https://ift.tt/jpXy0rQ With the ever-growing applications of Artificial Intelligence (AI) like ChatGPT passing an MBA-level exam or AI-gen...
With the ever-growing applications of Artificial Intelligence (AI) like ChatGPT passing an MBA-level exam or AI-generated art allowing architects to conceptualize and design buildings, the terms machine learning (ML) and deep learning (DL) are everywhere. But what do these two terms mean? Unfortunately, we might sometimes see these terms being used interchangeably, which could be confusing to budding data professionals.
Machine learning is a subset of AI that allows a computer system to automatically make predictions or decisions without being explicitly programmed to do so. Deep Learning, on the other hand, is a subset of ML that uses artificial neural networks to solve more complex problems that machine learning algorithms might be ill-equipped for.
In this article, we'll discuss what the two terms mean in more detail, as well as how they differ from one another.
A Brief Introduction to Machine Learning
What if we had a dataset on different football teams, the matches they played, and the statistics of each match and team? Could we use the data to try and predict which team would win the next match?
Yes! That's exactly what machine learning can help us with.
ML algorithms (or models) can learn from data and make future predictions based on what information the model was able to learn from that data. For example, let's look at a small subset of the data corresponding to these football matches:

Source: Predict Football Match Winners With Machine Learning And Python
We can input the structured, tabular data into a ML model. The model can then look over all the features (columns) and observations (rows) in that data and potentially learn which features likely correlate to a team winning, losing or drawing a match.
For example, the model might be able to learn that Arsenal wins more matches when it plays on Tuesdays and Thursdays, at its home venue, and when the match is in the afternoon. Such a pattern might have been difficult for us to identify from hundreds or thousands of observations, but it is entirely feasible for a machine learning algorithm to pinpoint. The model is trained to learn those patterns on its own.
Once we train the model, it can then predict which teams will win, lose, or draw future matches with a certain level of accuracy. If we had more observations for the model to train on, it could potentially perform better. But, it's not just about the quantity of the data, it's about the quality as well.
It's not always the case that every feature is going to be of value to our model. A ML model would not accept string data as input, so, we would have to convert that feature from a string data type to an appropriate numeric data type. Or, if we have data only from the year 2022, the season column might be of no use to our model, so we could consider removing it. We could also collect more features that could be useful to the model, like the average temperature of the venue during a match — perhaps different weather conditions could affect a team's performance.
We call this modification of features of our data feature engineering, and it's a fairly common, but important, part of any Machine Learning workflow that can help improve a model's performance. We can apply the same workflow to a variety of problems.
The problem we discussed above is a classification task in which we try to classify a team into a specific category. We can use machine learning to solve several problems, and we can categorize ML models into different types:
- Supervised Machine Learning: the model learns from labeled data. For example, we could use a supervised ML model to predict whether a football team would win or lose a match (a classification task), or predict the number of goals a team might make during a match (a regression task).
- Unsupervised Machine Learning: the model learns from unlabeled data. We could use an unsupervised ML model to create clusters to segment customers of a bank into different categories and then apply different marketing strategies to each segment.
- Reinforcement Learning: the model learns by interacting with its environment and receiving a reward based on that interaction. For example, we could use a reinforcement learning model to train a robotic arm to pick and place certain objects.
And each type has its own unique set of algorithms. For predicting which football team is likely to win a match, we could try to use either Logistic Regression or Decision Trees to develop a model.
What Is Deep Learning?
