This month, I want to focus on three papers that address three distinct problem categories of Large Language Models (LLMs): Reducing hall...
This month, I want to focus on three papers that address three distinct problem categories of Large Language Models (LLMs):
-
Reducing hallucinations.
-
Enhancing the reasoning capabilities of small, openly available models.
-
Deepening our understanding of, and potentially simplifying, the transformer architecture.
Reducing hallucinations is important because, while LLMs like GPT-4 are widely used for knowledge generation, they can still produce plausible yet inaccurate information.
Improving the reasoning capabilities of smaller models is also important. Right now, ChatGPT & GPT-4 (vs. private or personal LLMs) are still our go-to when it comes to many tasks. Enhancing the reasoning abilities of these smaller models is one way to close the gap between open-source and current-gen proprietary LLMs.
Lastly, enhancing our understanding of the transformer architecture is fundamental for grasping the training dynamics of LLMs. This knowledge could lead to simpler, more efficient models, boosting the performance of open-source models and potentially paving the way for new architectural innovations.
1) Fine-tuning Language Models for Factuality
Language Models (LLMs) often suffer from hallucinations, meaning they generate convincing yet factually inaccurate information. This is particularly problematic when using LLMs for knowledge-based question answering, as it necessitates manual fact-checking of the responses. This process can be time-consuming and may defeat the purpose of using an LLM for some queries.
In the paper Fine-tuning Language Models for Factuality, the authors suggest finetuning methods using Direct Preference Optimization (DPO) to reduce the rate of hallucinations. By fine-tuning a 7B Llama 2 model using this approach, they achieved a 58% reduction in the factual error rate compared to the original Llama-2-chat model.

About Hallucinations
This is not explicitly discussed in the paper. However, before delving into the paper's discussion, it is worth considering the training and inference mechanisms in LLMs, which present two challenges. During pretraining, there may be datasets of poor quality that can lead the LLM to absorb factually incorrect information.
Secondly, during inference, we utilize a temperature setting and sampling method that allow the LLM to vary its sentence structure, ensuring it doesn't always generate identical text. This approach prevents the model from simply acting as a database lookup. However, there is no mechanism to guarantee which tokens should be sampled or taken directly from the training set.
For instance, in response to a query like "Who invented the iPhone and when was it first released?", possible responses include the following:

The LLM may vary the sentence structure and phrasing, but the key facts, specifically that the iPhone was developed by a team at Apple under the leadership of Steve Jobs and was released on June 29, 2007, should not be altered.
More concretely, changing "invented" to "created" would be acceptable. However, changing "Apple" to "Orange" or "Samsung" (or changing the date) would obviously be a significant error.
Direct Preference Optimization
The notable method employed by the researchers here is Direct Preference Optimization (DPO), which is becoming a popular alternative to Reinforcement Learning with Human Feedback (RLHF).
RLHF is the method behind ChatGPT, Llama 2 Chat, and others. For more information about RLHF, please refer to my other article linked below:
DPO is conceptually simpler than RLHF, as it directly trains the LLM on response-preference rankings instead of creating a reward model. Essentially, DPO optimizes a classification loss computed directly on preference data, making it much easier to implement and use than RLHF. Moreover, DPO has recently been successfully used (e.g., the Zephyr 7B model by Lewis Tunstall and colleagues, which seems to outperform the bigger Llama-2 70b Chat model trained via RLHF) and is on its way to becoming one of the most popular finetuning approaches.
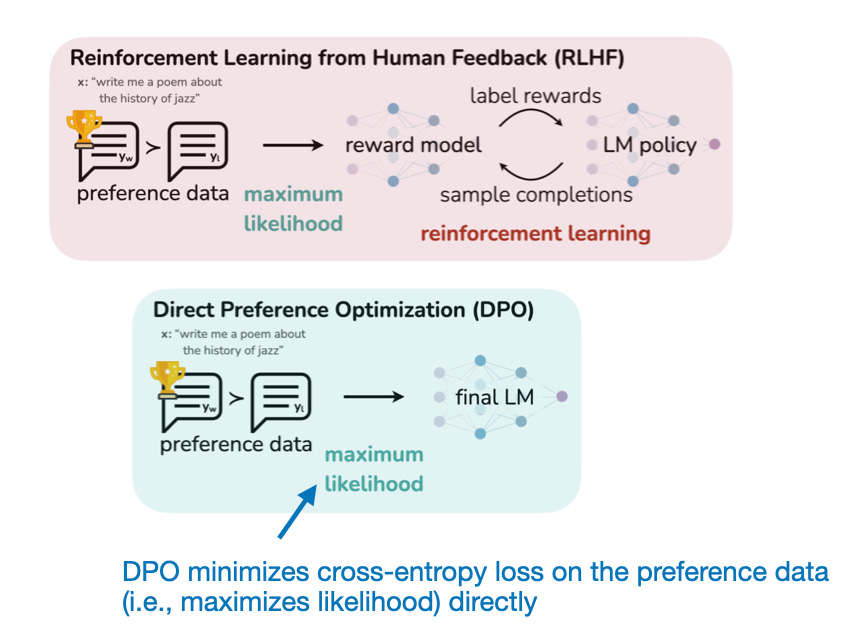
Side note: Three of the authors of this Fine-tuning Language Models for Factuality paper were also part of the original DPO paper.
Removing Human Labeling Effort
Compared to RLHF, DPO simplifies the finetuning process since it doesn't require creating a reward model. However, DPO still requires generating preference data, typically involving sampling responses from the model for human fact-checking. A human labeler then ranks these responses by preference.
The authors note that fact-checking an LLM response, such as a biography of a well-known person, takes an average of 9 minutes per response for a human. Checking 505 biographies, the dataset used in this study, would cost about $2000.
As an alternative to human fact-checking, the authors suggest a variant of DPO that completely removes the human from the loop. This approach is somewhat analogous to RLAIF, reinforcement learning with AI feedback, which, unlike RLHF, does not require human input.
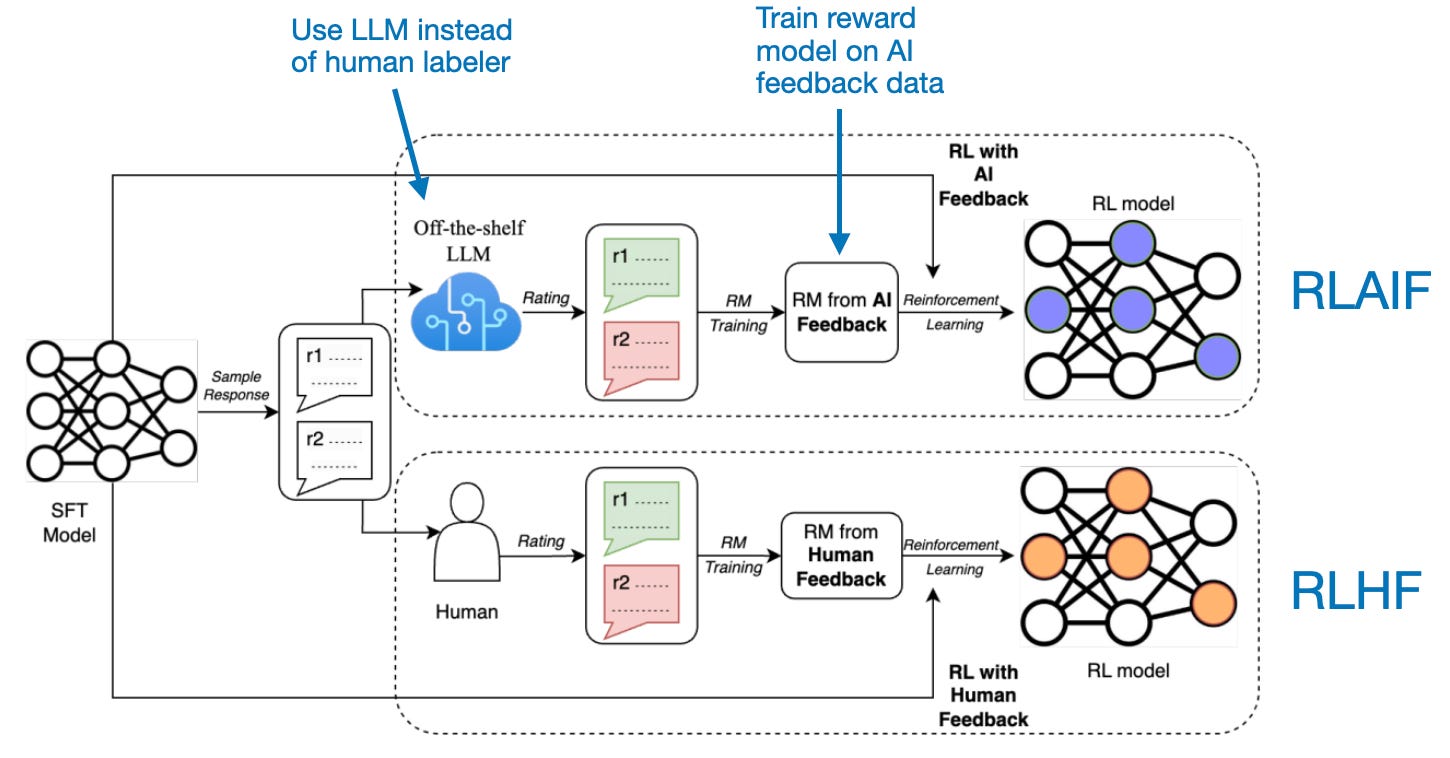
In the "Fine-tuning Language Models for Factuality" paper, the authors experiment with two methods for creating fully automated "truthfulness" scores:
-
A reference-based truthfulness score, abbreviated as FactTune-FS.
