https://ift.tt/b0imPny The Blueprint for Creating Effective Data Products Data As a Product — Image courtesy of Castor The data-as-a-p...
The Blueprint for Creating Effective Data Products
The data-as-a-product approach has recently gained widespread attention, as companies seek to maximize data value.
I’m convinced the data-as-a-product approach is the revolution we need for creating a better Data Experience, a concept held dear to my heart.
A few words on the Data Experience, in case you need to catch up:
Data used to be the realm of technical teams. Not anymore. Today, data powers all the operational functions within a company: sales, finance, marketing, ops, and more.
Business users have become data users and their experience is the Data Experience. The Data Experience is how these domain experts feel when they use data daily to superpower their job.
As of today, the Data Experience is not a good one. Even when we manage to produce high-quality data, it is still hard to find, access, and understand. A poor data experience causes business teams to mistrust the data and lose interest in it. What’s the use of collecting data if it doesn’t lead to better decision-making?
The data-as-a-product approach is simple, yet effective. It involves a change in mindset where data users are seen as customers, highlighting the need to prioritize their satisfaction. By starting with better conceptualization and presentation, it strives to offer an exceptional Data Experience. While we’ll explore this approach in more detail later, the key takeaway is that treating data like a product means putting data consumers first.
How do we make this shift in practice? To implement a data-as-a-product approach, you need to change your approach to generating and serving data. That is, you need to apply a product management mindset before producing the data and throughout the lifespan of the data. It’s not uncommon for companies who want to treat their data like a product to focus on one aspect but neglect the other.
This article takes you through these steps, in two parts:
- Leveraging Product Management Mindset in Data Creation
- Applying Product Management to Data Presentation and Delivery
Throughout this article, the terms “data product” and “data-as-a-product” will be used interchangeably to refer to data being treated as a product.
I. Leveraging a Product Management Mindset in Data Creation
The idea of data-as-a-product begins at the very foundation — your mindset. It is crucial not only to understand but also to embed data-as-a-product thinking throughout your entire organization.
Treating data as a product means applying the same principles and practices used in traditional product development to your data initiatives.
So what does treating data as a product actually mean in real life? Eric Broda explains that data products come from bringing product thinking to data domains, as illustrated in the image below.
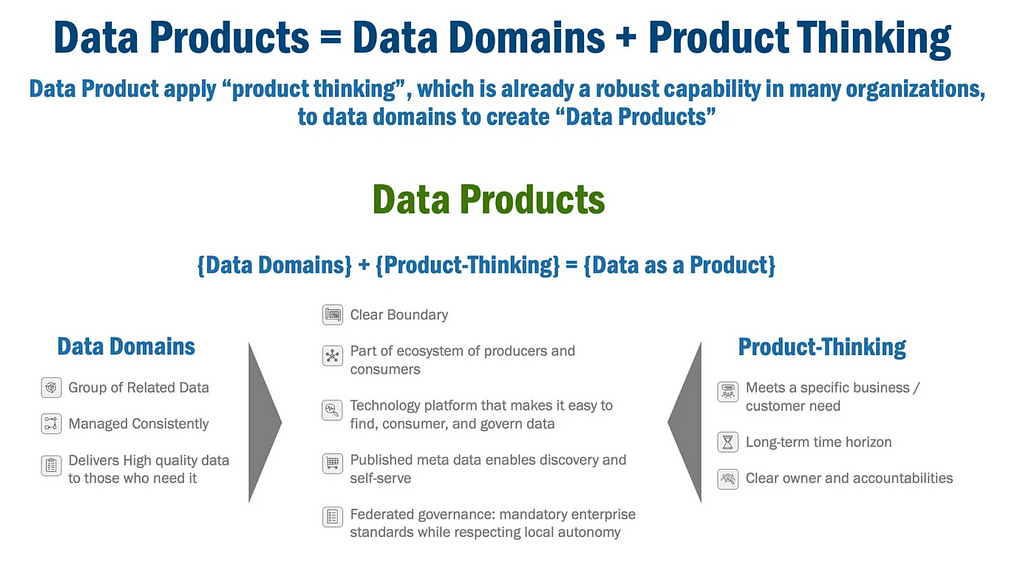
A real-life product:
- Is assigned to a clear owner for product development and management.
- Adheres to specific business and customer needs, tailored to a specific purpose and target audience.
- Developed with a long-term perspective, with the product owner creating a plan for sustained improvement and success.
