https://ift.tt/7XsRHcS Code implementations for ML pipelines: from raw data to predictions Photo by Rodion Kutsaiev on Unsplash Real-...
Code implementations for ML pipelines: from raw data to predictions

Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place. Filling the missing values, one hot encoding for the categorical features, standardization and scaling for the numeric ones, feature extraction, and model fitting are just some of the stages that take part during a machine learning project before making any predictions. When working with NLP applications it gets even deeper with stages like stemming, lemmatization, stop word removal, tokenization, vectorization, and part of speech tagging (POS tagging).
It is perfectly possible to execute these steps using libraries like Pandas and NumPy or NLTK and SpaCy for NLP. The problem is when using the model in production it may lose code consistency among the team members and also the chances of human error in the code are higher when not operating a specially designed framework through the steps. This is why ML teams tend to work with high-level APIs called Pipelines, specially designed to link all the stages in a single object.
This article will present a code implementation for ML Pipelines using two of the main libraries available: Apache Spark’s MLLib and Scikit-learn. Scikit-learn has a fantastic performance running only on the CPU due to smart NumPy vectorized executions, which are friendly to CPU cache lines, and highly efficient use of the CPU available cores. Although within a big data context, Apache Spark’s MLLib tends to overperform scikit-learn due to its fit for distributed computation, as it is designed to run on Spark.
Datasets containing attributes of Airbnb listings in 10 European cities¹ will be used to create the same Pipeline in scikit-learn and MLLib. The Pipeline will manipulate the numerical and categorical features in the pre-processing stage before applying a Random Forest Regressor to generate price predictions for the listings. Those are the features and their respective data types:
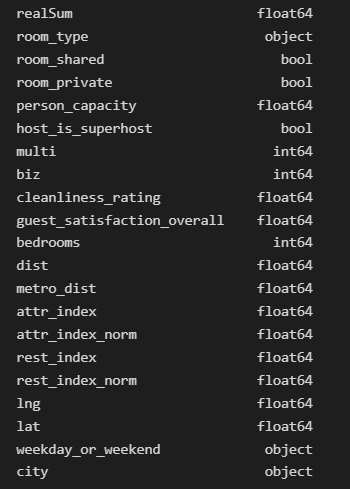
First, let’s load the datasets. As the prices tend to vary a lot during weekends and weekdays, there is a csv file with a dataset containing data of the listings during weekdays and weekends to each of the cities. Thus, to facilitate our job it is possible to consolidate all the datasets into a single dataframe and create the “city” and “weekday_or_weekend” features, which definitely will be essential features to the model.
It is necessary to group the numerical features in a list by selecting the float columns and using the pop method we exclude the first feature, realSum, which is the price of the listings and our target feature. The multi and biz features have 1/0 encodings and scikit-learn allows us to input them to the model as bool types, so we’ll convert them. Finally, we create the categorical features list by selecting the columns of bool and object data types.
Then we can import all the necessary classes of the Scikit-learn lib. There is a class called ColumnTransformer that applies the transformers in the dataframe columns. The numeric transformer will be a standard scaler and the categorical feature will be a traditional one hot encoder. In the calling of Column Transformer, the previously created lists will be assigned to each transformer and it’s possible to join them in the pipeline with the Random Forest Regressor. And that’s it. When working with pipelines the feature manipulation process becomes more fluid and organized as this simple, but operationally dense, code below shows.
Finally, we can fit the pipeline into the training dataset and predict the prices for the test dataset listings just like is done with any other model. The mean absolute error of the pipeline was 67 euros, which is pretty good considering we did not apply any outlier treatment technique, created only two new features and just set the maximum depth and number of estimators parameters on the Random Forest Regressor, which leaves room for hyperparameter tuning on the regressor.
Now that we’ve successfully created and applied the pipeline with scikit-learn let’s do the same with Apache Spark’s library MLLib. For that, I used Databricks, a cloud data platform created by the same founders of Spark for deploying advanced machine learning projects. Obviously, it runs on Apache Spark, which makes it the right choice when dealing with a big data context because of Spark’s properties of large-scale distributed computing. Databricks has a community edition hosted in AWS that is free and allows users to access one micro-cluster and build codes in Spark using Python or Scala. I highly recommend it to improve Spark and Databricks skills without incurring any costs even though there is only 15 GB of available memory on the free micro-cluster, which limits real-life big data applications.
