https://ift.tt/FW5gETU Guiding Large Language Models towards Task-Specific Inference — Prompt Design and Soft Prompts Discover how prompt ...
Guiding Large Language Models towards Task-Specific Inference — Prompt Design and Soft Prompts
Discover how prompt designs and soft prompts are being used to develop and deploy SOTA models.

Prompting is the process of providing additional information for a trained model to condition while predicting output labels for a task. This is done through prompts which are a few lines of instructions input to the model to perform a certain task with or without a few examples.
Recently, with the success of large transformer models such as GPT-2 and GPT-3, prompts are getting a lot of attention. With GPT-2, OpenAI showed that scaling large models can comparatively improve their task-specific performance without having to update their model weights on downstream tasks. While with GPT-3, they showed that a prompt describing the required task to be performed along with zero to few samples of the outcome was enough for these large models to perform the task successfully. This gave rise to Prompt Engineering where the aim is to carefully curate these input prompts that can extract the best possible results from the model. Building on top of this, researchers at Google recently introduced Prompt Tuning where the idea is to learn Soft Prompts that can guide Large Language Models (LLMs) to perform various tasks. These prompts are trained weights that once tuned, can be fed to a frozen language model along with the input to obtain the required results.
Background
There’s been an increasing trend toward pre-training language models to create task-agnostic language representations which can be flexibly adapted to perform specific tasks through task-specific datasets and architecture. A relevant example would be google’s BERT, which has a multi-layer bidirectional Transformer encoder and is pre-trained on an unlabelled dataset using Masked LM and Next Sentence Prediction (NSP). The model then has to be finetuned on downstream tasks using labeled data to update its parameters. A distinctive aspect of BERT is the ability to bypass the need for task-specific architecture by using a unified architecture across both pre-training and finetuning:
The pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. — BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
An obvious drawback to this is the need for task-specific datasets and finetuning methods which limits the model’s applicability. When faced with the need to utilize a trained LM for specific tasks, researchers/developers often find themselves engaged with the tumultuous task of acquiring a large amount of task-specific labeled data, which would have to be repeated for every new task. Moreover, research has shown that large finetuned models can be overly specific to the training distribution and struggle to generalize well out-of-distribution and causing issues with domain shift. This is mostly attributed to the discrepancy in the amount of data that it is trained on during the pretraining and the finetuning process.
1. Programming with plain text — Prompt Design
Multitask learning has always been a promising framework to overcome these limitations and improve the model’s general performance. One of the most prominent approaches toward achieving this has been meta-learning in which the model is taught to perform several tasks during training such that it develops a wide range of skills and pattern recognition abilities that can be leveraged during inference to generate the desired output. With the introduction of transformers, GPT2 showed that this can be achieved by learning a conditional probability of p(output | input, task) making them multi-task learners. Though there have been several similar pieces of research along these lines, such as MAML(Model Agnostic Meta-Learning) and MQAN(Multitask Question Answering Network), the ability of transformers to scale and the availability of huge volumes of data has made it possible for researchers to develop task-agnostic models that could perform at par with existing finetuned models. In addition, MQAN showed that the nature of common NLP tasks provides the flexibility to translate them into a question-answering task with instructions on how to perform each task. This is one of the
While GPT2 showed that large models can be multi-task learners, GPT3, which differs from the former mostly in the model size, data size and diversity, and training time, showed that it is possible to improve large LMs on downstream tasks in a few-shot setting, specified via text interactions, without any gradient updates or finetuning. This saves the need to train, store and deploy different task-specific models. Few-shot(K) here implies that the model requires only a few demonstrations of the required task with K ranging from 0 to the maximum that can be accommodated by the model’s token limit. To contrast the difference in performance based on K, figure 1 shows the model’s accuracy on the LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects) benchmark dataset. The aim of this benchmark is to evaluate the model’s capability to understand paragraphs of text by asking it to predict the most likely word at the end of a paragraph. This can also be used to indirectly measure the model’s ability to capture long-range dependencies. For more on GPT-3’s performance on various language modeling benchmarks, refer to its original paper here.