What does this mean in practice?
William Angel, the Sr. Technical Product Manager for Data Engineering at Caribou, suggests that when approaching analytics with a product management mindset, it is important to allocate additional time during the data creation phase. Rather than jumping straight into building a dashboard or predictive model, it is crucial to first consider WHO will be using it and HOW it will be valuable for them.
“A lot of people think this approach comes naturally when building a project. But a lot of the time, the cart gets put before the horse and we use models because of their accuracy and not of their business impact.” William Angel, Sr. Technical Product Manager for Data Engineering
By taking a product management mindset, however, one can ensure that the analytics being created will have real value for the business and its users.
Adopting a product management mindset prior to data creation marks the initial stage towards providing dependable data products. However, that alone is NOT sufficient. In real life, once a product is created, it then needs to be packaged and presented to customers. This is the subject of the next section.
II. Applying Product Management to Data Presentation and Delivery
A lot of organizations bring product management thinking at the data production stage, and then stop worrying about the data. But if you’re thinking of data as a product, you have to think about the whole lifecycle of the data.
Let’s think about the lifecycle of physical products. A physical product is created, used, and eventually thrown away. If you are creating this product sustainably, you want to think about this whole lifecycle and plan for the safe usage, storage and eventual disposal of the product at the end of its lifecycle. Again, what does it means in the context of data?
“When it comes to data, one must consider how to store and document it, as well as how it will be utilized.” William Angel, Sr. Technical Product Manager for Data Engineering
There are specific characteristics that should be considered to ensure that data products are effectively managed and utilized. These characteristics are well known from Zhamak Dehghani’s work on the data mesh. We briefly cover them here and explain how they can be brought about in practice.
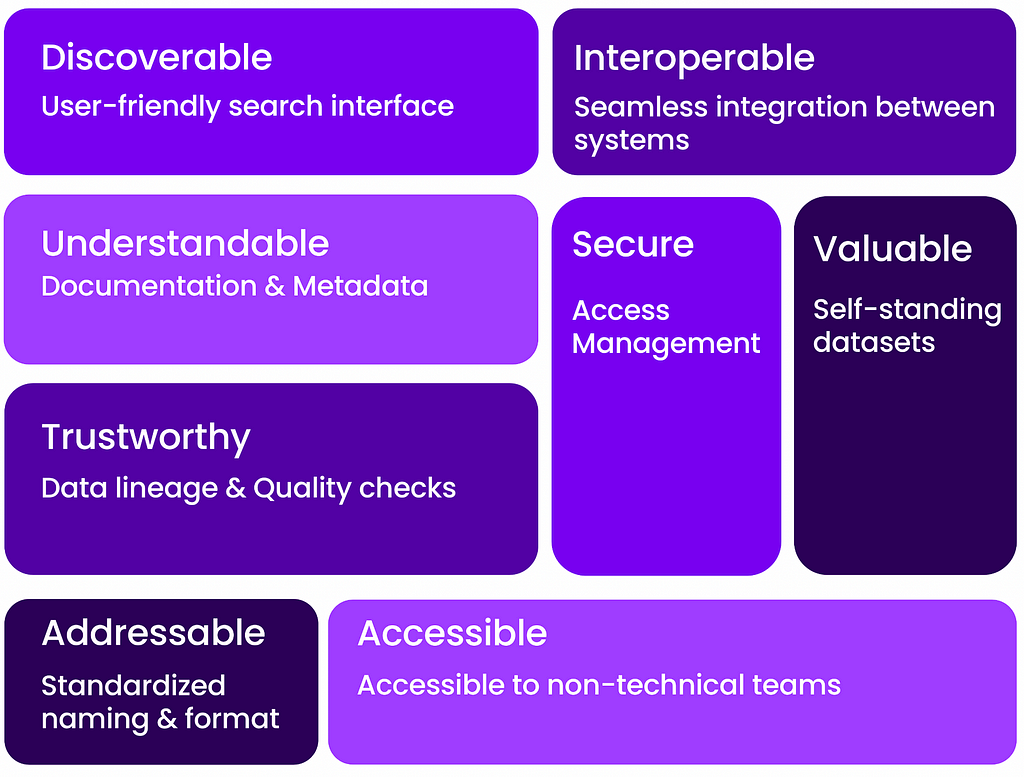
Discoverable
The first characteristic of reliable data products is discoverability. A good indication that data is “discoverable” is when the data team stops being treated like a data catalog. That is, when data consumers can find answers to their data questions autonomously.
