https://ift.tt/SCl7MRo Learn how to develop a LangChain agent that has multiple ways of interacting with the Neo4j database Photo by Alex...
Learn how to develop a LangChain agent that has multiple ways of interacting with the Neo4j database

ChatGPT inspired the world and started a new AI revolution. However, it seems that the latest trend is supplying ChatGPT with external information to increase its accuracy and give it the ability to answer questions where the answers are not present in public datasets. Another trend around large language models (LLMs) is to turn them into agents, where they have an ability to interact with their environment through various API calls or other integrations.
Since enhancing LLMs is relatively new, there aren’t a lot of open-source libraries yet. However, it seems that the go-to library for building applications around LLMs like ChatGPT is called LangChain. The library provides the ability to enhance an LLM by giving it access to various tools and external data sources. Not only can it improve its responses by accessing external data, but it can also act as an agent and manipulate its environment through external endpoints.
I randomly stumbled upon a LangChain project by Ibis Prevedello that uses graph search to enhance the LLMs by providing additional external context.
The project by Ibis uses NetworkX library to store the graph information. I really liked his approach and how easy it was to integrate graph search into the LangChain ecosystem. Therefore, I have decided to develop a project that would integrate Neo4j, a graph database, into the LangChain ecosystem.
GitHub - tomasonjo/langchain2neo4j: Integrating Neo4j database into langchain ecosystem
After two weeks of coding, the project now allows a LangChain agent to interact with Neo4j in three different modes:
- Generating Cypher statements to query the database
- Full-text keyword search of relevant entities
- Vector similarity search
In this blog post, I will walk you through the reasoning and implementation of each approach I developed.
Environment setup
First, we will configure the Neo4j environment. We will use the dataset available as the recommendations project in the Neo4j sandbox. The easiest solution is simply to create a Neo4j Sandbox instance by following this link. However, if you would prefer a local instance of Neo4j, you can also restore a database dump that is available on GitHub. The dataset is part of the MovieLens datasets [1], specifically the small version.
After the Neo4j database is instantiated, we should have a graph with the following schema populated.
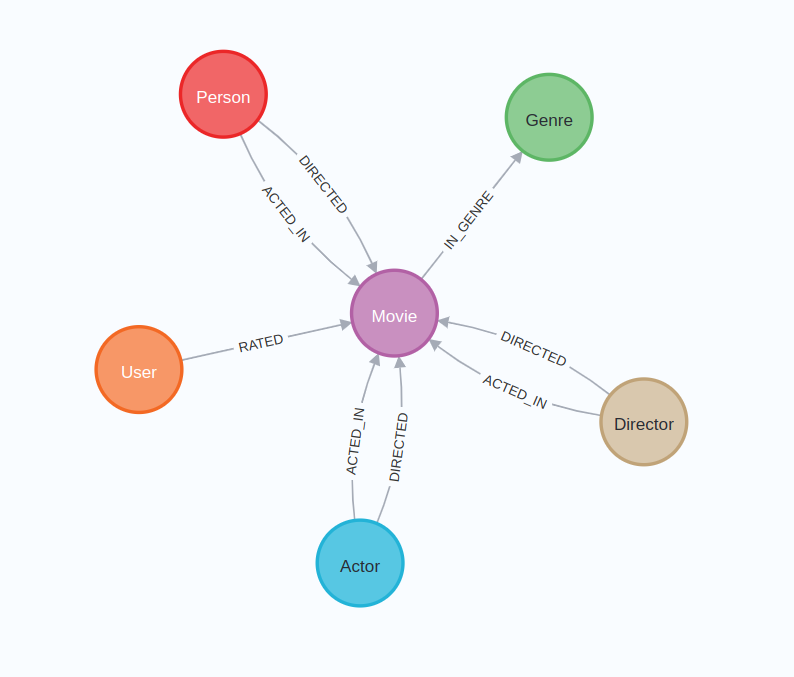
Next, you need to clone the langchain2neo4j repository by executing the following command:
git clone https://github.com/tomasonjo/langchain2neo4j
In the next step, you need to create an .env file and populate the neo4j and OpenAI credentials as shown in the .env.example file.
Lastly, you need to create a full-text index in Neo4j and import movie title embeddings by running:
sh seed_db.sh
If you are a Windows user, the seed_db script probably won’t work. In that case, I have prepared a Jupyter notebook that can help you seed the database as an alternative to the shell script.
