https://ift.tt/ySZFmpP The first installment of Learning from Machine Learning features an insightful interview with the mastermind behind ...
The first installment of Learning from Machine Learning features an insightful interview with the mastermind behind BERTopic, Maarten Grootendorst

Welcome to “Learning from Machine Learning,” a series of interviews that explores the exciting world of machine learning, with a focus on more than just algorithms and data: career advice and life lessons from the experts.
Artificial intelligence is changing the world, and machine learning is fueling this revolution. In each episode, leading practitioners from industry and academia share their knowledge, experiences and insights on what it takes to succeed in this rapidly-evolving field.
The inaugural episode features Maarten Grootendorst, the creator of BERTopic and KeyBERT and author of many articles here on Towards Data Science. He shares his thoughts on Open Source projects, the role of psychology in machine learning and software development and the future of Natural Language Processing. The video of the full interview can be seen here:
The podcast is now available on all podcasts platforms:
Takeaways
Maarten Grootendorst is the creator of many powerful Python libraries including KeyBERT and BERTopic. He started his career in psychology and after obtaining a master’s in Clinical Psychology and Organizational psychology — transitioned to data science. He quickly made an impact on the field by developing open source libraries and writing poignant data science articles. BERTopic, his most used library, is a framework for topic modeling, which is a way to automatically identify topics in a set of documents. It can be used for exploratory data analysis and to track changes in trends over time. He also discusses the challenges he faced while creating BERTopic, as well as the goals and features of the most recent version.
Maarten discusses the implications of ChatGPT-type approaches, which have been mistaken for artificial general intelligence (AGI), and how they are accepted into industry. He is curious to see how these large language models with billions of parameters fit into the AGI discussion and believes the coming year will be drastic.
Maarten’s advice includes:
- Focusing on understanding and knowing the basics of coding and machine learning before moving on to more complex algorithms.
- Building a strong foundation, as it will allow for better and easier growth in the future.
- Understanding the evaluation of your models. When it comes to topic modeling the “truth” is often in the eyes of the beholder.
- Emphasizing the importance of truly understanding the problem before attempting to solve it, citing his experience in cancer research where one of his colleagues spends weeks trying to comprehend the issue before coding.
- You don’t need to know everything all at once. It’s important to find a balance between a healthy life and his passion for machine learning.
Full Interview
Background
Seth: Welcome. It’s my pleasure to have Maarten Grootendorst. He’s the creator of many useful Python libraries including KeyBERT and BERTopic. I’ve been an admirer of your work for some time and really love using your libraries. Welcome!
Maarten: Great, thank you for having me. Love being here.
Seth: So just to get things kicked off can you give us a little bit of background on your career journey, how you got into data science?
Maarten: Yeah, of course. So I have a bit of an on orthodox background. I started out as a psychologist. I have a master’s degrees in organizational psychology and clinical psychology. Those were very interesting fields to pursue and very interesting work to be done. But I always felt like there was something missing.
Something, I wouldn’t necessarily say factual, but a little bit more hard instead of the soft science that I was doing at the time. So I started to explore more of the statistical side of things because that’s something that we do quite a lot in psychology and eventually I got into programming and machine learning.
And I figured, okay, studying in the Netherlands is relatively cheap, so let’s do a master’s in data science. And that’s where I found my passion really. It’s where I could find a true combination of psychology and still a technical aspect of it. Because much of what we do in data science in almost all cases involves some sort of human aspect.
So that’s why I really could make use of my psychological background. And then after that, I developed a few packages like be KeyBERT and BERTopic did some writing and stuff like that.
Seth: Right. Yes, all those amazing useful packages. So, your background in psychology, do you want to just dive a little bit deeper into that?
Maarten: Yeah, of course. I started out with a bachelor in social psychology, and that’s rather broad, right? Composites quite a lot of different subjects. And my mother is actually an organizational psychologist, so, so I kind of had to follow her into her footsteps. No, but that was something I was familiar with and something I found to be interesting.
And mostly the organizational psychology I found to be really interesting. It’s the human behavior in the workplace and how they relate with everything that happens in such a major aspect of your life, which is work, right? But at the time I really wasn’t, well, let’s call it mature enough to really go into the field and do the stuff that was needed.