This means everyone in the company knows where and how to find the best data for their specific project. Even if the data is messy. Even if there are 20 tables bearing the same name.
So what does “good” look like? Data is discoverable when teams can easily navigate across the mess, and identify effortlessly which are the most popular and up-to-date tables without asking their colleagues or boss.
You have two kinds of stakeholders looking for data: those searching for a specific dataset, and those browsing the documentation to get an overview of your data landscape. Data should be discoverable for both.
The easiest way to ensure this is to plug a data catalog on top of your data stack , enabling easy searching and exploration. If you don’t have a data catalog in place, your data documentation might be scattered across different tools:
- Wiki pages for general knowledge and onboarding
- Code repository for descriptions and tags (if you use code annotations)
- JIRA or Gitlab to manage issues and requests
- Slack channels for tribal knowledge
Even if you can’t merge those with a data catalog just yet, you can at least craft a homepage, gathering all useful links.
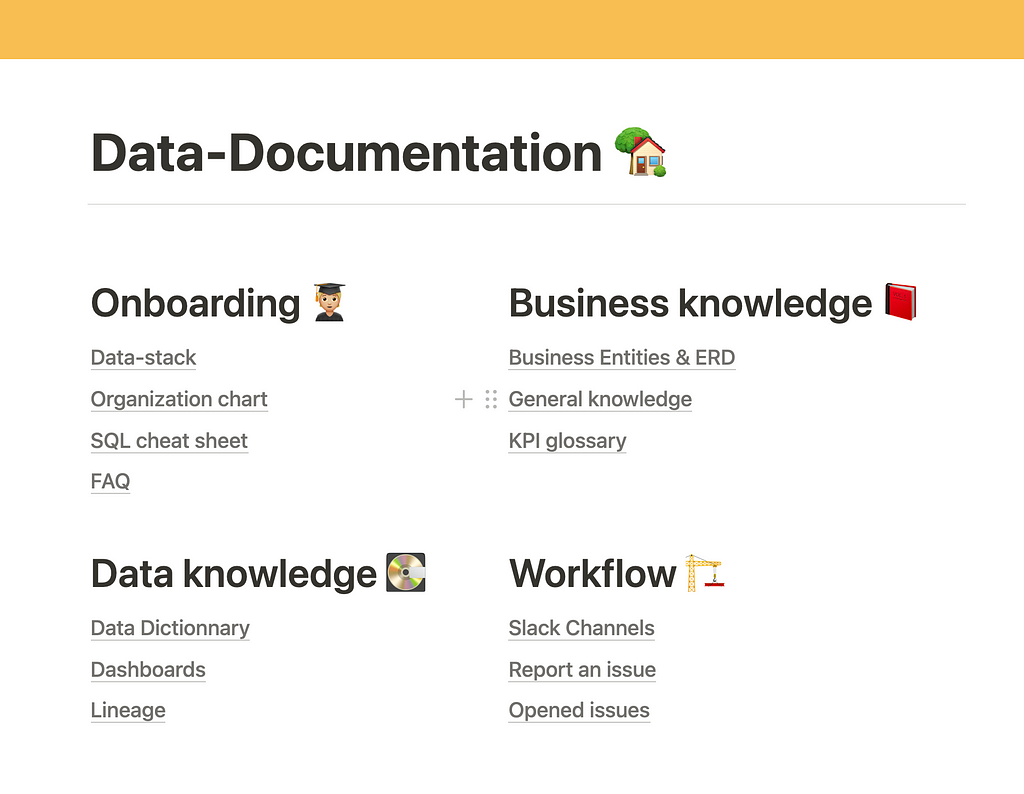
Understandable
People understand a dataset when they are aware of the needs this data will satisfy, its content, and its location. Data without context is worthless & dangerous. Once you have found the relevant dataset, you did 10% of the job. Now you need to go through a checklist of questions to make sure you understand what data you are using. If you can’t answer the following questions, you don’t understand your data.
- Where does the data come from?
- Where does it flow and which tables does it feed downstream?
- Who owns it / who is responsible for it?
- What is the meaning of a given field in my domain?
- Why does it matter?
- When was the last time this table was updated?
- What are the upstream and downstream dependencies of this data?
- Is this production-quality data?