-
A reference-free truthfulness score, abbreviated as FactTune-MC.
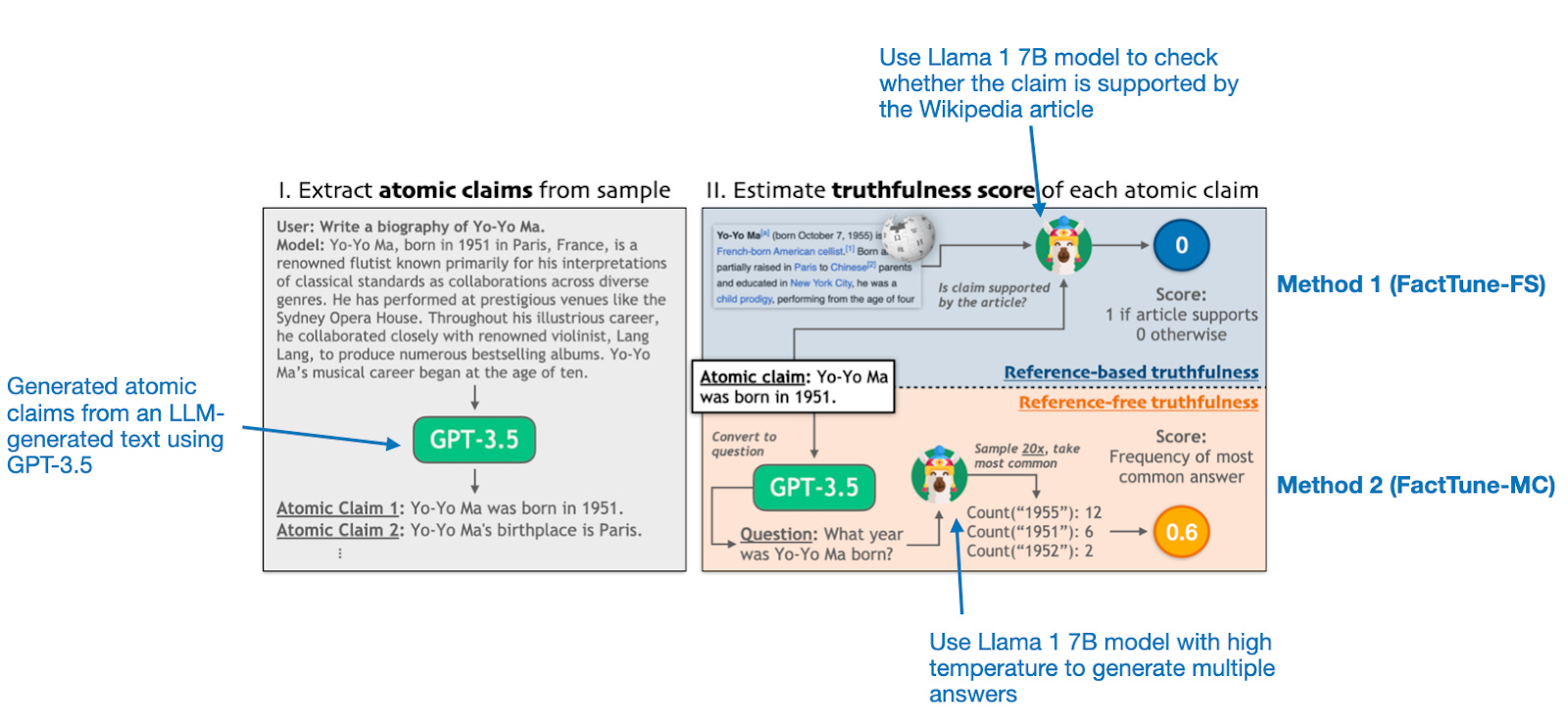
The first step in each of the two methods is to obtain a dataset of responses, such as biographies of well-known persons, and extract atomic claims using a GPT-3.5 model. In Method 1 (FactTune-FS), the authors utilize the existing FactScore approach. They consider Wikipedia as a source of truth and use a Llama 1 7B model to verify if the atomic claim is supported by the article. I assume that the reason why a small Llama 1 model is used here it that it was the model employed in the original FactScore paper.
For Method 2 (FactTune-MC), the authors employ GPT-3.5 to first transform atomic claims into questions. These questions are then used as queries for a Llama 1 model with a high-temperature setting, enabling it to generate multiple different responses. The frequency of the most common response is treated as the truthfulness score. The advantage of this FactTune-MC over Method 1 is that it doesn't require a reference article from an external source.
The truthfulness scores are then used to create preference ratings for their datasets, and the models are finetuned using the DPO pipeline. It turns out that FactTune-FS performs exceptionally well, surpassing all other tested methods, including RLHF and regular supervised finetuning, in reducing factual error rates.
