https://ift.tt/T15kaEr Discover a cost-effective ad campaign strategy by defining and evaluating model sensitivity, with step-by-step guida...
Discover a cost-effective ad campaign strategy by defining and evaluating model sensitivity, with step-by-step guidance and Python implementation

This blog post outlines a tactic for businesses that utilize paid traffic in their advertising. The objective is to acquire paying customers with minimal traffic while maximizing efficiency. Predictive modeling is utilized to assess and enhance the model’s effectiveness in achieving this goal. By defining and analyzing model sensitivity, companies can attain their desired outcomes while saving money. This article offers a Python implementation and a detailed, step-by-step guide to the approach.
We will cover the following:
· Introduction
· Understanding Confusion Matrix for Predictive Modeling in Business
· Talk Python To Me
· Here is the full code
· Summary
Introduction
Buying paying customers with less traffic is a common challenge for companies that advertise using paid traffic. The goal is to make these purchases as efficient as possible by buying less traffic and yet getting as many buying customers as possible. One way to achieve this is by using predictive modeling to evaluate and optimize the model's performance.
Predictive modeling involves using statistical techniques to make predictions about future events or outcomes based on historical data. In this context, the goal is to predict which customers are likely to make a purchase so that the company can target its advertising efforts toward those customers.
To evaluate the performance of a predictive model, we can use a confusion matrix. A confusion matrix is a table that is used to define the performance of a classification algorithm, and it is especially useful in evaluating binary classification models, like the one we are discussing. The matrix compares the predicted outcome of the model to the actual outcome.
One of the metrics that is commonly used to evaluate the performance of a binary classification model is recall. Recall is the number of times the model predicted it’s a buying customer, and it was, divided by the number of actual buying customers. In other words, it measures how well the model is able to identify positive cases, in our case, buying customers.
Another important metric to consider is the threshold. The threshold is the point at which a predicted outcome is considered positive. Increasing the threshold will increase the number of false positives, decreasing precision. While decreasing the threshold will increase the number of false negatives, decreasing recall.
The balance between precision and recall is known as the trade-off. It’s important to find the best threshold that maximizes the recall while minimizing the precision to get as many paying customers as possible with less traffic.
In this blog post, we will discuss a strategy for buying paying customers with less traffic. By evaluating models by defining the model sensitivity, companies can save money while still achieving their desired results.
Understanding Confusion Matrix for Predictive Modeling in Business
When it comes to predictive modeling in business, it’s essential to have a model that can accurately identify buying customers, as they are often a rare and valuable segment. One way to measure the accuracy of a classification algorithm is by using a confusion matrix.
A confusion matrix is a table that summarizes the performance of a classification model by comparing the predicted and actual values of a binary classification problem.
he four categories in a binary classification confusion matrix are:
- True Positives (TP): The number of positive instances that were correctly predicted as positive by the model.
- False Positives (FP): The number of negative instances that were incorrectly predicted as positive by the model.
- True Negatives (TN): The number of negative instances that were correctly predicted as negative by the model.
- False Negatives (FN): The number of positive instances that were incorrectly predicted as negative by the model.
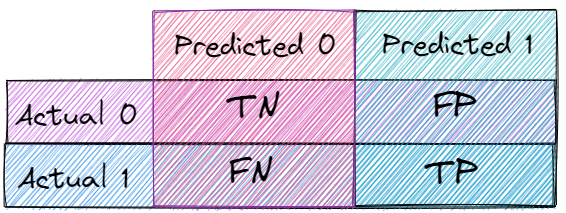
True Positive (TP), False Positive (FP), False Negative (FN), and True Negative (TN). TP represents the number of times the model predicted a buying customer, and it was accurate, while FN represents the number of times the model missed a buying customer. FP represents the number of times the model predicted a non-buying customer, but it was wrong, while TN represents the number of times the model predicted a non-buying customer, and it was correct.
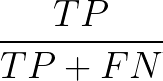
The recall metric, also known as sensitivity or true positive rate, measures the proportion of actual buying customers that the model correctly identifies. It is calculated as TP/(TP+FN), which represents the number of times the model predicted a buying customer and was correct, divided by the total number of actual buying customers.