Since deep learning is a subset of ML, we can use it to solve similar problems or tasks. Artificial neural networks are at the core of deep learning:
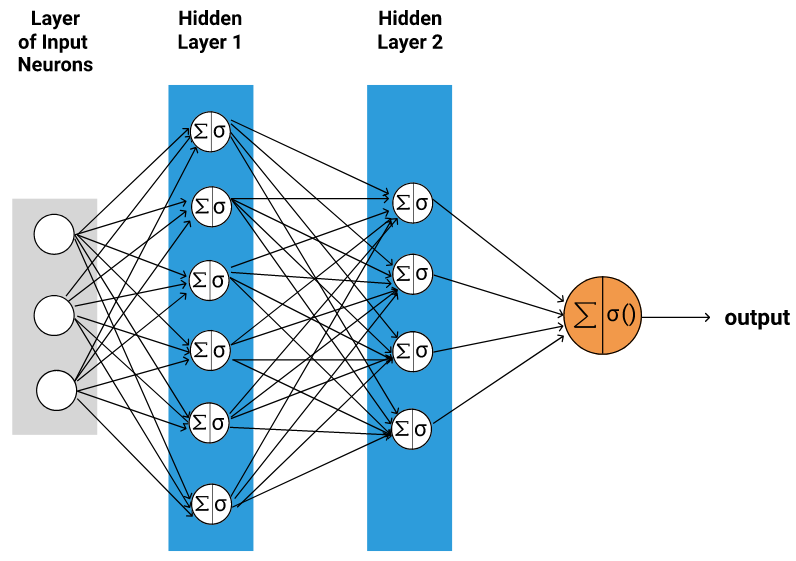
The neural network takes in input data and passes it through several hidden layers. Each hidden layer consists of multiple nodes (or neurons) that try to extract relevant features from the input data. Each subsequent layer can learn to extract different types of features. The final output layer, based on the features extracted by the hidden layer, tries to predict a value.
The "deep" part of deep learning corresponds to the number of hidden layers a model could have. By adding more layers and designing neurons that are capable of extracting features on their own, without human intervention, DL models can be used for much more complex tasks that ML models are often ill-suited to handle. For example, we can use deep learning models to transcribe and summarize podcasts, lecture notes, and meeting recordings!
There are several types of neural networks that can be used for different applications. The one we discussed above is called a multilayer perceptron, a type of feedforward neural network. It could be used for the football match prediction task discussed previously. Discussing the details of the different types of neural networks is beyond the scope of this article; however, here are some other types we might come across:
- Convolutional neural networks: these are commonly applied to spatial data, such as images. They have proven to be very effective for image processing or computer vision-related tasks such as object classification, detection, or segmentation.
- RNNs and LSTMs: they are commonly applied to sequential input data such as text or a time series (https://en.wikipedia.org/wiki/Time_series). They are used in the fields of natural language processing (NLP) and speech recognition.
- Transformers: Transformers are also commonly applied to sequential input data and are the current state-of-the-art models for NLP tasks. Applications like ChatGPT were built using models like GPT 3.5 that incorporate transformers as part of their model architecture.
Machine Learning vs. Deep Learning
We have already discussed some of the advantages of deep learning over machine learning. We can use DL models for more complex tasks, and these models do not usually require human intervention for feature engineering since they are capable of learning features on their own.
Additionally, we don't need to feed DL models structured data. For example, if we wanted to build a model that could classify different types of dog breeds, we can input individual pixels of each image into the model instead of inputting a collection of rows and columns that describe each individual feature of each dog breed. The model would learn to extract those features on its own and might even identify some that we failed to. However, designing a model architecture that can extract relevant features from a dataset can be a very challenging task.
This capability of extracting features also allows us to feed in much larger quantities of data to these models. The model behind ChatGPT was trained on 570GB of data! However, that amount of data not only implies the need for a much more complex model but also one that takes up a lot of computational resources. The additional complexity also makes DL models more difficult to interpret and debug.
ML models, on the other hand, are more suitable for relatively smaller datasets, don't require as much computational power, and require less time to train.
Conclusion
In this article, we briefly discussed machine learning and deep learning and how they differ from one another. Machine learning is a subset of artificial intelligence that allows a computer system to make predictions or decisions without being explicitly programmed to do so. Deep learning is a subset of ML that uses artificial neural networks to solve more complex problems.
While ML models are more suitable for small datasets and are faster to train, they do require us to feed in relevant features for the models to learn effectively. DL models, on the other hand, are more complex, which allows them to learn those relevant features on their own, and they can be trained over much larger datasets. Unfortunately, the added complexity and larger datasets also result in the models requiring significant computational resources.
If you'd like to learn more about these topics, we recommend checking out our Machine Learning in Python and Machine Learning Paths to learn about different ML and DL algorithms and implement them on real-world datasets using tools like Scikit-Learn and TensorFlow.
from Dataquest https://ift.tt/pGSXOB8
via RiYo Analytics








ليست هناك تعليقات