People can truly understand the data when all the relevant knowledge is tied to it. Understanding is subjective. An ML engineer will approach a dataset differently than a data analyst. This is why all understanding goes through tying all the relevant knowledge layers to a dataset.
Applying good documentation principles essentially means enriching your data with the right context. As mentioned above, traditional documentation helps data users understand the purpose of a dataset and the meaning of its fields. On top of this, you can assign a dataset owner in a visible way, allowing data users to know who is responsible for a given data set.
Finally, data lineage is the process of tracking the history of data as it flows through a series of transformations, such as data extraction, cleaning, enrichment, and storage. It helps to understand the origins, transformations and dependencies of data elements in an organization. Lineage capabilities help data users answer questions such as “What are the upstream and downstream dependencies of this data?”.
Trustworthy
The data product should be reliable and trustworthy. Stakeholders should be confident in its usability.
Data trust can be achieved by providing complete transparency around data usage and data provenance through strong lineage capabilities. It helps to understand the origins, transformations and dependencies of data elements in an organization. Lineage help data users answer questions such as “What are the upstream and downstream dependencies of this data?”
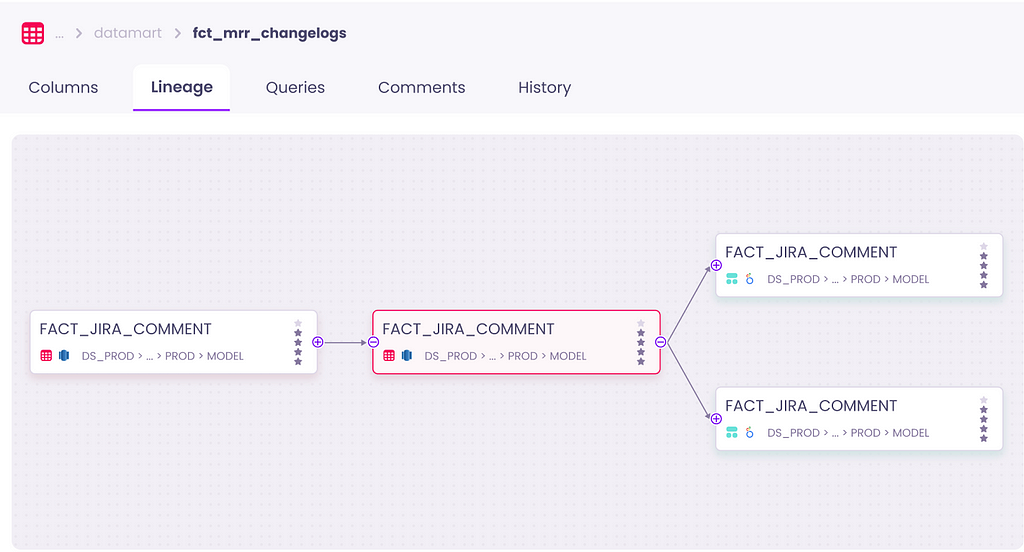
Another way to bring trust about is to build transparency around what people in your company are doing with the data. This allows employees to learn from experts’ best practices.
When people know that trusted colleagues have queried and used the data, they can better infer that this dataset is trustworthy. Obtaining social validation that the data is valuable goes a long way toward building data trust.
Another way to close the trust gap is to adhere to an approved data product’s SLAs:
- Interval of change and timeliness
- Completeness
- Freshness, general availability, and performance
This basically refers to data quality checks that the data must pass. These checks can be performed manually or through automated tools and involves verifying the data against a set of defined rules or standards to ensure it meets the required quality standards. Making these quality checks accessible for each dataset goes a long way for helping users understand the data.
Addressable
The data product should have a unique identifier or address that allows it to be easily accessed and used.
Addressability of a data product means giving it a unique, easy-to-find location where it can be accessed by others. Think of it like a street address for a house. Just as you need a specific address to find a house, a data consumer needs a unique address to access your data product.
The address should follow a set of rules and standards, so that everyone can find it easily and use it in the same way, regardless of who they are or what system they’re using. This makes it easy for people to find, use, and understand your data product.
Accessible
When data products are referred to as “accessible,” it means that they can be easily obtained or reached by users. This could mean that the data is readily available for use, or that the process for obtaining the data is simple and convenient for the user.
If you’re going to provide data context, you should do it through the right interface. Not all team members have the same level of technical expertise and not all teams have the same data needs.