I figured, okay, let’s explore and develop myself a little bit further before I roll into my working life. And so I explored clinical psychology where I could focus a little bit more on the treating people that have, or helping people more specifically with anxiety disorders or depression or PTSD, things like that.
And then, of course, you learn quite a lot of interesting things from there, but I always felt something was missing. Not that these fields are not interesting, but you know, people like me always try to find their purpose in life in a way to find, okay, what makes me happy? Right. And although it was nice and interesting I was quite sure that it wouldn’t make me happy for the coming 30, 40 years.
So you explore and that’s when I eventually found machine learning.
Seth: When you first found machine learning, what was it that really attracted you to it?
Maarten: The interesting thing about that is that because I was missing something more technical that’s one of the first things of course that attracted me to machine learning because you can really, it’s a new field.
And there’s a lot of technical basis surrounding many of these algorithms, but the way you use it and the way you apply it still requires you, in many cases, to have some sort of business sense. Some sort of view of, okay, when are we going to use this? Is it really necessary? Do we need a very complex algorithm or can we use something relatively straightforward?
That puzzle is really interesting because there’s so many small aspects to it, much more than just, okay I’m gonna optimize the hell out of this algorithm.
And that puzzle, that’s what it still is to me. That puzzle is really interesting because there’s so many small aspects to it, much more than just, okay I’m gonna optimize the hell out of this algorithm. That really attracted me to it. And where I could find many of what I believe are my skills to be made good use of.
Seth: When you were making the transition from psychology to the more technical realm. What were the things you felt you needed to learn first?
Maarten: So as a psychologist, you’re not the most technical person, right? You’re focused on this interaction, human behavior and observational skills.
There’s some statistics in there, but the main, very first thing really is the basics. So, coding, of course you can know an algorithm perfectly well, but if you cannot code clearly and well, there’s bound to be bugs or issues or whatever found in there. That’s really, really important to do that well.
Instead of going into very complex learning algorithms, it’s really starting from, okay, how does a very simple regression work, which actually can be quite difficult if you really go into some of the complexities of it. So I was really focusing on making sure I understood that perfectly well, as much as possible before going into the next steps.
The best way to learn is really, really understanding and knowing the basics. And if you have the basics really well done, like it’s an intuition or something that you can do automatically, going into the next step becomes so much easier. So that has been my focus.
Seth: So just sort of creating the building blocks that could be the foundation for your future work.
Maarten: Yeah. Yeah. That’s nicely worded that foundation. The better the foundation the better you can build on top of it.
BERTopic Deep Dive
Seth: Exactly. So having the creator of BERTopic I figured that we should take some time to go into it. I’ll let you give an introduction to it, if you don’t mind. Just talk about topic modeling a little bit and the power of it as well.
Maarten: Yeah, sure. So BERTopic is a framework for topic modeling where you essentially have, well, let’s say 10,000 documents. And it can be anything, right? It can be reviews for a certain product, they can be tickets for a certain system. They can be multidisciplinary consultations for a hospital and, and some patients. And essentially what you want to do is you want to know: what are these documents about? And there are many things that you can do. You can read all 10,000 of them and label them, which is perfectly fine. If you have the time.
Seth: Take a little bit of time.
Maarten: Just a little bit or you can do it automatically.
And that’s where topic modeling of course, comes in because as the name implies essentially tries to extract topics from those sets of documents and tries to communicate them in a way that helps you understand what these documents are about. It also can help you do trend analysis, for example if you have Twitter messages to see how Covid is being talked about two years ago compared to now.
And it’s a very nice way to extract that information, but because it’s an automatic way without a ground truth, it also is very difficult to evaluate. So, it’s something that really fits with me as a psychologist because it allows for a lot of human evaluation and interpretation of the technique.
And you can use it for exploratory data analysis, just to see, okay, what do I have in my documents? But it’s also used in a lot of sociopolitical science where we look at certain information that has developed over the last few years and see how these trends have, have developed and changed for certain classes or targets or whatever.
Seth: Yeah. I’ve been following BERTopic for some time and I know version 0.13 just came out recently. I’m wondering, what was the goal of the initial package? And, how has it changed over the three years or so?
Maarten: It started out as a way to create a pipeline. Okay. So the pipeline of clustering and trying to extract a topic representation out of that has been around for quite a while. But I wanted to find a way to do it in a sort of pipeline where there’s very little assumptions being made between the steps that you are using.