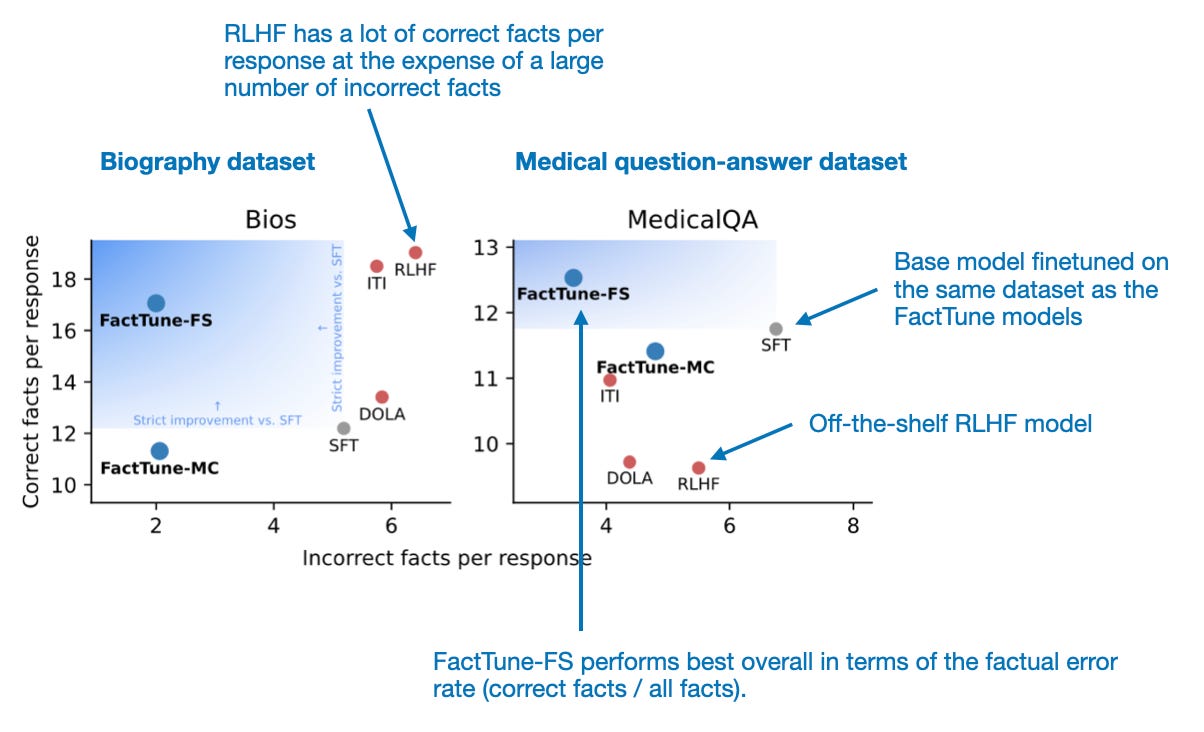
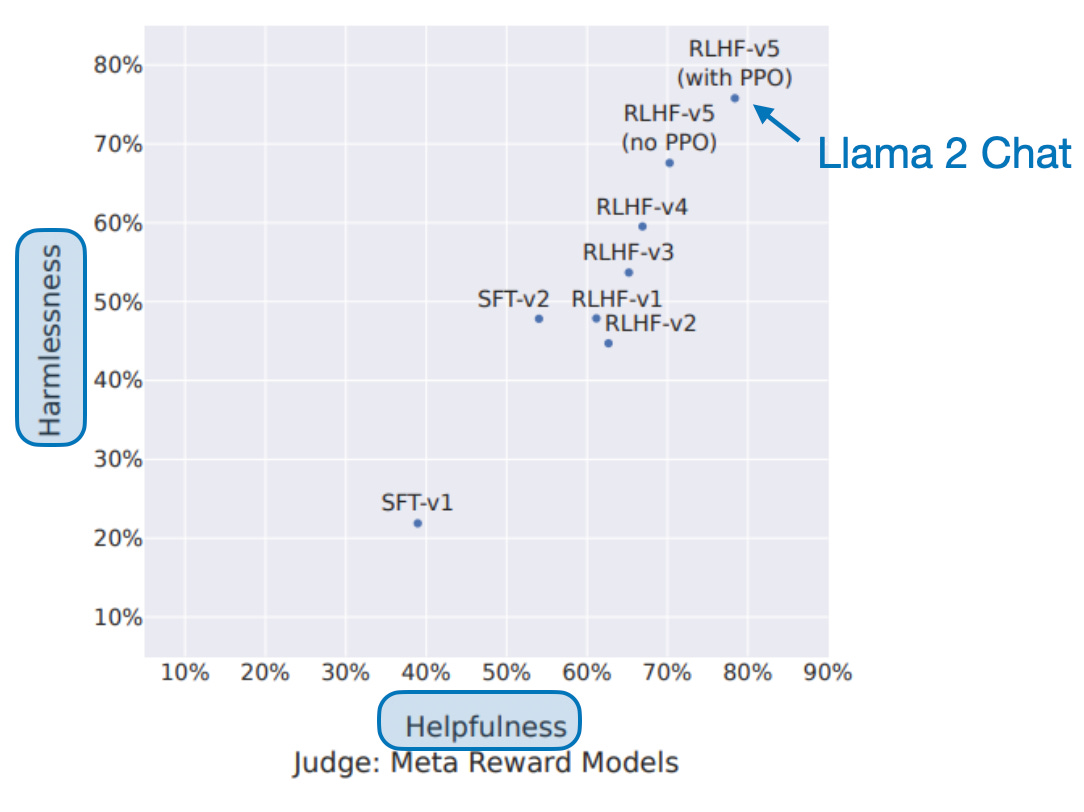
Note that the authors experimented with finetuning Llama 1 and Llama 2. However, they didn't specify which model was finetuned in the figure above. Based on matching the numbers from Table 2 in the paper, I assume it is the Llama 2 model. Here, RLHF refers to the Llama 2 Chat model provided by Meta. The SFT model is a Llama 2 model they finetuned with regular supervised learning (instead of DPO on preference data), using the same biographies and medical QA datasets as for the FactTune-FS model.
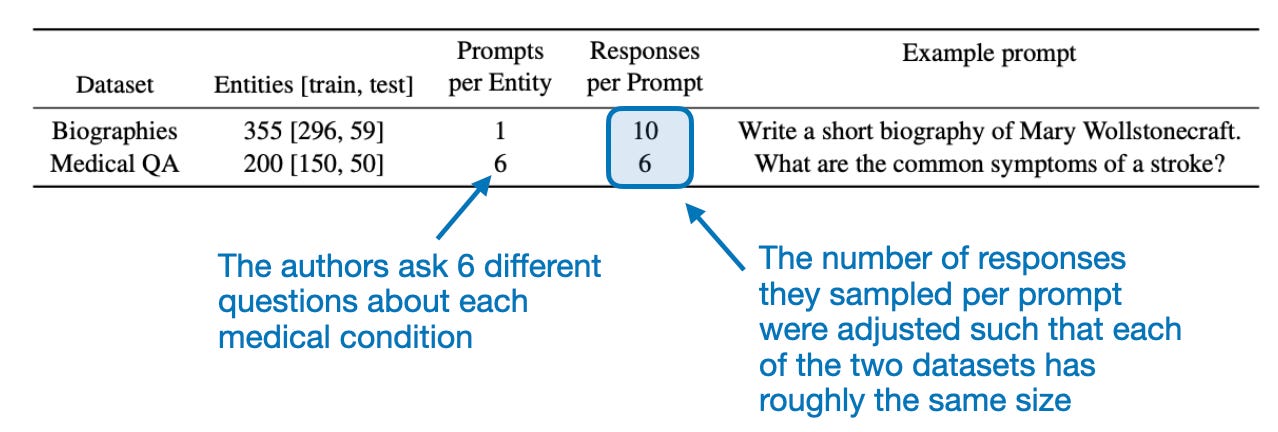
Datasets
As hinted at in the figure above, the authors worked with two datasets: biographies of well-known people and medical QA. The datasets are relatively small, yet each response contains several facts. Hence, the total number of facts used here may well be into the four-digit range for each of the two datasets.
Robustness
Based on the description above, we can see that there are many moving parts relying on LLMs. For example, generating atomic claims with GPT-3.5 or using a 7B Llama 1 model to check whether a claim is supported, among other tasks. This means that we are placing considerable trust in LLMs to essentially fact-check another LLM.
Overall, it's quite surprising how well this works. However, the elephant in the room concerns whether the models, given that the number of correct and incorrect responses is based on the automated FactScore procedure, are overfitted to FactScore artifacts and do not actually create factually accurate responses.
To address concerns regarding the FactScore evaluation, the authors employ human labelers to evaluate the models. As shown in the figure below, the FactScore scores largely agree with the scores from human labelers. Assuming we trust the accuracy of the humans verifying the responses, the FactScore is only slightly inflated.

Tradeoffs
Llama 2 Chat was trained using Reinforcement Learning with Human Feedback (RLHF) to optimize helpfulness and harmlessness. And the authors found that applying FactTune-FS on top of it further improves the factual correctness of Llama 2 Chat. However, I wonder if this improvement comes at the cost of decreased helpfulness and harmlessness.