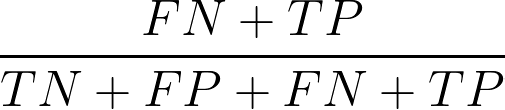
In addition to measuring the model’s sensitivity to buying customers, the confusion matrix can also provide insights into the amount of traffic and buying customers that can be expected from a specific threshold. By calculating (FN + TP)/(TN + FP + FN + TP), one can determine the percentage of buying customers out of all customers that the model will correctly identify at a particular threshold.
However, it’s important to note that increasing the threshold will increase false positives, decreasing precision. One approach to balancing the sensitivity and precision of a model is by setting a desired percentage of paying customers and calculating the threshold that will achieve that percentage according to the specific model.
Understanding the confusion matrix and its metrics can provide valuable insights into the performance of predictive models in business, especially when identifying rare and valuable segments such as buying customers. By analyzing the confusion matrix, businesses can optimize their models and make data-driven decisions that lead to better outcomes.
Talk Python To Me
Machine learning models are evaluated using various metrics such as accuracy, precision, and recall. In some cases, achieving a certain level of recall is more important than maximizing accuracy. In this post, we’ll walk through how to evaluate a model based on a desired recall level using Python code.
The Problem: Suppose we have a binary classification problem, where we want to predict whether a user will buy a product or not. The data set contains 200,000 records, with 30,630 positives and 169,070 negatives. Our goal is to train a model that can predict with high recall which users will buy a product.
The Solution: We can use the following Python functions to evaluate the performance of our model with the desired recall:
- extract_threshold_given_recall(y_test, probabilities, given_recall) This function takes three inputs:
- y_test: the target values of the test set
- probabilities: the predicted probabilities of the test set
- given_recall: the desired level of recall
The function calculates the precision-recall curve using the y_test and probabilities, and returns the threshold value for the given recall.
- get_model_results_for_recall(model, X_test, y_test, X_train, y_train, given_recall, with_plots=True) This function takes six inputs:
- model: the trained machine learning model
- X_test: the feature matrix of the test set
- y_test: the target values of the test set
- X_train: the feature matrix of the training set
- y_train: the target values of the training set
- given_recall: the desired level of recall
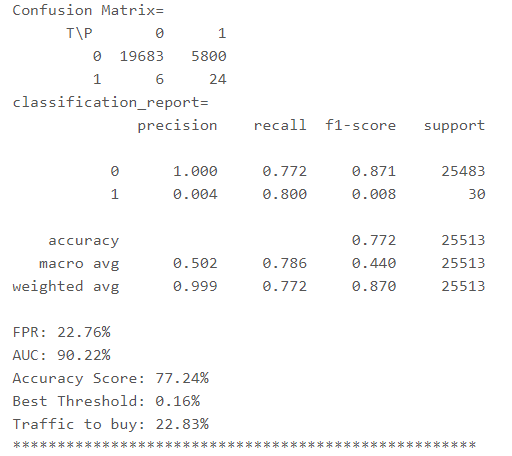
The function first calculates the predicted probabilities of the test set using the model. It then calculates the ROC curve and the best threshold value for the desired recall using the extract_threshold_given_recall function. Finally, it calculates the confusion matrix, classification report, FPR, AUC, Accuracy Score, Best Threshold, and Traffic to buy. Optionally, the function can also plot the ROC curve.
The output will look like this 👇
Here is the full code:
Summary
In this post, we’ve seen how to evaluate the performance of a machine-learning model using the desired recall level. By evaluating models by defining the model sensitivity, companies can save money while still achieving their desired results of buying paying customers with less traffic. We have provided a python implementation that can help with this process by finding the best threshold that maximizes the recall. Maximizing the recall can reduce buying unpaying customers because recall is a metric that measures the proportion of actual positives (i.e., paying customers) that are correctly identified as such by the predictive model. By optimizing the model to maximize recall, the model is better at identifying paying customers, which means that the company can avoid buying traffic that is unlikely to result in paying customers. This can reduce the cost of acquiring customers and increase the efficiency of the company’s advertising budget.
Sensitivity in Predictive Modeling: A Guide to Buying Paying Customers with Less Traffic was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/sensitivity-in-predictive-modeling-a-guide-to-buying-paying-customers-with-less-traffic-c2ab97f6d629?source=rss----7f60cf5620c9---4
via RiYo Analytics






ليست هناك تعليقات