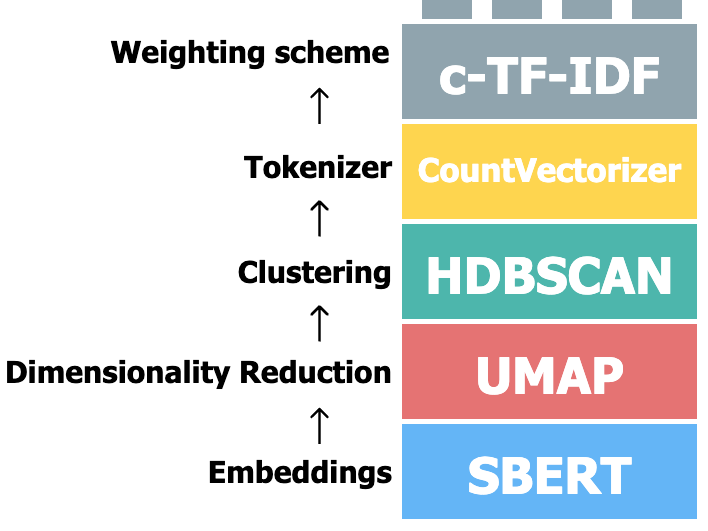
So what we’re essentially doing is we’re transforming our documents into numbers, into numerical values, reducing that to smaller dimensions. So instead of 300 values, you’re gonna compress it into five. We’re gonna cluster those documents and from those clusters, which we assume to be topics, and we extracted topic representations, and there have been a lot of pipelines that do that.
But the way your topic initially thought of was making it in a way where you can say, okay, I’m not really happy with this clustering algorithm and I’m gonna choose something entirely different. Or, I’m not happy with this dimensionality reduction algorithm. I’m gonna choose something different.
And then the focus was mostly on the last part, on the topic extraction way. And I’m using a modified TF-IDF measure for that called cTF-IDF. And because I initially thought of it doing that way it was very easy to then devise many variations and extensions to a topic often are different packages.
So in topic modeling, you have LDA, which is the classical topic modeling technique. Yeah. But if you want to use some sort of variation of that, you have to install a different package. In many cases, not all cases, of course, the gensim has a lot of implemented already. But if you want to do hierarchical topic modeling or dynamic topic modeling, I think it’s not implemented and you have to install different packages for that.
And what I wanted and what it’s now becoming is a one-stop shop for topic modeling and without necessarily saying, okay, per topic is the best ever topic model out there. Which it definitely isn’t. I mean, we still need to adhere to the No Free Lunch theorem. But you can use it for basically everything.
And because I focused on that pipeline of having minimal assumptions per topic. And now do our topic modeling - online topic modeling, class based, semi-supervised, supervised, and a few others. And it’ll continue to develop in that way. So, now what it currently is more focused on is this build your own topic model type of package.
And there are a few more things coming up, but so far that there has been a trajectory for the last couple of years.
Seth: Yeah. Working in the industry now for a couple of years and doing topic modeling. I can say that I enjoy using BERTopic. It’s great — Just the level of abstraction where you don’t necessarily need to know every single detail and that you can get such incredible results.
And also as you were referring to the modularity of it, where you can sort of plug and play and put in different algorithms to get different outputs. So, you touched upon it before in terms of evaluating topic models. Can you discuss why it’s so difficult to evaluate a topic model?
Maarten: What generally happens is you have, let’s say 10,000 documents and they are tweets from some person or collection of people. And what BERTopic or any topic modeling technique then is doing is in an unsupervised way (without a ground truth) extracting topics from these messages, from these documents.
But who’s to say that these topics are accurate? And then what does accuracy actually mean? Is it accurate to say there are a hundred topics in those messages, or is it more accurate to say that there are 10 topics in those messages? Is it more accurate to say that the way these topics are represented by a certain number of words, so the description of these topics, are they more accurate than another algorithm?
But who’s to say that these topics are accurate? And then what does accuracy actually mean? Is it accurate to say there are a hundred topics in those messages, or is it more accurate to say that there are 10 topics in those messages? Is it more accurate to say that the way these topics are represented by a certain number of words, so the description of these topics, are they more accurate than another algorithm?
It also depends on the use case that you’re working with. Sometimes we want more abstract topics because we’re searching for global trends and sometimes we’re looking for very specific topics. So in medical domains, we’re all often looking for very specific types of diseases or context or medicine, or whatever.