In theory, there should be a high correlation between helpfulness and factual correctness. For instance, a response that is factually correct should be more helpful than one that is factually incorrect. However, this aspect may not have been fully captured in the way the Llama 2 reward model data was labeled. That is, the humans who worked on the helpfulness rankings for Llama 2 training might not have fact-checked all responses carefully. Consequently, a response that was convincing, even if potentially factually incorrect, could have been regarded as helpful.
Of course, making an already helpful response even more factually correct is preferable. However, I wonder if this has a negative impact on conversational skills or other tasks that do not necessarily rely on facts, such as translation, grammar correction, fiction writing, and so on.
While we don't have any data on whether DPO fine-tuning for factual correctness decreases the helpfulness and harmlessness scores that Llama 2 Chat has been optimized for, the authors included some interesting observations:
-
We observe that FactTune-FS and FactTune-MC samples tend to have more objective and direct sentences and less of a conversational or story-telling style compared to the SFT model
-
The FactTune-FS and FactTune-MC samples have simpler sentences and lack casual phrases.
-
As another example the FactTune-FS and FactTune-MC biographies describe accurate facts, but not in a natural chronological order.
Limitations and Conclusions
Overall, I think this is a very well-written paper demonstrating the usefulness of DPO fine-tuning. And while some LLMs are explicitly finetuned to reduce harmfulness, this paper also shows that we can successfully finetune models using other objectives.
One minor critique is that the datasets used seem surprisingly small. On the other hand, the fact that the approach still works so well is even more impressive. The good news is that their approach is fully automated and, therefore, could easily be scaled to larger datasets.
2) Orca 2: Teaching Small Language Models How to Reason
The paper Orca 2: Enhancing Reasoning in Smaller Language Models presents an effective method to significantly boost the reasoning abilities of smaller language models (LLMs) by using specialized synthetic data for training. The key idea is to implement various reasoning techniques to teach the LLM to recognize the most effective solution strategy for each task.
The resulting Orca-2-13B model outperforms similar-sized models in zero-shot reasoning tasks, showing an impressive 47.54% improvement over Llama-2-Chat-13B and 28.15% over WizardLM-13B. Note that all three models (Orca, Llama-2-Chat, and WizardLM) used the same Llama-2 base model for finetuning.
Moreover, Orca-2-13B can also compete with models that are 5-10x larger, like LLaMA-2-Chat-70B, WizardLM-70B, and ChatGPT.
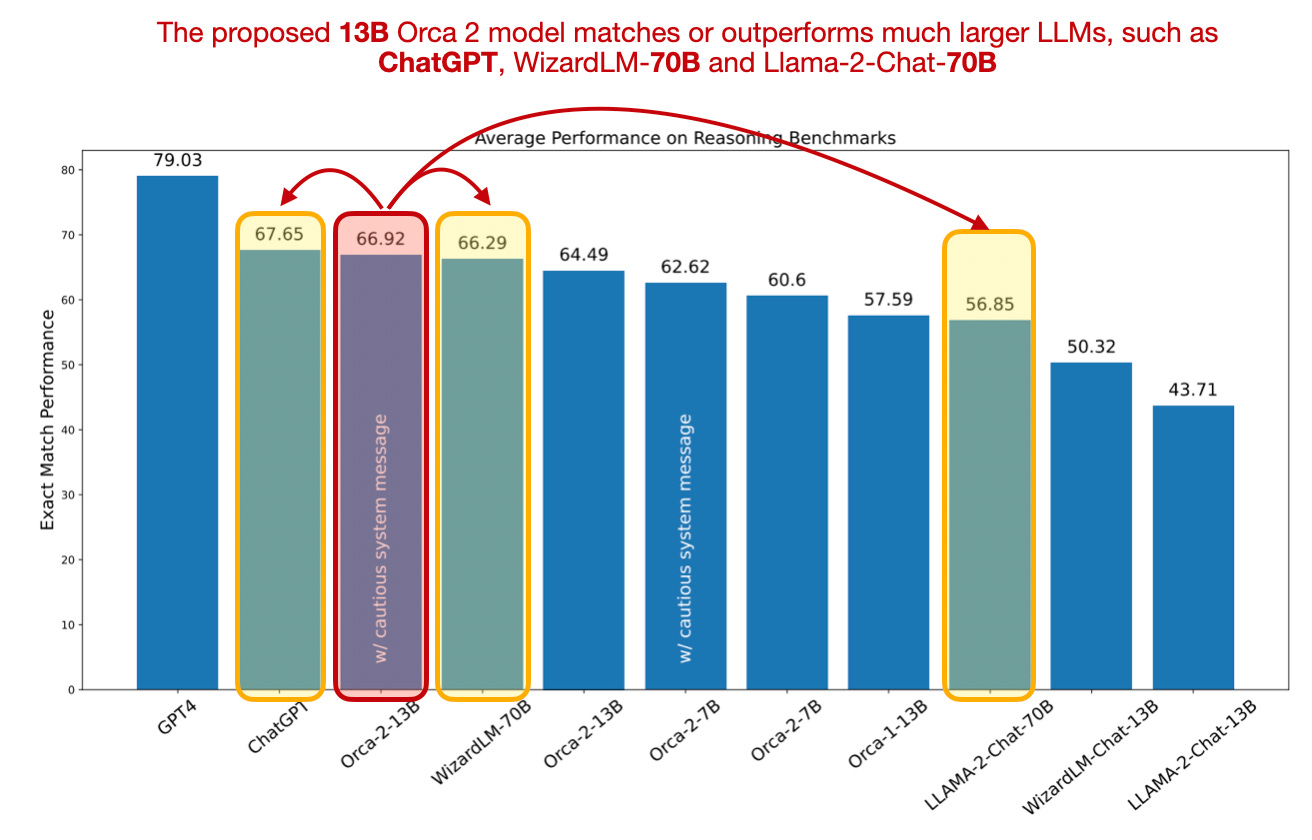
(The "small cautious system message prompt" in the figure above is a small implementation detail where they added the following text to the instruction: "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior.")
Imitation Learning
In the past few months, imitation learning has become all the rage. In the context of Large Language Models (LLMs), imitation learning involves training a smaller target LLM (referred to as the "student") on the outputs of a larger source LLM (referred to as the "teacher"), such as GPT-4.