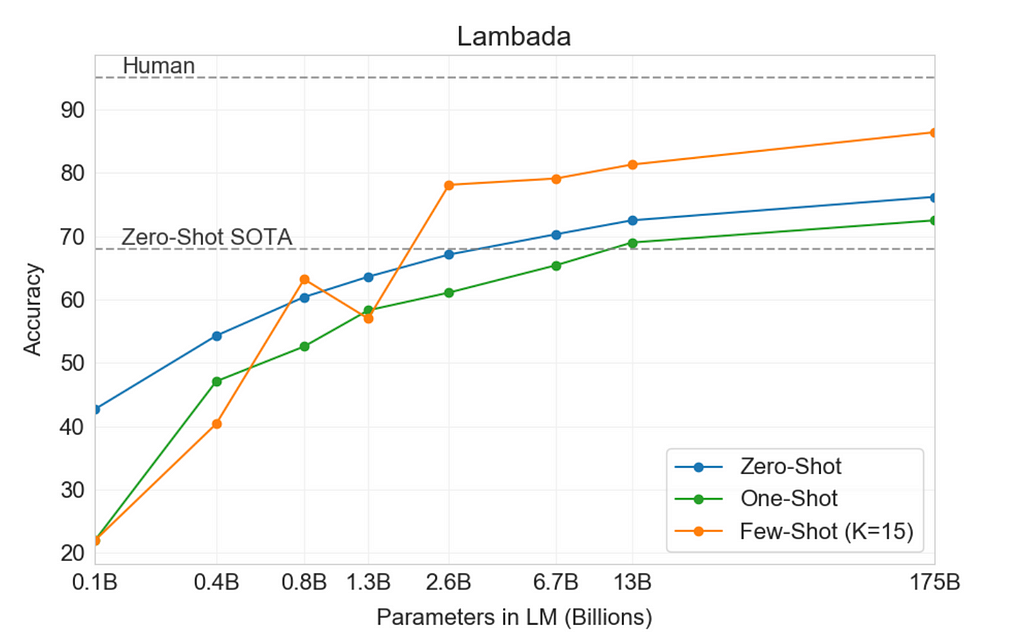
Unfortunately, prompt design also falls victim to some key shortcomings. The quality of model performance is often a function of task descriptions and is limited by the amount of conditioning text that can fit into the model’s input. Building a high-quality prompt requires human involvement and involves running multiple experiments with several prompt designs for each task. Although there have been attempts (such as AutoPrompt) to automate prompt generation and tools (eg. promptsource) available to streamline the process, the performance often falls behind SOTA.
2. Learnable prompts — Prompt Tuning
Another technique, introduced by Google and building on top of their text-to-text T5 LM, is to train a bunch of task-specific tokens that can be attached to a frozen LM’s model input tokens. Prompt tuning is the process of learning tunable tokens of size k per downstream task which can be prepended to the input text. This is an efficient method for conditioning frozen models as it can achieve comparable performances to SOTA (as the model scales) even with smaller model sizes, however, as opposed to prompt design, they still need task-specific datasets to train these prompts.
While embeddings for the input tokens used in prompt design come from the model’s own embedding space, token embeddings used in prompt tuning are separately learned from task-specific datasets. In addition, instead of updating the model weights as in model tuning, this method only updates the prompt weights while keeping the model weights frozen.
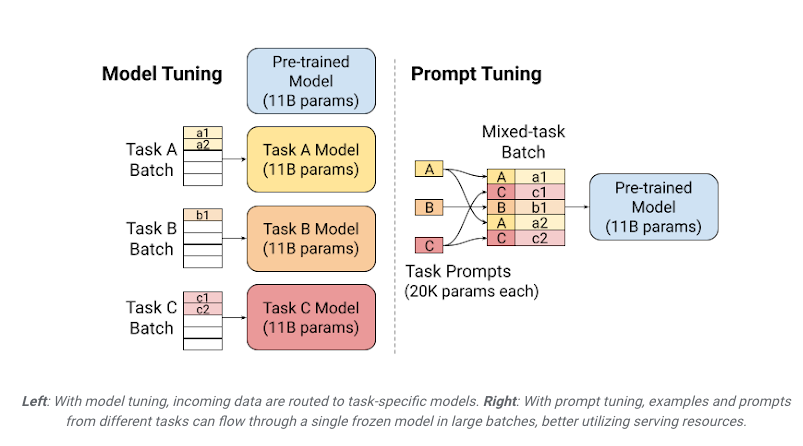
As shown in figure 2, this further makes it possible to save resources through batching and vectorization. Learnt task prompts can be attached to various task inputs to create a multi-task batch that can be passed to the same frozen model.