All these types of different things make it very difficult to say, okay, this is the truth. Because in this case, the truth often is truly in the eyes of the beholder. It’s your use case. You have a certain goal for it — something that you want to do with it. What you want to achieve with it changes the evaluation metric.
If we’re talking a little bit technical, it can be accuracy. If you have labels, it can be coherence. So how coherent is a topic, but how coherent is a topic differs between what I think is coherent and, and what you think — it’s very different. Because BERTopic is a clustering algorithm. We can say, okay, we’re gonna perform the clustering, or we’re gonna evaluate the clustering.
We can evaluate maybe it’s prediction on unseen documents. But that would be, again, a supervised task. There are a lot of different ways to find out if something is accurate. because the definition of accuracy here is so difficult, and that’s why it’s such a subjective way of modeling.
Seth: Yeah. I think the difficulty is that there’s not necessarily a ground truth, right? You don’t know what category or what cluster something should necessarily belong to. So it’s hard to say this is how accurate this model is.
Maarten: Exactly. And the ground truth can be created, but it should each time be created from scratch depending on the use case because I can create a ground truth for my specific use case, but then ground truth for another use case will be entirely different and will sometimes require an entirely different evaluation metric.
Seth: What are some of the most unique or most interesting uses of BERTopic that you’ve seen?
Maarten: The most most unique ones are often the ones that try to do something with BERTopic is not really meant to do . A lot of sentiment analysis people want to do with BERTopic.
Seth: That’s tricky.
Maarten: It’s tricky. You can do it if you do a sort of semi-supervised approach and code in the semantic nature of it and calculate that beforehand. So it is possible. But what I actually see are a couple of things, and that’s trends analysis. But what has become a little bit more and more popular, and I found that to be really interesting is so initially I always thought topic modeling was something not used in production, right?
It’s an exploratory way of looking at your data, but I’m seeing many more cases popping up that are focusing on trying to identify clusters on the fly. So if you have a ticket system, for example, and you want to see if there are some issues that are popping up daily, yes or no, then you can use an online variant of topping modeling for that to see if new issues pop up over the couple of days.
So you can quickly, fix the issue that you have. And that’s something I developed I think half a year ago because I saw more and more use cases popping up where I say, okay, but what if I want to use it not only unseen data, but unseen data that have different topics than what it was initially trained on.
And then that was for me, a really interesting use case I hadn’t seen before.
Seth: What are the techniques that are used to find new clusters over time?
Maarten: So, there’s one library, I think it’s called River that mostly focuses on that part of online clustering or machine learning approaches in general, but that also allows for new information to be found. So, scikit-learn often focuses on not finding any new topics or new information necessarily. But to continuously train the model, that’s a valid use case. River for example, focuses a little bit more on the true online aspect of it, more finding something that we haven’t found before.
Right?
Seth: Developing BERTopic what was one of the most challenging things that that you faced?
Maarten: So dependency issues it’s way more tricky than I thought before. So I have a couple of packages and some are easier than others but there were a lot of API issues with numpy — they were really tricky to solve and over the course of time it remains an issue because dependencies change of course. In a way it makes sense that they change I also changed the API now and then and so things break but they can sometimes be really really tricky to fix and to find and to account for because there’s so many combinations of dependencies out there and that’s just tricky to account for all of them yeah that’s that’s one issue.
The second one is mostly API development not necessarily algorithms I’ve I find them fun they’re still difficult but it’s not really an issue right but the API in itself is something that people are using daily and if you change that in a major way then everybody has to change. Things that work now in production will stop working so it has been really tricky to think about these things in a way that accounts for anything that I might want to change in the future which is of course not possible because I’m thinking of changing plotly with bokeh now and that’s going to be pain in the ass to do — that’s going to be tricky.
But there are a lot of more things if I want to do — so now you pass in documents right but at some point I want to pass in images and sound and whatever right? It requires major API changes which is difficult to do in a way that doesn’t annoy users because they’re using it quite frequently and if you’re gonna change it dramatically you know it’s not the best user experience so those things actually were the most difficult.