Now, let’s jump to the LangChain integration.
LangChain agent
As far as I have seen, the most common data flow of using a LangChain agent to answer a user question is the following:
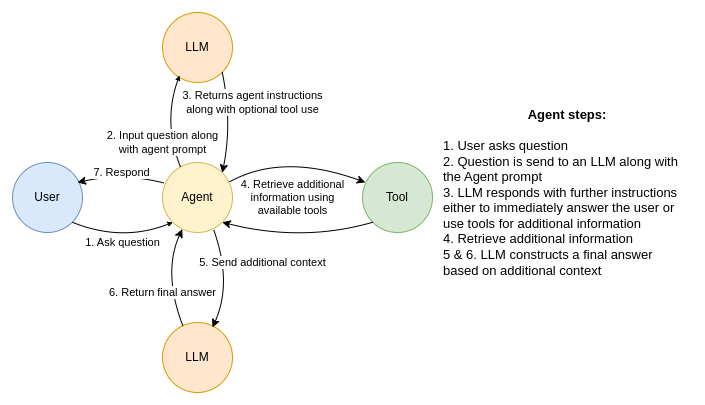
The agent data flow is initiated when it receives input from a user. The agent then sends a request to an LLM model that includes the user question along with the agent prompt, which is a set of instructions in a natural language the agent should follow. In turn, the LLM responds with further instructions to the agent. Most often, the first response is to use any available tools to gain additional information from external sources. However, tools are not limited to read-only operations. For example, you could use them to update a database. After the tool returns additional context, another call is made to an LLM that includes the newly gained information. The LLM now has the option to produce a final answer that is returned to a user, or it can decide it needs to perform more actions through its available tools.
A LangChain agent uses LLMs for its reasoning. Therefore, the first step is to define which model to use. At the moment, the langchain2neo4j project supports only OpenAI’s chat completion models, specifically GPT-3.5-turbo, and GPT-4 models.
if model_name in ['gpt-3.5-turbo', 'gpt-4']:
llm = ChatOpenAI(temperature=0, model_name=model_name)
else:
raise Exception(f"Model {model_name} is currently not supported")
I haven’t yet explored other LLMs besides OpenAI’s. However, with LangChain, it should be easy, as it has integration with more than ten other LLMs. I didn’t know that that many existed.
Next, we need to add a conversational memory with the following line:
memory = ConversationBufferMemory(
memory_key="chat_history", return_messages=True)
LangChain support multiple types of agents. For example, some agents can use the memory component, while others cannot. Since the object was to build a chatbot, I chose the Conversation Agent (for Chat Models) agent type. What is interesting about the LangChain library is that half the code is written in Python, while the other half is prompt engineering. We can explore the prompts that the conversational agent uses. For example, the agents has some basic instructions it must follow:
Assistant is a large language model trained by OpenAI. Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand. Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics. Overall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
Additionally, the agent has instructions to use any of the specified tools if needed.
Assistant can ask the user to use tools to look up information
that may be helpful in answering the users original question.
The tools the human can use are:
{format_instructions}
USER'S INPUT - - - - - - - - - -
Here is the user's input
(remember to respond with a markdown code snippet of a
json blob with a single action, and NOTHING else):
}}
Interestingly, the prompt states that the assistant can ask the user to look up additional information using tools. However, the user is not a human but an application built on top of the LangChain library. Therefore, the entire process of finding further information is done automatically without any human in the loop. Of course, we can change the prompts if needed. The prompt also includes the format the LLMs should use to communicate with the agent.
Note that the agent prompt doesn’t include that the agent shouldn’t answer a question if the answer is not provided in the context returned by tools.
Now, all we have to do is to define the available tools. As mentioned, I have prepared three methods of interacting with Neo4j database.
tools = [
Tool(
name="Cypher search",
func=cypher_tool.run,
description="""
Utilize this tool to search within a movie database,
specifically designed to answer movie-related questions.
This specialized tool offers streamlined search capabilities
to help you find the movie information you need with ease.
Input should be full question.""",
),
Tool(
name="Keyword search",
func=fulltext_tool.run,
description="Utilize this tool when explicitly told to use
keyword search.Input should be a list of relevant movies
inferred from the question.",
),
Tool(
name="Vector search",
func=vector_tool.run,
description="Utilize this tool when explicity told to use
vector search.Input should be full question.Do not include
agent instructions.",
),
]
The description of a tool is used to specify the capabilities of the tool as well as to inform the agent when to use it. Additionally, we need to specify the format of the input a tool expects. For example, both the Cypher and vector search expect a full question as an input, while the keyword search expects a list of relevant movies as input.