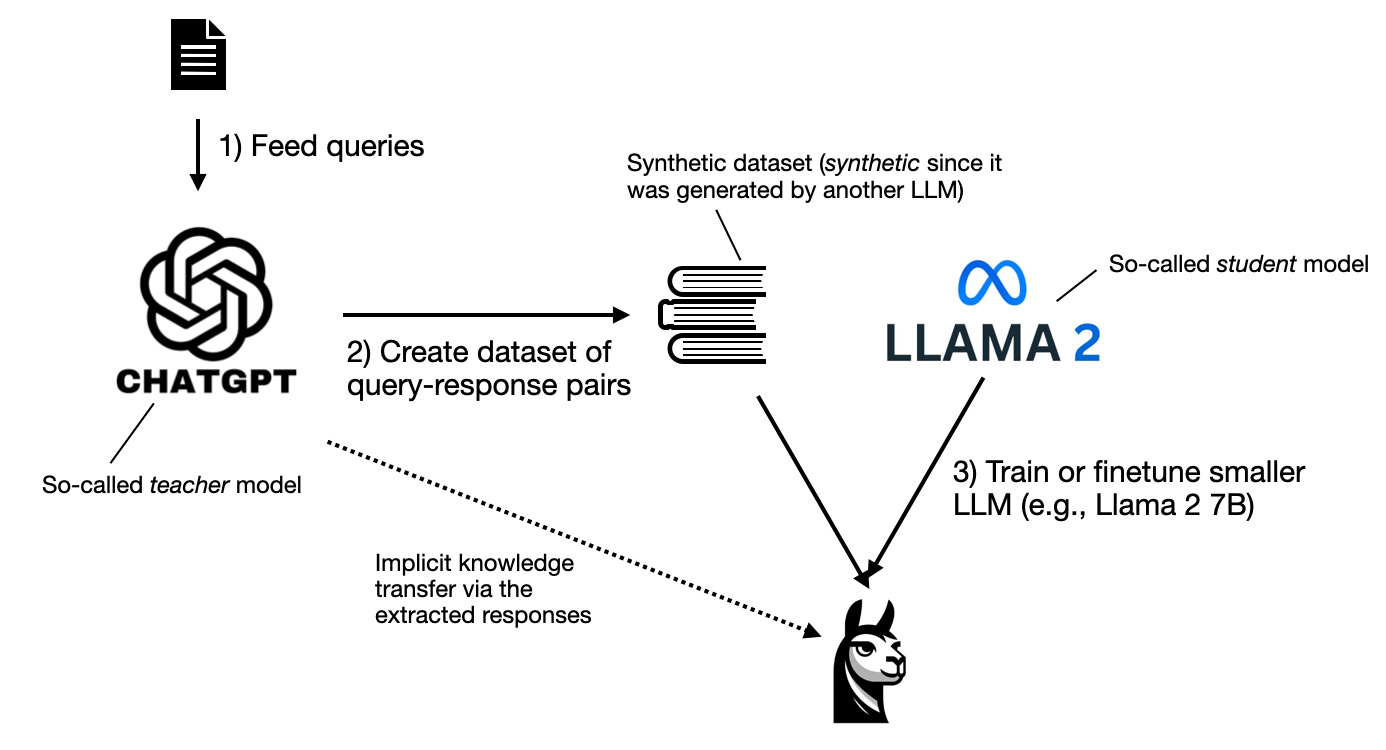
The paper titled The False Promise of Imitating Proprietary LLMs points out a key issue with smaller language models trying to copy larger ones. While these smaller models can mimic the style of the larger ones and create content that seems impressive at first, a closer look often reveals that their output is not accurate. This means that, despite appearing to work well, they actually make mistakes when we examine what they produce more closely.
In the Orca 2 paper, the authors explain that small language models (which now include those with 7 to 13 billion parts, considered "small" in today's standards) can't just rely on copying what bigger models do to get better. They suggest a different approach: teaching these smaller models unique ways of solving problems or thinking, different from the big models. This is because the smaller models may not be able to employ the same solution strategies used by the larger ones due to having a smaller capacity (due to the reduced number of parameters).
Teaching Different Reasoning Strategies
The authors call their approach explanation tuning, which is mainly about creating a synthetic dataset using specific queries to extract answers with high-quality explanations from the source LLM (here GPT-4).
If you have used ChatGPT before (especially the earlier versions), you probably know that the answer quality varies greatly based on how you prompt the model. Some tasks require different prompting strategies, such as step-by-step, recall-then-generate, recall-reason-generate, direct answer, etc.
The authors argue that small models should not be trained on or use a specific solution strategy but that the model's solution (or reasoning) strategy should depend on the task itself.
They propose the following training procedure for Orca 2, where "Orca" (ref.) is the predecessor model:

Note that during its training, the smaller model only learns from the task and the responses, without seeing the original questions or commands that were used to extract these responses from the larger teacher LLM.
In other words, there is nothing special about the base LLM (here, Llama 2) and how it is finetuned. The innovation here, which leads to astoundingly good results, is entirely in how the synthetic training data is created.

Benchmarks & Results
The resulting Orca-2 models perform exceptionally well on reasoning and knowledge benchmarks when compared to other models of similar size, as shown in the figure below.
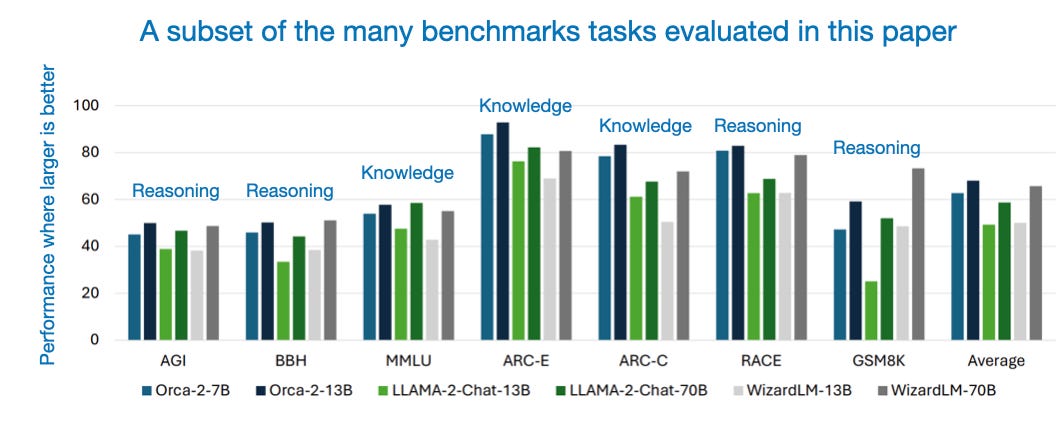
Note that the figure above is only a small excerpt. The benchmarks in the Orca 2 paper are fairly comprehensive, covering reasoning capabilities, knowledge and language understanding, text completion, multi-turn open-ended conversations, grounding and abstractive summarization, safety, and truthfulness.
The 13B model performs astoundingly well, outperforming other models of the same size by a significant margin. The multi-turn conversational benchmarks are the only benchmark where Orca-2-13B performs slightly worse than Llama-2-Chat. The author's explanation that it's because the training datasets didn't include such conversations makes this entirely plausible.
In my view, the strength of a language model does not lie in its universality but in its specialization. It's not essential for every task to be tackled by a conversational AI. I much prefer a suite of highly specialized, exceptionally strong tools over a jack-of-all-trades approach that offers only mediocrity across the bench.
Conclusion and Final Thoughts
It's very impressive what has been achieved using a 13B Llama 2 model as a starting point. I'm curious and excited to see if these significant improvements in reasoning and other benchmarks will also apply when tailored synthetic data strategies are utilized with 70B Llama 2 models or larger.
The paper presents a comprehensive list of benchmarks, and the excellent results speak for themselves. However, a minor critique is that the authors emphasize the importance of using smaller models to select the most effective solution strategy based on the task. Yet, they did not conduct any experiments or ablation studies to investigate this aspect for their Orca 2 models. The sole piece of evidence is that Orca 2 models, which are Llama 2 models trained on a carefully curated synthetic data mix, perform better than Llama 2 models fine-tuned by other means, including larger models.
On the positive side, it's noteworthy that the results were achieved entirely through supervised fine-tuning on curated synthetic data. The Orca 2 models have not undergone any RLHF or DPO fine-tuning. It's plausible, and even likely, that RLHF or DPO finetuning could further improve these models, making it an intriguing topic for future research.
PS: The weights for Orca 2 are publicly available here (https://ift.tt/V7b5lJp).
3) Simplifying Transformer Blocks
In "Simplifying Transformer Blocks" the authors look into how the standard transformer block, essential to LLMs, can be simplified without compromising convergence properties and downstream task performance.