What often happens is when I want to develop features or I want to implement something new I have to introduce new dependency and that’s really something I think you should prevent as much as possible. When developing a package BERTopic already has quite a number of dependencies and I would have just had three in a perfect world which of course doesn’t happen but the moment you add another dependency the interaction between everything can mess everything up right because it essentially gives you another layer of complexity when accounting for all of these dependencies.
…when I want to develop features or I want to implement something new I have to introduce new dependency and that’s really something I think you should prevent as much as possible… the moment you add another dependency the interaction between everything can mess everything up right because it essentially gives you another layer of complexity when accounting for all of these dependencies.
So, when you’re doing topic modeling a natural package to add to that is NetworkX for example to show some sort of network relationship between the topic which would have been really fun to implement and it’s definitely doable but that would require to add another dependency that might not work well together with the ones that I already have. I did some covariant topic modeling for BERTopic which I really want to implement but that would also require me to add the stats models dependency which is a great package but it’s another dependency so I can easily create a list of 20 additional dependencies to add and then at some point BERTopic will not work anymore yeah so it’s unfortunately it’s a balance between those packages that you want to add or not right.
Seth: Weighing those trade offs, trying to keep things as lightweight as possible while balancing additional features and things like that.
Maarten: Yeah, exactly.
Seth:. Yeah. You also refer to something called the psychology of APIs. Do you want to talk about that?
6 Lessons I learned from developing Open-Source Projects
Maarten: Yeah. So, that’s what happens with me, right? I’m extremely biased with my background in psychology, so I call everything the psychology of just because I want to.
Seth: You can get away with it.
Maarten: Great. Then I’ll keep doing that. But the thing is like I mentioned before, when you’re doing API design, it’s about the way people interact with your package, with your model, with your software.
So then changing it dramatically hurts the user experience. So there’s a lot to be learned from popular API design out there like numpy and scikit-learn and pandas, where people at some point have developed a way of coding in part because of those packages. And if you try to adhere to the philosophy and the design of those packages, even when designing something new you’re focusing really on the psychology of the experience.
Because if you do everything in the scikit-learn type of way that’s really nice because everybody knows scikit-learn. And it feels intuitive when you then approach such a model. And the same applies when you’re creating a package. It doesn’t necessarily need to adhere to scikit-learn.
Whenever you create a new parameter, what kind of name are you gonna give the parameter? What is intuitive? Even the position of the parameter can be very important because sometimes people don’t want to create keyword arguments, they just throw in the variable, right? So, the position is really important when designing the package.
And there’s a lot of these types of things that you need to take into account when developing a package because, well, people are going to be using it and if people are going to be using it, okay, then there’s definitely some sort of user experience, psychological aspect of it out there where you can really make a change when it comes to the adaptation of whatever it is you have created.
Seth: What are the most exciting future directions for BERTopic that you’re most excited for?
Maarten: So I mentioned that briefly before.
I’m thinking of changing plotly. And I’m not doing that because I hate plotly. Plotly is awesome. And same with bokeh or altair or whatever. It’s just that I want to add images at some point, which I’ve already done with a different package called concept that tries to integrate documents and images into one topic modeling approach.
And I want to eventually do it also in BERTopic. But in order to do that when you’re going to visualize your data points, you typically also want to visualize the images, and that’s not possible directly. In Plotly, you need to use dash on top of that, which that’s not something that I’m a fan of when it comes to psychology of API design.
It changes the way you interact with the visualizations quite dramatically, quite drastically. So I’m thinking of changing it to bokeh because it allows you to do a little bit more with images. And when it comes to interesting future directions, it’s because we have more multimodal, embedding types of models.
We can do documents, images, sounds all in the same dimensional space. So if you can do that all in the same dimensional space, then there’s something to say for topic modeling also going into that direction. But there’s just a little bit more to think about than just the embeddings. Also the topic representation extraction and the way you connect the images together with the documents and perhaps sound at some point.
That’s something I have to dive a little bit deeper in. I have some code lying here and there but I think there’s also much to be gained there.
Learning from Machine Learning
Seth: What’s an important question that you think remains unanswered in machine learning?
Maarten: So, there are a few of course but there’s one thing that has been one thing popping up quite often lately, and it has to do with, of course, the ChatGPT-type of approaches. What happens when such a model gets released is that people are starting to talk about AI as if it were artificial general intelligence, right?