LangChain is quite different from what I am used to in coding. It uses prompts to instruct the LLMs to do the work for you instead of coding it yourself. For example, the keyword search instructs the ChatGPT to extract relevant movies and use that as input. I spent 2 hours debugging the tool input format before realizing I could specify it using natural language, and the LLM will handle the rest.
Remember how I mentioned that the agent doesn’t have instructions that it shouldn’t answer questions where the information is not provided in the context? Let’s examine the following dialogue.

The LLM decided that based on the tool descriptions, it cannot use any of them to retrieve relevant context. However, the LLM knows a lot by default, and since the agent has no constraints that it should only rely on external sources, the LLM can form the answer independently. We would need to change the agent prompt if we wanted to enforce different behavior.
Generating Cypher statements
I have already developed a chatbot interacting with a Neo4j database by generating Cypher statements using the OpenAI’s conversational models like the GPT-3.5-turbo and GPT-4. Therefore, I could borrow most of the ideas to implement a tool that allows the LangChain agent to retrieve information from the Neo4j database by constructing Cypher statements.
The older models like text-davinci-003 and GPT-3.5-turbo work better as a few-shot Cypher generator, where we provide a couple of Cypher examples that the model can use to generate new Cypher statements. However, it seems the GPT-4 works well when we only present the graph schema. Consequently, since graph schema can be extracted with a Cypher query, the GPT-4 can be theoretically used on any graph schema without any manual work required by a human.
I won’t walk you through what LangChain does under the hood. We will just look at the function that gets executed when the LangChain agents decides to interact with the Neo4j database using Cypher statements.
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
chat_prompt = ChatPromptTemplate.from_messages(
[self.system_prompt] + inputs['chat_history'] + [self.human_prompt])
cypher_executor = LLMChain(
prompt=chat_prompt, llm=self.llm, callback_manager=self.callback_manager
)
cypher_statement = cypher_executor.predict(
question=inputs[self.input_key], stop=["Output:"])
# If Cypher statement was not generated due to lack of context
if not "MATCH" in cypher_statement:
return {'answer': 'Missing context to create a Cypher statement'}
context = self.graph.query(cypher_statement)
return {'answer': context}
The Cypher generating tool gets the question along with the chat history as input. The input to the LLM is then combined by using the system message, chat history, and the current question. I have prepared the following system message prompt for the Cypher generating tool.
SYSTEM_TEMPLATE = """
You are an assistant with an ability to generate Cypher queries based off
example Cypher queries. Example Cypher queries are:\n""" + examples + """\n
Do not response with any explanation or any other information except the
Cypher query. You do not ever apologize and strictly generate cypher statements
based of the provided Cypher examples. Do not provide any Cypher statements
that can't be inferred from Cypher examples. Inform the user when you can't
infer the cypher statement due to the lack of context of the conversation
and state what is the missing context.
"""
Prompt engineering feels more like art than science. In this example, we provide the LLM with a couple of Cypher statement examples and let it generate Cypher statements based on that information. Additionally, we place a couple of constraints, like allowing it to construct only Cypher statements that could be inferred from training examples. Additionally, we don’t let the model apologize or explain its thoughts (however, GPT-3.5-turbo won’t listen to that instructions). Finally, if the question lacks context, we allow the model to respond with that information instead of forcing it to generate Cypher statements.
After the LLM construct a Cypher statements, we simply use it to query a Neo4j database, and return the results to the Agent. Here is an example flow.