Based on signal propagation theory and empirical evidence, they find that many parts can be removed to simplify GPT-like decoder architectures as well as encoder-style BERT models:
-
skip connections
-
projection and value parameters
-
sequential attention and MLP sub-blocks (in favor of a parallel layout)
-
normalization layers (LayerNorm)
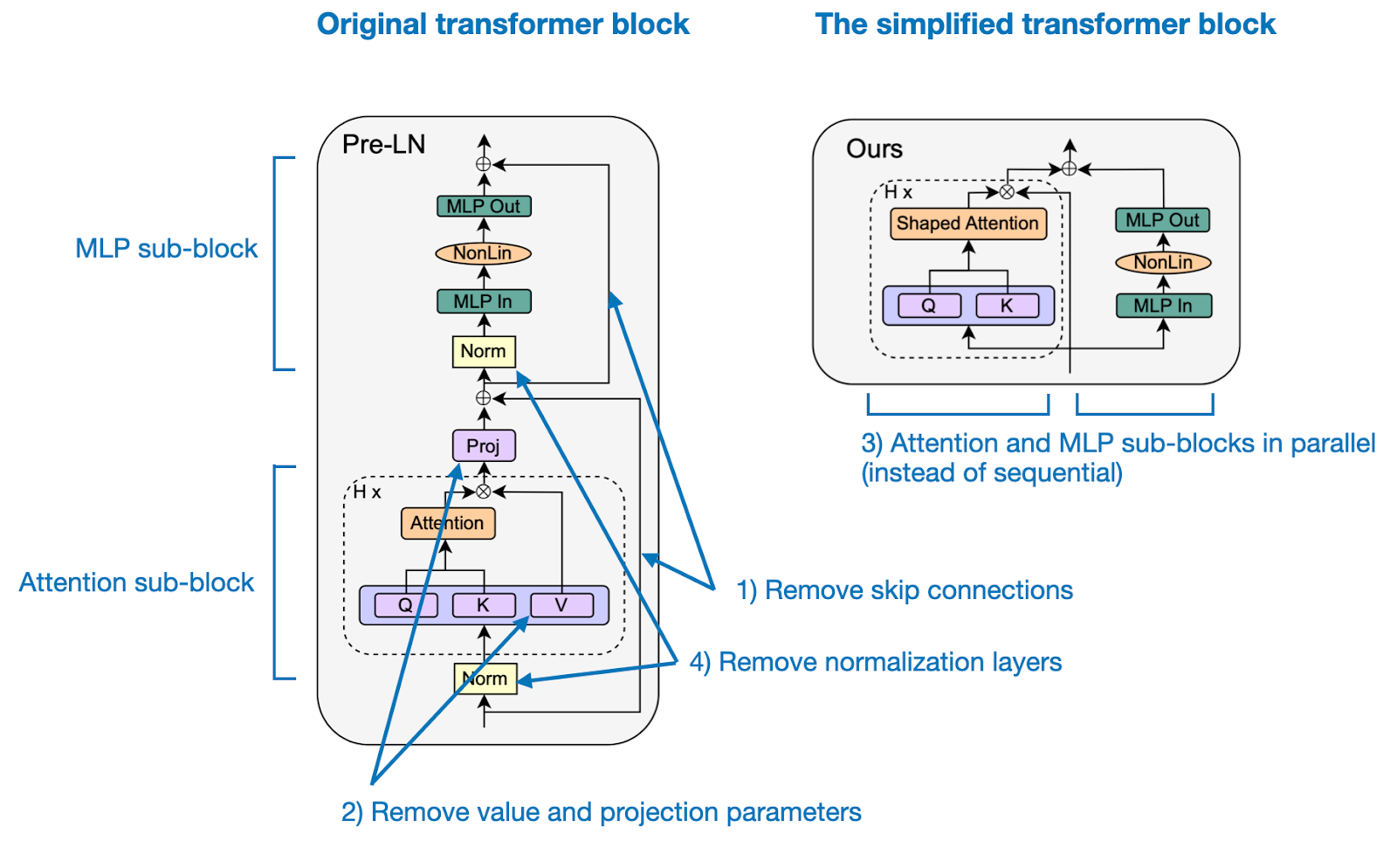
Removing Skip Connections
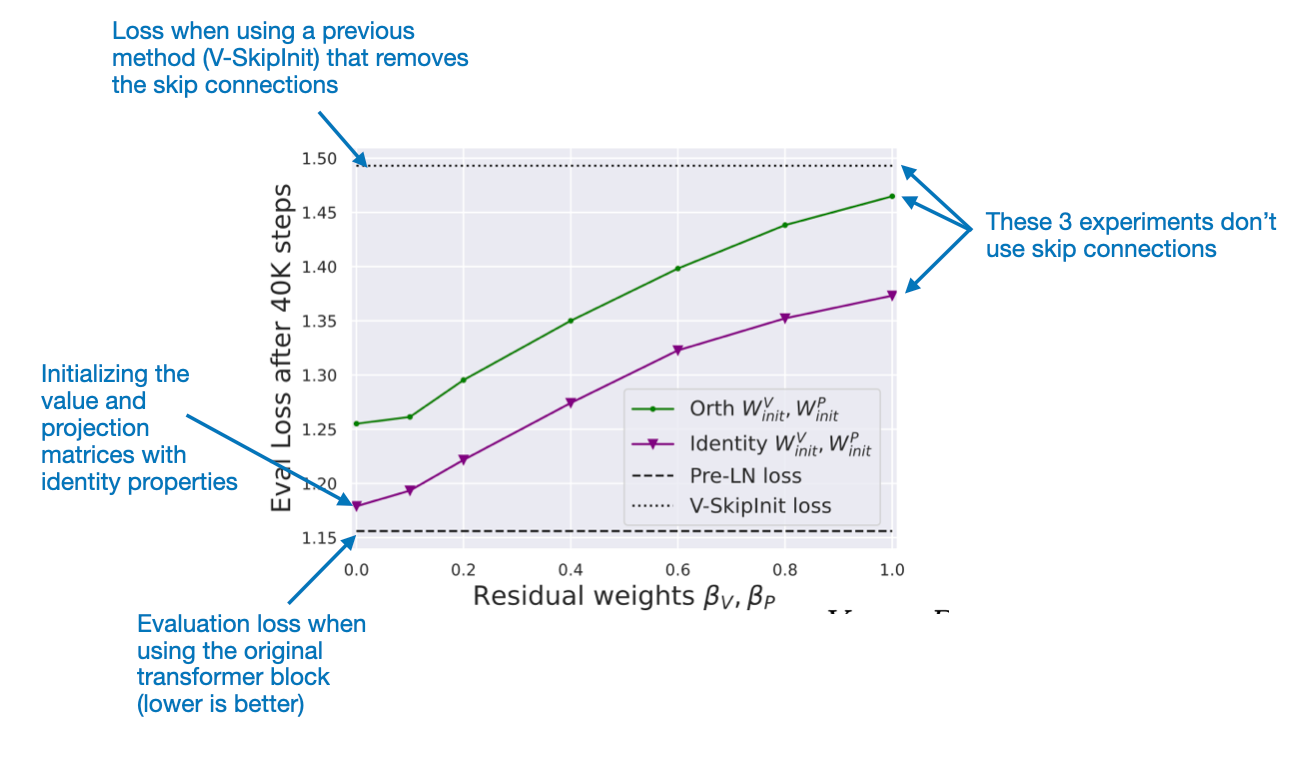
As networks become deeper, gradients can diminish as they backpropagate through layers, making it difficult to train the model. Skip connections, also known as residual connections, are a common architectural feature in deep neural nets to alleviate the vanishing gradient problem.
Naively removing the skip connections would lead to gradient problems. So, to avoid that, the authors propose specific weight initialization schemes motivated by signal propagation theory. I highly recommend reading this excellent paper for those interested in the details since it has tons of interesting insights.