True intelligence, true consciousness, that it can pass the Turing test those types of exclamations that were made… And the thing is that that’s something that I think that we’re a little bit away from. But it’s starting to become a little bit of a gray field because a lot of people are talking about it in that way.
And although the definition might differ technically we’re still thinking we’re approaching that rather quickly. And if we’re doing that, I think it’s important to then also acknowledge that it’s not the case that ChatGPT is that of course. But what it then is, and how it gets accepted into industry, what is and what isn’t for me, that’s a very important question that we need to take care of.
Because although ChatGPT can do very awesome, interesting things, it’s not factual information. It doesn’t necessarily have to be, it’s not always the case. And that’s something to take into account when developing these types of models. And when we’re looking at these large language models that have billions upon billions of parameters that can do very interesting, very awesome things.
I’m really curious to see how that would then fit into the AGI (Artificial General Intelligence) discussion. But I do think the coming year will be quite drastic the way things are going now.
Seth: Yeah. I think that there’s gonna be another very exciting year for natural language processing, you know, with ChatGPT and GPT-4 coming out in a couple of months.
Sure. That will obviously be interesting. But yeah, there’s definitely some sort of gap between true intelligence and creating large language models with billions or trillions of parameters. It doesn’t necessarily translate into understanding — That’s my take on it.
That touches on my next question, how has the field changed since you started working in the industry? Would it be the advent of large language models, or are there other changes that you’ve seen?
Maarten: So when I started the, the large language models or more when I started doing machine learning the Word2Vec type of models were really coming up and showing the possibilities of those.
And then slowly into the transformer type models. And from there, of course we have what we have currently. I would say that the large language models really change the entire field, especially when you consider what Hugging Face is now, right. With the amount of models that they host and the things that they can do.
What I do want to say is that we see there’s a huge trend going towards those huge major large language models that nobody can actually run on their own machine. And there’s a very small piece of research going there which is a little bit focused more on distillation and making it accessible for you and me, right?
I have a laptop here that has an okay GPU, but not much more than that. And I want to run these models without making use of an api. And that’s not always possible because it’s not that fast. And there are a lot of, there’s still a lot of research packages that go into the direction. If you take sentence-transformers, for example, they distill it and make a very accurate representation of what it has been trained on quite fast.
So the inference and the speed of using those models is really great and I would love to see more of those instead of billions upon billions of parameters. Which is nice though, don’t get me wrong. We need to have those to essentially get to a distillation or smaller version. But it would be nice if there was as much attention to the smaller models as there is to those larger ones, because I can use the smaller ones.
I mean, larger ones are, are not really accessible to me. Right.
Seth: Do you see any connection with how generative models can affect something like topic modeling and BERTopic? Have you thought about incorporating it at all?
Maarten: Yeah. That comes back to dependencies and things like that.
But what I think Cohere has done is they created topically, I think it’s called. That’s basically a GPT on top of BERTopic. So BERTopic generates a number of topics and descriptions of those topics by number of words. And they feed those words essentially into a GPT model and ask to create a topic out of that - just a natural description.
And it does that really well. The issue with such an approach is that from a production setting, it’s really difficult to run on your machine, right? You need to have an API, which is absolutely fine if you’re using Cohere, it’s an amazing service. But when you’re running things locally without any internet connection, having a local GPT model is just not done.
The moment these models become relatively small and doable on your machine — that’s the moment I will start to integrate these into BERTopic. But if you want to use GPT on a couple of hundreds of topics, but slice that over, I don’t know, a hundred classes, that becomes really difficult and really long to calculate all of these things.
That’s the reason why I wouldn’t want to integrate that into BERTopic right now. Right? That’s why what Cohere has done is amazing. It’s something on top of BERTopic if you feel like you need it. Which is also something I would definitely advise using if you have that service or if interested in using that.
But integration in BERTopic is a little bit too far ahead until performance reaches the state BERTopic is right now.
Seth: Right. That that makes sense. Yeah, I’ve experimented using some of the outputs of BERTopic and putting them into some open source generative models, and I’ve been pleasantly surprised.
Maarten: Ah, that’s great.
Seth: I think that that’s definitely gonna be interesting future research. What do you think about the hype that these new generative models are creating? Do you think there’s a big gap between the hype and the reality?
Maarten: Yes and no. It’s an annoying answer I know, but no, I don’t necessarily think there is a gap because a lot of these models, let’s take ChatGPT for example or Stable Diffusion may be a little bit more interesting. So basically from text we’re creating images, that’s amazing that we can do that.