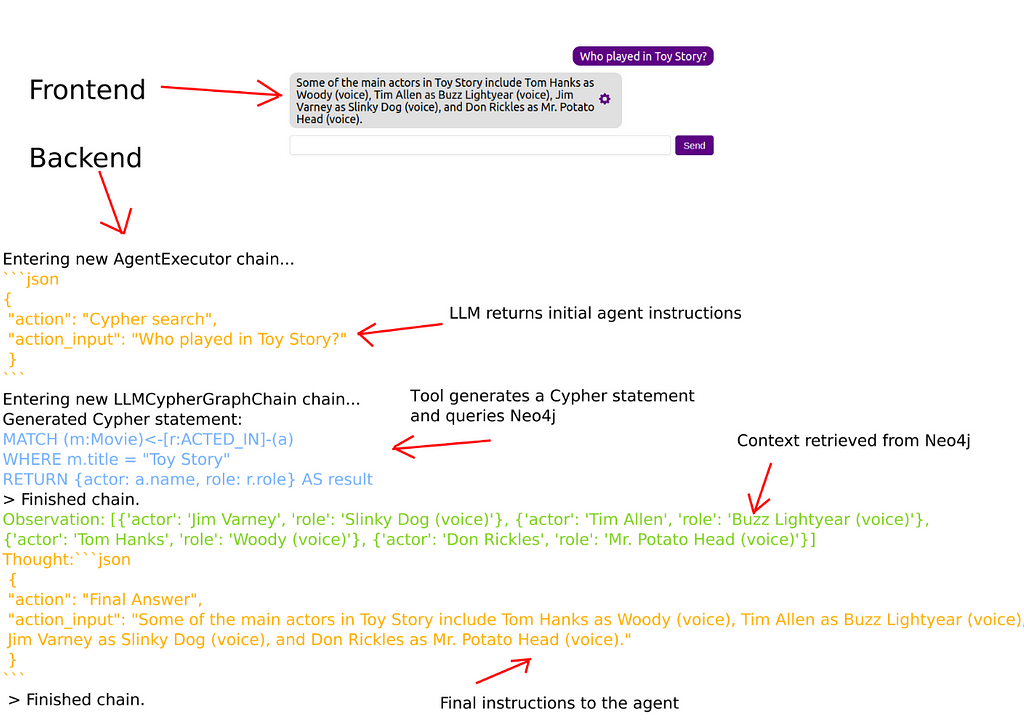
When a user inputs their question, it gets sent to an LLM along with the agent prompt. In this example, the LLM responds that it needs to use the Cypher search tool. The Cypher search tool constructs a Cypher statement and uses it to query Neo4j. The results of the query are then passed back to the agent. Next, the agent sends another request to an LLM along with the new context. As the context contains the needed information to construct an answer, the LLM forms the final answer and instructs the agent to return it to the user.
Of course, we can now ask follow up questions.

Since the agent has memory, it is aware of who is the second actor and, therefore, can pass the information along to the Cypher search tool to construct appropriate Cypher statements.
Keyword search of relevant triples
I got the idea for keyword search from existing knowledge graph index implementations in both LangChain and GPT-index libraries. Both implementations are fairly similar. They ask an LLM to extract relevant entities from a question and search the graph for any triples that contain those entities. So I figured we could do something similar with Neo4j. However, while we could search for entities with a simple MATCH statement, I have decided that using Neo4j’s full-text index would be better. After relevant entities are found using the full-text index, we return the triples and hope the relevant information to answer the question is there.
def _call(self, inputs: Dict[str, str]) -> Dict[str, Any]:
"""Extract entities, look up info and answer question."""
question = inputs[self.input_key]
params = generate_params(question)
context = self.graph.query(
fulltext_search, {'query': params})
return {self.output_key: context}
Remember, the agent has instructions to parse out relevant movie titles already and use that as input to the Keyword search tool. Therefore, we don’t have to deal with that. However, since multiple entities could exist in the question, we must construct appropriate Lucene query parameters as the full-text index is based on Lucene. Then, we simply query the full-text index and return hopefully relevant triples. The Cypher statement we use is the following:
CALL db.index.fulltext.queryNodes("movie", $query)
YIELD node, score
WITH node, score LIMIT 5
CALL {
WITH node
MATCH (node)-[r:!RATED]->(target)
RETURN coalesce(node.name, node.title) + " " + type(r) + " " + coalesce(target.name, target.title) AS result
UNION
WITH node
MATCH (node)<-[r:!RATED]-(target)
RETURN coalesce(target.name, target.title) + " " + type(r) + " " + coalesce(node.name, node.title) AS result
}
RETURN result LIMIT 100
So, we take the top five relevant entities returned by the full-text index. Next, we generate triples by traversing to their neighbors. I have specifically excluded the RATED relationships from being traversed because they contain irrelevant information. I haven’t explored it, but I have a good feeling we could also instruct the LLM to provide a list of relevant relationships to be investigated along with the appropriate entities, which would make our keyword search more focused. The keyword search can be initiated by explicitly instructing the agent.

