https://ift.tt/kJZ1BT0 Training and using models are two separate phases (Image by author) Building models vs. using models After finis...
Training and using models are two separate phases
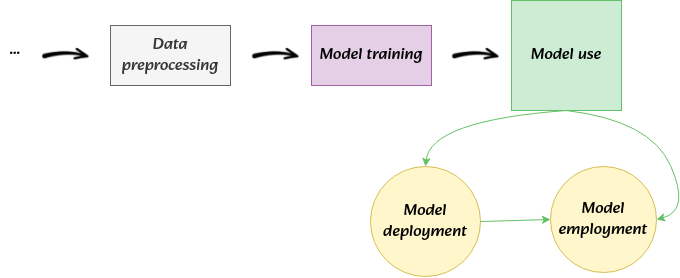
After finishing the training phase of our models, new stages of the whole modeling pipeline get activated. The most common one within the machine-learning community is model deployment. For those who are not familiar with the concept, this basically refers to placing the model somewhere. If you’ve read these posts about general machine-learning topics, you may remember the analogy of models with cars. When a car is built and assembled, “deployment” may be, for example, bringing it to car dealers’ shops. Another stage in this whole pipeline is model employment.
“Model employment”? Yes. This simply refers to everything that happens regarding the utility of our models. That includes making predictions, determining significant parameters, interpreting features, and the like. While this is a way of defining the practical uses of a model, the technical term for all of these is inference. Model employment may not necessarily follow its deployment. It will always depend on what use of the model is needed. However, it must and should always take place after model training, not during. While model deployment by definition requires placing the model somewhere, it hardly collapses or is confounded with training steps. This, unfortunately, is not always the case for model employment compromising correct inference.
The machine-learning community approach
A few decades ago, when the machine-learning community took a more solid shape, these concepts were well digested and easily put in practice by those who were diving into the practices of training models and using them to predict different things. To this day, not only we have infinite types of models around the world serving us in different ways, but the level of their complexity has increased so much that we’re very close to build that machine that will evolve our species like our friend ChatGPT. This level of complexity does not leave room for machine-learning pipelines to mix steps and for the people in charge not to differentiate the different stages. Thanks to that well-organized and separation of stages, we’re able to make more accurate predictions and trust the acquired inference from our models.
The classical statistics community approach
If you have taken any classical statistics course, you have dealt with estimating (training) many different types of models for the purpose of testing some hypotheses and finding the so-called significant differences of the features involved for a particular response variable. This was the legacy of the classical statistical paradigm by Fisher. In this type of practice, the model training phase has been completely confounded with the model employment phase. Yes, we do things like choosing the input features (training) based on their significance level (employment) both with the same data.

The whole spectrum in-between
As the level of complexity gets simpler, the reality has shown us that the separation between model training and employment becomes blurrier. Many data scientists out there deal with different levels of complexity when it comes to training and using models. Some models may be very simple to train and hard to employ, or vice-versa. If we were to audit machine-learning projects of low levels of complexity, it might well be the case that there’s no single object saving the model, no clear environment of deployment, and definitely not separated stage of employment particularly for interpretation or significance testing. We might find many models that live in forgotten folders as multiple lines of code that no one can easily understand with scattered pieces reporting figures of interest. Well, how problematic could this be?