That’s truly amazing. And there are people out there who are actually great prompters who know which words they need to use in order to create awesome imagery. And if you can use that in a very smart way there are a lot of use cases where this might be interesting for mockups, for example, or when you’re creating art for your game or something like that.
There’s still a gap in the sense that it’s not exactly doing the things you want, right? You’re still searching a lot of ways to make sure it gives you the output that you need. It’s a very large model that doesn’t run as fast maybe as you might want it. There’s a lot of issues when it comes to artists being copied right over the internet.
Over the last few months, I’ve seen quite a lot of people who say, okay, somebody trained on my specific artwork and now it generates it as if it were mine. Well, that’s of course not the way that we should go into. So I think there’s a lot of hype that that makes sense, but a lot of the hype is also as a result of something that’s just fun to use.
Whether it’s something that will actually be used in a lot of organizations, I highly doubt that. But there are certain use cases where I do think this will make a huge impact, but they’re just a limited few. And for a lot of people, this is just, just something fun to use and something that’s easy to go viral.
Seth: Right? Yeah. It’s pretty unbelievable. The impact that ChatGPT had getting over a million users in Yeah. In under a week interacting with it. It’s definitely something special. I think they slow down the output so it makes it feel like you’re talking to a human.
Maarten: Maybe it also has to do with I’m not entirely sure, just to make sure that people are still using it without querying it too much.
Right. It slows down, it slows down the time you can actually query it, but even here in the Netherlands, there are a lot of people using it in Dutch and it does it relatively well and that’s interesting to see and I’m wondering when I will see it popping up in actual research and contracts people are writing things like that. It’s amazingly viral.
Seth: Yeah. Have you used it at all to help, to help you with anything? Like even like a day-to-day thing?
Maarten: Not much actually, because it still requires me to correct it quite a lot of the time, and I’m somebody who likes to do it in my way.
But I have been using it when I’m writing articles to come up with ten titles for an article, for example, just to give you some inspiration and to feed off and then I’ll change it nine of the ten times. But I do think it’s an amazing way to get an initial idea of something that you want to create.
If you want to create an introduction about federated learning, just type it in. It can send something back and you can change it the way you want it, you can adapt it. It’s really interesting to see that. Maybe at some point we don’t have to type all these things out ourselves. We just ask somebody or ask ChatGPT to do that.
And then it iteratively ask it to change it in the way that fits with what you’re trying to achieve. So the way we’re writing and interacting might change completely if something like this gets a little bit more open source or eventually more accessible to the public than just an API, for example.
And that will definitely be interesting, right?
Seth: Yeah. I think there’s a certain amount of creativity in creating the right prompts for it. And also that is the way the future’s going to be. It’s this interaction that humans have with the machine to create the best output, to get maybe an initial idea and then you could work off of it or modify it.
Maarten: And that saves so much time in the process also, right? I mean, you know what you want to write. In many cases, you’re writing a paper and you want to write an introduction about, you know federated learning, or maybe stable diffusion, or maybe it’s something else. Just ask somebody else to write an initial draft of it and then you can change it.
You already know what you want to write, and if you’re an expert on the field, then the only thing you have to do is just go over it and check whether everything is correct and properly done. But it saves so much time. There’s also risk involved in all of this, of course, when people are using it and just copy pasting it as is right.
But eventually we’ll also find some way to deal with that.
Seth: Yeah. I think there’s an interesting aspect to it that maybe some people forget. Large Language Models are so powerful because of all of the information that has been created by humans, that’s what laid the foundation for all of this.
So going back into machine learning — are there any people in the field that inspire you — that you’re very influenced by?
Maarten: So there are a few people that I follow, but I wouldn’t necessarily say there are these people that really influence me tremendously. And the reason for that it’s kind of, because from a psychological background, I tend to look at things from as many perspectives as I possibly can, and that the same thing applies to people that influence me.
So I try to take snippets of what people are saying and use that for what I think okay, this is interesting. Because everybody has their strengths and their weaknesses, of course, and I focus on those strengths, but I take 20, 30 people that I think, okay, these are awesome and they are great at that specific thing and I try to combine them.
So I started out learning transformer based models with the visualizations of Jay Alammar.
Seth: Incredible, classic.
