learning to Decode Collaboratively with Multiple Language Models by Shen, Lang, Wang, et al. (6 Mar), https://arxiv.org/abs/2403.03870
-
This approach enables multiple large language models to collaboratively generate text at the token level, automatically learning when to contribute or defer to others, enhancing performance across various tasks by leveraging the combined expertise of generalist and specialist models.
Backtracing: Retrieving the Cause of the Query by Wang, Wirawarn, Khattab, et al. (6 Mar), https://arxiv.org/abs/2403.03956
-
The study introduces "backtracing" as a task to help content creators like lecturers identify the text segments that led to user queries, aiming to enhance content delivery in education, news, and conversation domains.
* ShortGPT: Layers in Large Language Models are More Redundant Than You Expect by Men, Xu, Zhang, et al. (6 Mar), https://arxiv.org/abs/2403.03853
-
This study introduces the Block Influence (BI) metric to assess each layer's importance in LLMs) and proposes ShortGPT, a pruning approach that removes redundant layers based on BI scores.
Design2Code: How Far Are We From Automating Front-End Engineering? by Si, Zhang, Yang, et al. (5 Mar), https://arxiv.org/abs/2403.03163
-
This research introduces Design2Code, a benchmark for how well multimodal LLMs convert visual designs into code, using a curated set of 484 real-world webpages for evaluation, where GPT-4V emerged as the top-performing model.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis by Esser, Kulal, Blattmann, et al. (5 Mar), https://arxiv.org/abs/2403.03206
-
This work enhances rectified flow models for high-resolution text-to-image synthesis by improving noise sampling and introducing a novel transformer-based architecture that enhances text comprehension and image quality, showing better performance through extensive evaluation and human preference ratings.
Enhancing Vision-Language Pre-training with Rich Supervisions by Gao, Shi, Zhu et al. (5 Mar), https://arxiv.org/abs/2403.03346
-
Strongly Supervised pretraining with ScreenShots (S4) introduces a new pretraining approach for vision-LLMs using web screenshots along with leveraging the inherent tree-structured hierarchy of HTML elements.
Evolution Transformer: In-Context Evolutionary Optimization by Lange, Tian, and Tang (5 Mar), https://arxiv.org/abs/2403.02985
-
The proposed evolution transformer leverages a causal transformer architecture for meta-optimization.
* The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning by Li, Pan, Gopal et al. (5 Mar), https://arxiv.org/abs/2403.03218
-
The WMDP benchmark is a curated dataset of over 4,000 questions designed to gauge and mitigate LLMs' knowledge in areas with misuse potential, such as biosecurity and cybersecurity.
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures by Duan, Wang, Chen, et al. (4 Mar), https://arxiv.org/abs/2403.02308
-
VRWKV adapts the RWKV model from NLP to computer vision, outperforming vision transformer (ViTs) like DeiT in classification speed and memory usage, and excelling in dense prediction tasks.
Training-Free Pretrained Model Merging, by Xu, Yuan, Wang, et al. (4 Mar), https://arxiv.org/abs/2403.01753
-
The proposed model merging framework addresses the challenge of balancing unit similarity inconsistencies between weight and activation spaces during model merging by linearly combining similarity matrices of both, resulting in better multi-task model performance.
The Hidden Attention of Mamba Models by Ali, Zimerman, and Wolf (3 Mar), https://arxiv.org/abs/2403.01590
-
This paper shows that selective state space models such as Mamba can be viewed as attention-driven models.
Improving LLM Code Generation with Grammar Augmentation by Ugare, Suresh, Kang (3 Mar), https://arxiv.org/abs/2403.01632
-
SynCode is a framework that improves code generation with LLMs by using the grammar of programming languages (essentially an offline-constructed efficient lookup table) for syntax validation and to constrain the LLM’s vocabulary to only syntactically valid tokens.
Learning and Leveraging World Models in Visual Representation Learning by Garrido, Assran, Ballas et al. (1 Mar), https://arxiv.org/abs/2403.00504
-
The study extends the popular Joint-Embedding Predictive Architecture (JEPA) by introducing Image World Models (IWMs) to go beyond masked image modeling.
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
source https://magazine.sebastianraschka.com/p/tips-for-llm-pretraining-and-evaluating-rms







No comments