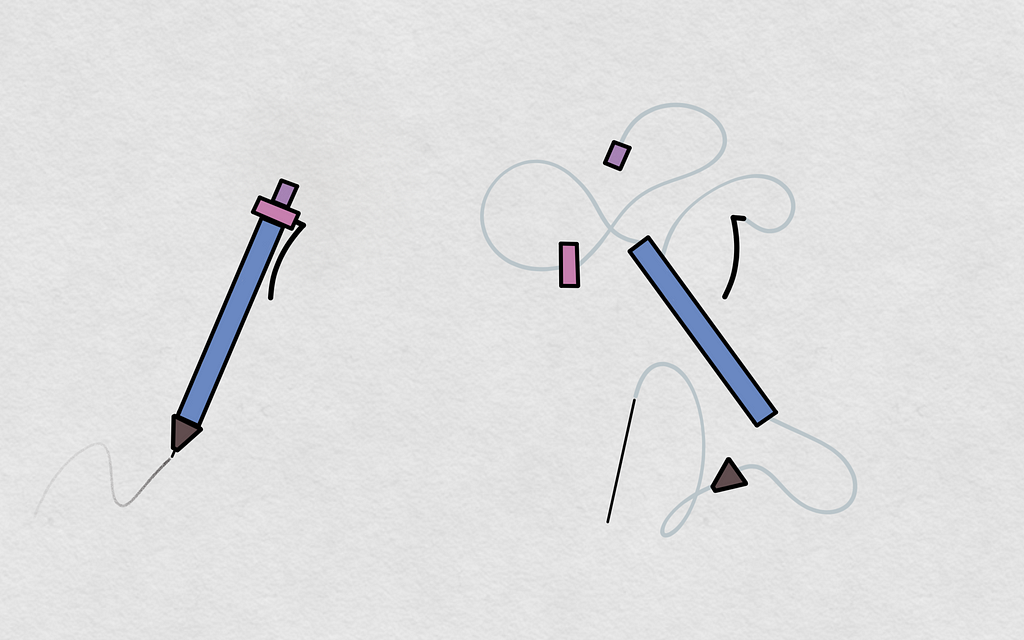
Our models need to be assembled tools
Yes, like a simple pencil or a complex device. Statistical models, from simple linear regressions to deep learning models, are tools. We build those tools for a purpose. That purpose may vary from field to field or application to application, but ultimately, they are meant to be employed for that purpose. When the employment phase is not detached from the training, we end up with models that look like scattered pieces that haven’t been assembled. When we report the employment or inference of our model based on a disassembled tool, the risk for misleading inference is rather high. It would be the same as writing with a disassembled pencil or driving a disassembled car. What sense could that make and why take the risk?
Smooth transition to a proper model employment
A successful model employment generally depends on having at least some form of model persistence. Even if your model is to live only locally, there will always be at least one user of that model: The researcher/data scientist or whoever will use the model to report the findings. Because there’s already at least one user, it is necessary to at least save the model in some available format. Once the save button is pressed or the save function is run, voilà! Your model now exists as an assembled tool.
Not any moment before you are ready to employ your model. When you are, here are a few beneficial/necessary practices:
- Separate the scripts for model training and model employment. A significance test to report inference should live in a separate script or software file from the estimation of the model.
- Methods for model employment should not be used for model training. Just as the prediction performance in the test set is not used to tune the model parameters, a significance test should not be used to select the input features if run on the same training data.
- Report the model training results separately from the model employment results. Because they are different stages, when we are to publish or report the results, the stages should also be reported separately.
Better model employment for all levels
I asked ChatGPT about model employment coming after model training and it said it was correct, generally. So, isn’t it always the case?. Well, the robot had a very good point. In online learning, the employment of the model produces feedback to update the model in time, so the tasks interact continuously. “That’s right!”. But wait, being connected through feedback is not the same as being confounded. The particular model training and employment interrelation in online learning is in itself a whole modeling scheme. Even there, there are clear definitions and approaches when it comes to the updating phase, the prediction phase, and the feedback flow. So, the conceptual separation remains valid.
Looking at our models and the practices around them when it comes to model training vs. model employment, it all boils down to organization and structure rather than modeling skills. Once we’re able to separate the stages of the modeling pipeline, our models should be able to persist as well as providing solid inference. Isn’t that our ultimate goal?
Let’s keep it up with good structure!
Model employment: The inference comes after training, not during was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/model-employment-the-inference-comes-after-training-not-during-6129efdf8e90?source=rss----7f60cf5620c9---4
via RiYo Analytics








No comments