The first thing to do on Databricks is creating a cluster, which is a set of computation resources and configurations on which we’ll run our Pipeline. This can be done by clicking create -> cluster on the top left menu. The cluster is already started with Spark and all the essential machine-learning libraries installed and it is even possible to import any other necessary lib. The only limitations are the limited memory, 2 CPU cores, and the auto-termination of the cluster after two hours of idle activity.
Databricks also has a user interface (UI) for table upload, which can be accessed by following create -> table on the top left menu. On the data loading UI it is easy to load the csv files into Delta Lake tables and also manipulate some of the properties of the table like inferring the schema, selecting the data types, and promoting the first row to the header. So let’s load our csv file with the dataframe created during the scikit-learn pipeline.
Now that the cluster is created and the data is in order we can start the notebook by creating it on the same top-left menu used for the cluster and table setup. The read.csv function of Spark also allows us to define the first row as the header and infer the data schema, and we simply use the directory of the table to load the dataframe and remove the index column.
Time to meet the MLLib. To reproduce the pipeline built in the first section we must load the OneHotEncoder, StandardScaler, VectorAssembler, and StringIndexer functions from the feature class, the RandomForestRegressor from the regression class, and the Pipeline from the class with the same name. Unlike in scikit-learn, MLLib does not allow bool columns to be used in the operations so first, we must convert them to integers. Another difference is that for the categorical columns, we must add a stage of string indexing before the one hot encoding since in MLLib’s OHE function uses only categorical indices as input, and not strings or boolean values.
A good practice when building a Pipeline on MLLib is to write the name of the input and output columns to keep track of the features since, unlike in scikit-learn’s Column Transformer, the transformations do not happen in the input column itself, instead, they add a new column to the existing dataframe.
The final difference between the two pipelines is the order of the transformations. In scikit-learn, the categorical and numerical transformation occur in parallel during the pre-processing stage of the pipeline, while in MLLib we first apply the one hot encoder, then consolidate all the features in a single vector using the VectorAssembler and finally apply the StandardScaler function before the random forest regression. Thus, instead of a pre-processing stage and a regression stage, all the steps of the pre-processing are added to the pipeline in order before the regression.
With the pipeline finished, three lines of code are enough to split the data into training and test datasets, fit the model into the training dataset and make the price predictions for the test dataset. In MLLib, the RegressionEvaluator function is used to evaluate the models and contains all the evaluation metrics inherent to regressions (there are also functions for classification model evaluation). Just like in the first pipeline, the mean error average will be used as the evaluation metric.
And to nobody’s surprise, the mean average error is almost identical to the first pipeline.
Wrapping it up, we’ve shown how ML pipelines simplify the coding process during a model implementation, making it cleaner and faster by improving the code readability with a logic workflow of the transformations during the model training. Pipelines are vital for ML projects involving large sets of data and with multiple data science team members involved.
Along the coding implementation, we’ve seen that Scikit-learn has some tiny advantages in the pipeline creation flow over Apache Spark’s MLlib. The ColumnTransformer function is able to convert both categorical and numerical features in a single line of code, which reduces the Pipeline stages when compared to MLlib. Also, some might say that you won’t be able to duplicate a complex scikit-learn pipeline on MLlib, and that might be true considering how deeper are scikit-learn functions when compared with MLlib.
Nevertheless, MLlib’s ability to scale projects by processing big sets of data using Spark’s distributed processing makes it extremely valuable as well. Further, the pipeline to choose is highly dependable on the project’s context. For instance, when working with Databricks one might access data through the Delta Lake within the platform, and in that case, might be a better option to use MLlib to run the pipeline. It is even possible to join the two worlds and use MLlib pipeline only as a data engineering tool to prepare data, and considering a large dataset that would be a wise choice, to then build modeling and run the training and evaluation with scikit-learn.
Hope you got to know (or review) the importance of pipelines in a machine learning project and the differences between scikit-learn and MLlib pipelines. It might take some time to structure them, but in the long run the organization pays off in multiple ways.
[1] Gyódi, Kristóf, & Nawaro, Łukasz. (2021). Determinants of Airbnb prices in European cities: A spatial econometrics approach (Supplementary Material) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.4446043. CC BY 4.0 License.
Apache Spark MLlib vs Scikit-learn: Building Machine Learning Pipelines was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/apache-spark-mllib-vs-scikit-learn-building-machine-learning-pipelines-be49ecc69a82?source=rss----7f60cf5620c9---4
via RiYo Analytics







ليست هناك تعليقات