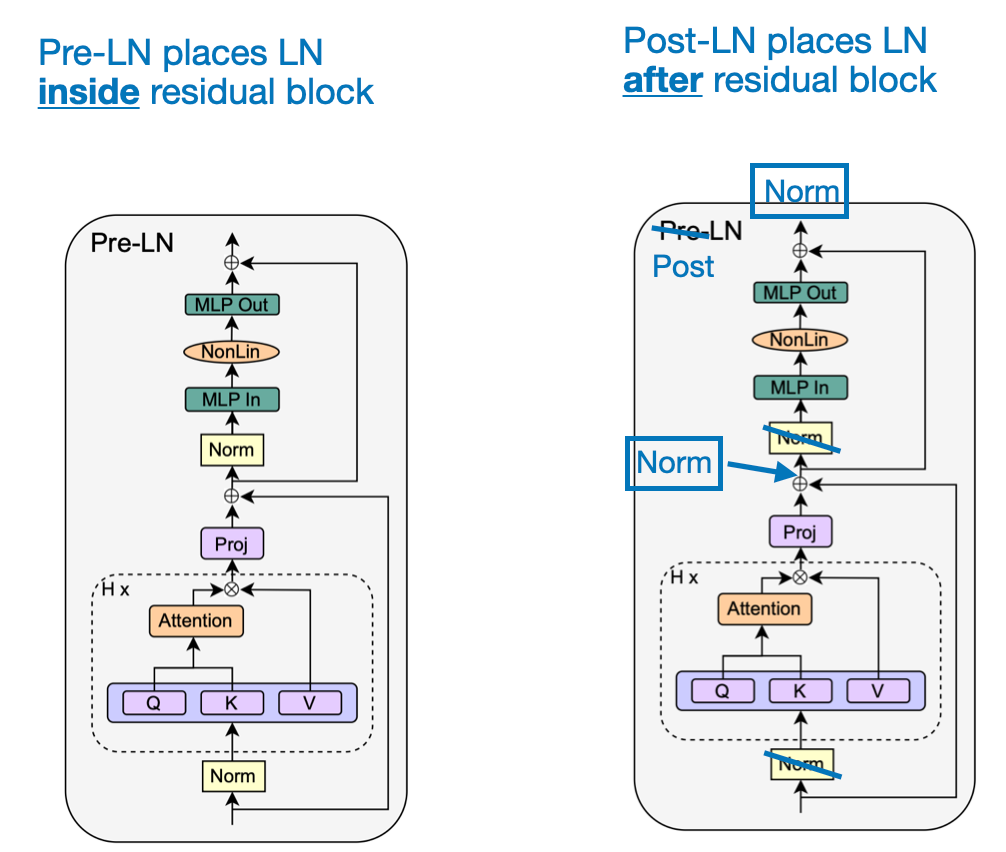
As a side note, the "Pre-LN" in the upper corner of the original transformer block diagram refers to the placement of the LayerNorm ("Norm") layer. Actually, the original transformer proposed in Attention is All You Need used a Post-LN setup. This shift from Post-LN to Pre-LN has become more popular in recent transformer models because it simplifies the training process.
One of the key benefits of Pre-LN is that it is less sensitive to the initial learning rate and does not require a careful warm-up of the learning rate, which can be a critical factor in training stability and effectiveness. For more details on the advantages and disadvantages of Pre- and Post-LN, I recommend this video by my friend and collaborator Vahid.
Removing other parts
The insights from the experiments in the previous section (setting the weighting hyperparameters β to 0) led the authors to successfully remove projections and value parameters as well. The authors argue that the value and projection matrices are simply linear projections of the inputs (as opposed to the linear layers in the MLP sub-block with non-linear activation functions between them) and thus might be redundant.
The authors also tried to remove the normalization layers (aka LayerNorm). The rationale is that Pre-LayerNorm implicitly downweights the residual branches. And this downweighting can also be achieved by other mechanisms that the authors already account for via their previous modifications, making LayerNorm theoretically redundant in this setup.
However, the authors observed a slight degradation in terms of the training convergence, which currently cannot be explained by signal propagation theory. In conclusion, they recommend keeping LayerNorm in the transformer block.
Limitations and Conclusion
The authors experimented with relatively small models, and while there is no reason to believe these findings wouldn't generalize to larger language models, there is yet no empirical evidence for this. I don't fault the authors for not including such experiments. On the contrary, I am very impressed with this work from a two-author team, and it ranks among my favorite papers I've read this year. They also excelled in referencing tons of related works, motivating their experiments. I definitely recommend reading this paper for the references alone.
In my opinion, one of the main benefits of the proposed modifications is to gain a better understanding and simplifying the transformer architecture. However, there authors also report a 15% increase in training throughput and a requirement for 15% fewer parameters.
I hope larger research labs with more compute resources also find this work interesting and apply these insights to new architectures (ideally sharing their insights and outcomes, of course). I am definitely interested to see if these modifications are viable for larger LLMs as well.
Other Interesting Research Papers
ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching Up? by Chen, Jiao, Li, and Qin (29 Nov), https://arxiv.org/abs/2311.16989
-
In this study, researchers survey instances where an open source LLM is reported to match or surpass the capabilities of ChatGPT.
Language Model Inversion by Morris, Zhao, Chiu, Shmatikov, and Rush (22 Nov), https://arxiv.org/abs/2311.13647
-
This study demonstrates that next-token probabilities provide substantial information about preceding text, allowing the recovery user prompts from LLM-generated outputs.
Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model by Yang, Tao, Lyu, Ge, et al. (22 Nov), https://arxiv.org/abs/2311.13231
-
D3PO is a direct preference optimization (DPO) method that introduces a cost-effective, direct approach to finetune diffusion models using human feedback without needing a reward model.
PaSS: Parallel Speculative Sampling by Monea, Joulin, and Grave (22 Nov), https://arxiv.org/abs/2311.13581
-
This study proposes parallel decoding to address the memory bottleneck in generating tokens with large language models, offering up to 30% faster performance with minimal extra parameters, by generating multiple tokens simultaneously without needing a secondary model.
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs by Shah, Ruiz, Cole, Lu, et al. (22 Nov), https://arxiv.org/abs/2311.13600
-
ZipLoRA effectively merges independently trained style and subject low-rank adaptations for generative models (here, applied to diffusion models).
GAIA: A Benchmark for General AI Assistants by Mialon, Fourrier, Swift, Wolf, et al. (21 Nov), https://arxiv.org/abs/2311.12983
-
GAIA is a new benchmark for General AI Assistants, featuring real-world questions that testfundamental skills like reasoning and tool-use, where humans significantly outperform current AI/LLMs like GPT-4.
System 2 Attention (is something you might need too) by Weston and Sukhbaatar (20 Nov), https://arxiv.org/abs/2311.11829
-
The proposed System 2 Attention (S2A) mechanism improves Transformer-based LLMs by regenerating input context to focus on relevant information, enhancing performance in tasks requiring factuality, objectivity, and reducing irrelevant or biased content.
Orca 2: Teaching Small Language Models How to Reason by Mitra, Del Corro, Mahajan, Codas, et al. (18 Nov), https://arxiv.org/abs/2311.11045
-
Following in the footsteps of Orca, Orca 2 focuses on teaching small language models different reasoning strategies instead of solely relying on imitation learning, to enhance their problem-solving capabilities in ways that may differ from larger models.
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2 by Ivison, Wang, Pyatkin, Lambert, et al. (17 Nov), https://arxiv.org/abs/2311.10702
-
The authors share the TÜLU 2 model suite, including a 70B DPO-finetuned model, which is the largest DPO-finetuned LLM to date.
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection by Lin, Zhu, Ye, Ning, et al. (16 Nov), https://arxiv.org/abs/2311.10122
-
Video-LLaVA is a large vision-language model that unifies visual representations with language features, and the unified tokenization approach outperforms models like ImageBind-LLM, Llama-Adapter, etc., that don't align the image and video projections.
Emu Edit: Precise Image Editing via Recognition and Generation Tasks by Sheynin, Polyak, Singer, Kirstain, et al. (16 Nov), https://arxiv.org/abs/2311.10089
-
Emu Edit is a multi-task image editing model that achieves state-of-the-art results in instruction-based image editing by training across a broad range of tasks and employing learned task embeddings.
Tied-Lora: Enhancing Parameter Efficiency of LoRA with Weight Tying by Renduchintala, Konuk, and Kuchaiev (16 Nov), https://arxiv.org/abs/2311.09578
-
In this paper, researchers experiment with weight tying (i.e., weight sharing) for LoRA (low-rank adaptation) but find that not tying weights performs best on average; on some tasks, good performance can be attained by tying weights, which reduces the number of required LoRA parameters to 13%.
Exponentially Faster Language Modelling by Belcak and Wattenhofer (15 Nov), https://arxiv.org/abs/2311.10770
-
The authors propose UltraFastBERT, a BERT (encoder-style LLM) variant using only 0.3% of its parameters, offering up to 78x speedups while maintaining prediction accuracy.