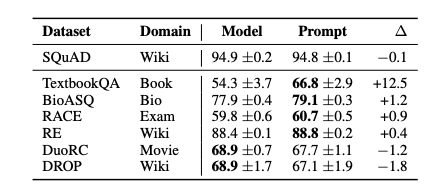
Another advantage of prompt tuning is its ability to modulate the model’s input representations thereby preventing the model from modifying its learned general understanding of language. They argue that this would help the model overcome out-of-distribution errors when used with such datasets. To substantiate this, the researchers investigated the zero-shot domain transfer performance of prompt tuning on Question Answering and paraphrase detection. The prompts were trained on SQuAD and the results showed prompt tuning to outperform model tuning on most of the common out-of-domain datasets (Figure 3. For detailed results breakdown, refer to the paper here). This shows that training lightweight prompts in place of heavy-duty models can yield better performance at a lesser cost of compute and memory on out-of-domain tasks.
Since soft prompts can be used to influence a model’s embedding space respective to the downstream tasks, they provide an efficient way to ensemble huge LMs without the associated overhead. A method to improve task performance is to use an ensemble of finetuned models with different initializations but trained on the same data. This can be done efficiently with soft prompts as it is now possible to create N separate prompts with different initializations instead of N finetuned models. The previously discussed idea of batching and vectorization can be used here as well to obtain the results through a single pass through the frozen LM.
The paper further reports the results of the ablation study conducted to investigate how variations in the prompt length, its method of initialization, and choice of pre-training objective can influence the performance of prompt tuning so I’d highly recommend reading the paper to know more.
Key takeaways:
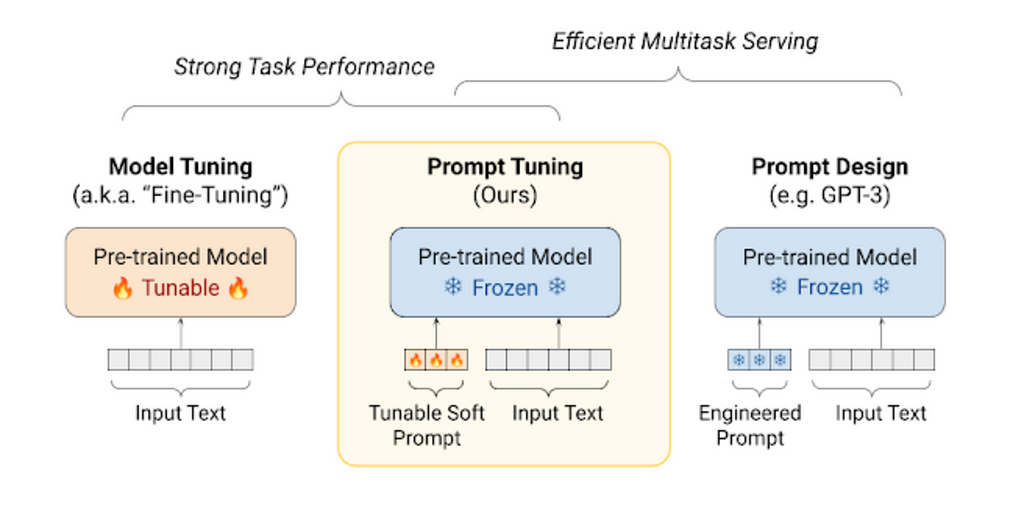
- Model Tuning involves updating the weights of a task-agnostic pre-trained LM on downstream tasks with/without updates to the underlying architecture. Therefore each application can only be served by its own models and they perform quite poorly on out-of-distribution examples.
- Prompt Design works on huge LMs which consider each NLP task to be a form of QA problem and the output label is often a series of tokens. By freezing the model weights they are capable of quick task adaptations through few-shot prompts, however, since the prompt texts are mostly manually created, the quality of the output depends on the quality of the input prompts and task description.
- Instead of updating the model weights, Prompt Tuning involves training a vector of tokens separate from the model’s embedding space that can modulate the model’s embeddings based on the task at hand. The prompts can be batched along with task-specific inputs and fed to a frozen model. This method shows strong resilience to domain shift and can efficiently replace neural network ensembling.
References:
- GPT 2: Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
- GPT 3: Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.
- MAML: Finn, Chelsea, Pieter Abbeel, and Sergey Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” International conference on machine learning. PMLR, 2017.
- MQAN: McCann, Bryan, et al. “The natural language decathlon: Multitask learning as question answering.” arXiv preprint arXiv:1806.08730 (2018).
- Prompt Tuning: Lester, Brian, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning.” arXiv preprint arXiv:2104.08691 (2021).
Guiding Large Language Models towards task-specific inference — Prompt Design and Soft Prompts was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/guiding-a-huge-language-model-lm-to-perform-specific-tasks-prompt-design-and-soft-prompts-7c45ef4794e4?source=rss----7f60cf5620c9---4
via RiYo Analytics








No comments