The LLM is instructed to use the keyword search tool. Additionally, the agent is told to provide the keywords search a list of relevant entities as input, which is only Pokemon in this example. The Lucene parameter is then used to query Neo4j. This approach casts a broader net and hopes the extracted triples contain relevant information. For example, the retrieved context includes information on the genre of Pokemon, which is irrelevant. Still, it also has information about who acted in the movie, which allows the agent to answer the user’s question.
As mentioned, we could instruct the LLM to produce a list of relevant relationship types along with appropriate entities, which could help the agent retrieve more relevant information.
Vector similarity search
The vector similarity search is the last mode to interact with a Neo4j database we will examine. Vector search is trendy at the moment. For example, LangChain offers integrations with more than ten vector databases. The idea behind vector similarity search is to embed a question into embedding space and find relevant documents based on the similarity of the embeddings of the question and documents. We only need to be careful to use the same embedding model to produce the vector representation of documents and the question. I have used the OpenAI’s embeddings in the vector search implementation.
def _call(self, inputs: Dict[str, str]) -> Dict[str, Any]:
"""Embed a question and do vector search."""
question = inputs[self.input_key]
embedding = self.embeddings.embed_query(question)
context = self.graph.query(
vector_search, {'embedding': embedding})
return {self.output_key: context}
So, the first thing we do is embed the question. Next, we use the embedding to find relevant movies in the database. Usually, the vector databases return the text of a relevant document. However, we are dealing with a graph database. Therefore, I have decided to produce relevant information using the triple structure. The Cypher statement used is:
WITH $embedding AS e
MATCH (m:Movie)
WHERE m.embedding IS NOT NULL AND size(m.embedding) = 1536
WITH m, gds.similarity.cosine(m.embedding, e) AS similarity
ORDER BY similarity DESC LIMIT 5
CALL {
WITH m
MATCH (m)-[r:!RATED]->(target)
RETURN coalesce(m.name, m.title) + " " + type(r) + " " + coalesce(target.name, target.title) AS result
UNION
WITH m
MATCH (m)<-[r:!RATED]-(target)
RETURN coalesce(target.name, target.title) + " " + type(r) + " " + coalesce(m.name, m.title) AS result
}
RETURN result LIMIT 100
The Cypher statement is similar to the keyword search example. The only difference is that we use cosine similarity instead of a full-text index to identify relevant movies. This approach is good enough when dealing with up to tens of thousands of documents, maybe hundreds of thousands. Remember, the bottleneck is usually LLM, especially if you use GPT-4. Therefore, if you are not dealing with millions of documents, you don’t have to think of polyglot implementations where you have both a vector and a graph database to be able to produce relevant information by traversing the graph.

When an agent is instructed to use the vector search tool, the first step is to embed the question as a vector. The OpenAI’s embedding model produces vector representations with a dimension of 1536. So, the next step is to use the constructed vector and search for relevant information in the database by calculating the cosine similarity between the question and relevant documents or nodes. Again, since we are dealing with a graph database, I have decided to return the information to the agent in the form of a triple.
What is interesting about vector search is that even though we instructed the agent to search for the Lord of the Ring movies, the vector similarity search also returned information about the Hobbit movies. It looks like that Lord of the Ring and Hobbit movies are close in the embedded space, which is understandable.
Summary
It looks like chatbots and generative agents that can access external tools and information are the next wave that follows the original ChatGPT hype. Having the ability to provide additional context to an LLM can greatly improve its results. Additionally, the agent’s tools are not restricted to read-only operations, which means they can update a database or even make orders on Amazon. For the most part, it seems that the LangChain library is the primary library at the moment to be used to implement generative agents. When you start using LangChain, you might need a bit of a shift in the coding process, as you need to combine LLM prompts with code to complete tasks. For example, messages between LLMs and tools can be shaped and reshaped with natural language instructions as prompts instead of Python code. I hope this project will help you implement the capabilities of a graph database like Neo4j into your LangChain project.
As always, the code is available on GitHub.
References
[1] F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872
Integrating Neo4j into the LangChain ecosystem was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/integrating-neo4j-into-the-langchain-ecosystem-df0e988344d2?source=rss----7f60cf5620c9---4
via RiYo Analytics






ليست هناك تعليقات