Llamas Know What GPTs Don't Show: Surrogate Models for Confidence Estimation by Shrivastava, Liang, and Kumar (15 Nov), https://arxiv.org/abs/2311.08877
-
The paper suggests using a surrogate confidence model with accessible probabilities to estimate the confidence of state-of-the-art LLMs like GPT-4 and Claude-v1.3, which don't provide softmax probabilities, finding this approach yields higher accuracy on 9 out of 12 datasets compared to asking an LLM for its confidence in its answer.
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models by Yu, Zhang, Pan, Ma, et al. (15 Nov), https://arxiv.org/abs/2311.09210
-
The paper introduces Chain-of-Noting, a method to enhance Retrieval-augmented Language Models by generating sequential notes on retrieved documents for better evaluation and response accuracy, even with noisy or irrelevant information, using training data created by ChatGPT on a LLaMa-2 7B model.
Fusion-Eval: Integrating Evaluators with LLMs by Shu, Wichers, Luo, Zhu, et al. (15 Nov), https://arxiv.org/abs/2311.09204
-
The paper introduces Fusion-Eval, a prompt-based LLM evaluation aggregator that uses a template to incorporate assistant evaluator scores and model responses, generating a score (along with a rationale) without finetuning, and employs another LLM to plan and optimize the evaluation process.
Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models by Lu, Yuan, Lin, Lin, et al. (15 Nov), https://arxiv.org/abs/2311.08692
-
The study introduces Zooter, a reward-guided routing method for LLM ensembles that identifies and leverages the latent expertise of individual models, reducing computational overhead and outperforming traditional reward model ranking methods in both efficiency and performance across a variety of domains and tasks.
Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks by Mitchell, Palmarini, and Moskvichev (14 Nov), https://arxiv.org/abs/2311.09247
-
The study assesses the abstract reasoning capabilities of text-only and multimodal GPT-4 using the ConceptARC benchmark, revealing that neither version exhibits humanlike robust abstraction abilities, despite evaluating GPT-4 on detailed one-shot prompts and GPT-4V on image tasks with zero- and one-shot prompts.
DiLoCo: Distributed Low-Communication Training of Language Models by Douillard, Feng, Rusu, Chhaparia, et al. (14 Nov), https://arxiv.org/abs/2311.08105
-
This paper introduces DiLoCo, a distributed optimization algorithm for training language models on large numbers of small and poorly connected devices, showing robust performance and reduced communication needs compared to traditional methods.
A Survey on Language Models for Code by Zhang, Chen, Liu, Liao, et al. (14 Nov), https://arxiv.org/abs/2311.07989v1
-
This work comprehensively reviews code processing with language models, examining over 50 models and 500 works, and discusses the evolution from statistical models to LLMs, including code-specific features and future directions.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models by Li, Yang, Liu, Ma, et al. (12 Nov), https://arxiv.org/abs/2311.06607
-
The study introduces a two-pronged approach that enhances existing models on vision-language tasks: vision encoders to process higher-resolution images (up to 896 x 1344 pixels) and a multi-level description generation method for deeper contextual understanding between scenes and objects.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module by Luo, Tan, Patil, Gu, et al. (9 Nov), https://arxiv.org/abs/2311.05556
-
Latent consistency models (distilled from latent diffusion models) significantly accelerate text-to-image tasks with high-quality outputs and reduced training time; in this technical report, the authors describe a successful application of LoRA (low-rank adaptation) to lower the resource requirements of diffusion models even further.
Removing RLHF Protections in GPT-4 via Fine-Tuning by Zhan, Fang, Bindu, Gupta, et al. (9 Nov), https://arxiv.org/abs/2311.05553
-
While reinforcement learning with human feedback (RLHF) is usually used to reduce harmful outputs of LLMs, researchers show that these protections can be easily removed with finetuning -- the researchers obtained a 95% success rate using only 340 examples.
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions by Huang, Yu, Ma, Zhong, et al. (9 Nov), https://arxiv.org/abs/2311.05232
-
This survey provides a comprehensive overview of the challenges and recent advances in addressing hallucinations in LLMs that impact their reliability and practical deployment.
Holistic Evaluation of Text-To-Image Models by Lee, Yasunaga, Meng, Mai, et al. (7 Nov), https://arxiv.org/abs/2311.04287
-
This paper introduces the HEIM benchmark that evaluates text-to-image models across 12 diverse criteria (from quality to originality), revealing that different models have different strengths, with no single model excelling in all areas.
OtterHD: A High-Resolution Multi-modality Model by Li, Zhang, Yang, Zhang, et al. (7 Nov), https://arxiv.org/abs/2311.04219
-
The OtterHD-8B is a new multimodal LLM, derived from Adept's Fuyu-8B multimodal model, that can handle high-resolution visual inputs as well as flexible input dimensions for diverse inference applications.
S-LoRA: Serving Thousands of Concurrent LoRA Adapters by Sheng, Cao, Li, Hooper, et al. (6 Nov), https://arxiv.org/abs/2311.03285
-
This paper proposes efficiency techniques (unified paging and a new tensor parallelism strategy) for serving multiple LoRA (low-rank adaptation) adapters during inference.
GPT4All: An Ecosystem of Open Source Compressed Language Models by Anand, Nussbaum, Treat, Miller, et al. (Nov 6), https://arxiv.org/abs/2311.04931
-
This short paper describes the development and evolution of GPT4All, an open-source initiative designed to democratize access to LLMs, aiming to overcome the limitations of costly infrastructure, restricted access, and lack of transparency in existing models.
CogVLM: Visual Expert for Pretrained Language Models by Wang, Lv, Yu, Hong, et al. (6 Nov), https://arxiv.org/abs/2311.03079
-
CogVLM is a new multimodal LLM that integrates a trainable visual expert module for fusing visual and language features instead of a frozen image encoder module.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation by Vu, Iyyer, Wang, Constant, et al. (5 Nov), https://arxiv.org/abs/2310.03214
-
This paper introduces the FreshQA benchmark designed to test models on quickly-changing knowledge and false premises, as well as FreshPrompt, an effective few-shot prompting method to enhance LLM performance by integrating search engine data.
Levels of AGI: Operationalizing Progress on the Path to AGI by Morris, Sohl-dickstein, Fiedel, Warkentin, et al. (4 Nov), https://arxiv.org/abs/2311.02462
-
Researchers at DeepMind have attempted to define AGI (Artificial General Intelligence) using a five-level system, ranging from level 1, which includes emerging AI such as ChatGPT, to level 5, described as "superhuman" and capable of outperforming 100% of humans (levels 2-5 have not yet been achieved).
FlashDecoding++: Faster Large Language Model Inference on GPUs by Hong, Dai, Xu, Mao, et al. (2 Nov), https://arxiv.org/abs/2311.01282
-
FlashDecoding++ is an LLM inference engine that addresses key challenges by introducing techniques like asynchronized softmax, flat GEMM optimization, and heuristic dataflow adaptation, achieving up to 4.86x and 2.18x speedups on both NVIDIA and AMD GPUs.
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models by Yadlowsky, Doshi, and Tripuraneni (1 Nov), https://arxiv.org/abs/2311.0087
-
This study examines the ability of transformers to adapt to new in-context tasks based on their pretraining data mix, revealing their limitations in out-of-domain tasks and suggesting their in-context learning is more dependent on data coverage than on fundamental generalization capabilities.
Attending NeurIPS 2023
If you are attending NeurIPS 2023, I’ll be at the Lightning AI booth in the exhibitor hall on Thursday (Dec 14th) and happy to chat. Don’t hesitate stop by and say hi! (My colleagues will also be there Mon-Thu if you want to chat about AI & open source.)
I’ll also give a talk at the NeurIPS 2023 Large Language Model Efficiency Challenge: 1 LLM + 1GPU + 1Day workshop if you are interested!

source https://magazine.sebastianraschka.com/p/research-papers-in-november-2023








No comments