For example, if you are documenting your data in dbt, you cannot expect the marketing team to fetch the documentation there. Context should be made available in tools that are user-friendly for business teams.
Secure
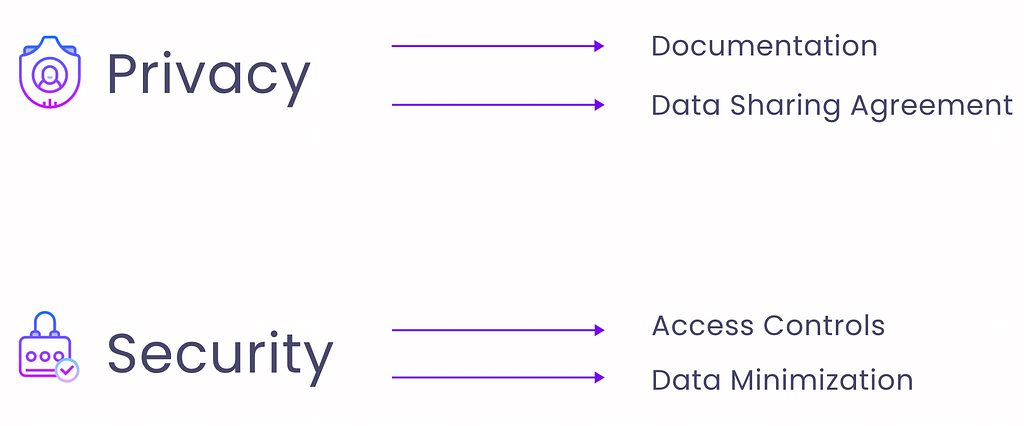
It’s no surprise that data products must be secure to protect sensitive information. Regardless of how data is treated, security is always a concern. However, it becomes extra challenging for data products, as they must be both discoverable and accessible. How can you make them accessible while enforcing strong security measures?
Managing privacy and security risks can be achieved by implementing a few key strategies. To protect personal information, it is important to invest in proper documentation and establish clear data-sharing agreements. Additionally, implementing access controls and adhering to data minimization practices can help mitigate security risks and ensure the safety of sensitive information. These strategies would take a full article to explain. Luckily, we wrote one.
Interoperable
The data product should be compatible with other data products and systems, allowing for seamless integration. Being interoperable means that different data products can work together and talk to each other without any problems.
They can share information and be used together, even if they’re created by different people or organizations. This makes it easier for people to use and benefit from the information contained in these data products.
To make sure your data products work well with others, you need to follow the following steps:
- Use common and well recognized standards for data format and structure.
- Use open data formats that others can easily use.
- Write clear instructions and information about your data product so others know how to use it correctly.
- Use clear names for your data, so others can easily understand what the data means.
- Test your data product with other systems to make sure it works well.
Valuable on its own
The data product should provide value to the user, even without being combined with other data products.
Data products must be valuable on their own because if they’re not, people won’t use them. Just having data isn’t enough — it needs to offer real value to the user. This value could come in the form of insights, knowledge, or solutions to problems.
To make data products valuable, the Data Product Manager (DPM) needs to focus on what the user wants and needs. When designing data products, the DPM should try to figure out what the user is trying to solve and then design a solution around that problem. Aligning data producers with business strategy is the best way to ensure the data provides insights to consumers.
Conclusion
To create a data-as-a-product approach, you need to shift your mindset and view data as a product that needs to be produced, packaged, and served to customers.
This requires a new way of producing data within your company. In fact, data products are the result of bringing product thinking to data domains. Real-life products are user-centered and have a clear owner. These two components from product management should be brought to data domains to build reliable data products.
But applying a product management mindset should not stop at the production stage. The second step in delivering high-quality data products is to package and present the data, ensuring that it is enriched with the right context for people to find, understand, and trust it. By following these steps, you can turn data into a valuable asset that drives business decisions and improves the overall Data Experience.
About us
We write about all the processes involved when leveraging data assets: the modern data stack, data teams composition, and data governance. Our blog covers the technical and the less technical aspects of creating tangible value from data.
At Castor, we are building a data documentation tool for the Notion, Figma, Slack generation.
Want to check it out? Reach out to us and we will show you a demo.
Originally published at https://www.castordoc.com.
Data as a Product: From Concept to Reality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/data-as-a-product-from-concept-to-reality-b2a853712250?source=rss----7f60cf5620c9---4
via RiYo Analytics






No comments