Maarten: He’s doing amazing work with respect to that. But that’s one aspect that I take from him, and then I take something else from somebody completely different and use that. So it’s a combination more of people than necessarily, okay, this is somebody that I think, okay I love everything that person is doing which seldom is the case because, you know, we’re people, we’re not great at everything. So, you know, this person’s better at this, this person, better visualization, better coder.
Now I’m a big fan of the Sentence-Transfornmers Library, for example. Yeah. So there’s, there’s one interview that’s coming up with Nils Reimers — amazing work, right? Yeah. But if I want visualizations, I go to Jay [Alammar]. You know, it’s that combination of people, and I think you find them eventually yourself.
Because I can say, here’s a list of 20 people that I find interesting, but I find them interesting because I am who I am and I look at things in a certain way, so, also trying to kind of support my way of thinking with views that support mine. I’m still human in that way. So even if I give these people, it might not fit with somebody else who just sees things differently.
Yeah. So I’m sorry, this kind of a non-answer,
Seth: No, it’s a great take on it. I like that. Are there any people outside of machine learning that inspire you?
Maarten: Well, that’s a good question. So I recently did that animation for BERTopic.
Seth: Love it.
Maarten Grootendorst on Twitter: "It is finally here, the v0.13 release of BERTopic! 🎉Explore multi-topic assignments, supervised topic modeling, outlier reduction, light- and heavyweight options, and much more in this bigger-than-expected release!Changelog:https://ift.tt/RHi3Wpe overview thread👇🧵 pic.twitter.com/SrlRAOagwT / Twitter"
It is finally here, the v0.13 release of BERTopic! 🎉Explore multi-topic assignments, supervised topic modeling, outlier reduction, light- and heavyweight options, and much more in this bigger-than-expected release!Changelog:https://ift.tt/RHi3Wpe overview thread👇🧵 pic.twitter.com/SrlRAOagwT
Maarten: Yeah. Thank you. I wasn’t fishing for that, but it’s welcome.
Seth: I still love it.
Maarten: So I did that with the software of 3Blue1Brown. And I really truly enjoy that. The YouTube channel with mathematics in general and the way it’s being visualized and there’s even a major package on top of that’s open source that everybody can use.
Those types of people, I really enjoy following because they just give information in such a pleasant way that it feels like I’m just watching Netflix, right? If you can do that. So Kurzgesagt for example, I did something quite recently in an article about that, that’s also a channel that gives a lot of information about different types of subjects.
If you can present complicated things in a way as if you’re watching a movie, that’s truly beautiful if you can do that. Yeah. I’m truly impressed with that. So, maybe those types of people influence me.
Seth: Yeah. What I’ve found in data science and machine learning is that, you know, there’s the hard skills, right?
And then there’s the soft skills and being able to explain the work that you’re doing and blending in the psychology of it and understanding how people learn and how people think about things and how people perceive and sort of understanding what’s the best way of saying this? What’s the best way of visualizing this?
It’s so important because then you allow other people in, right? And then you can get their feedback and then that’s when things really start to kind of take off and can reach new heights.
Maarten: Yeah. I fully agree.
It’s something that I, of course, agree I’m super biased in that way, but in this field I really think that sometimes one really cannot exist without the other. And sure I can create the most complex algorithm out there to do some sort of specific task, but if I cannot communicate it properly to my stakeholders, then truly what’s the point?
I see that in open source where a lot of packages are really, really impressively done, but are really difficult to use, so nobody’s using them, which is just a shame because there’s not much thought put into that psychological aspect of it.
But it also works the other way around, right? If I want to explain something, something technical to a person, a difficult algorithm, I really need to understand that algorithm really, really well in order to be able to explain it.
So I can know how to explain it in a way, how to communicate in a way, how to phrase things in a way to capture an audience, but it doesn’t actually mean that I understand the content. So it works both ways.
It’s always nice when people say, okay, you need to have soft skills, but in order to have soft skills, you really, really, really need those hard skills also, because if you don’t know what you’re talking about, well, you can bullshit your way out of it just a little bit, but people will find out.
Seth: You need to be able to back it up with the hard skills for sure.
Maarten: Yeah. And in some cases, I really think they’re just as important. Not in all cases, I mean, it’s not that black and white, but if we’re talking in a business sense, then you just need to be sure that you’re able to do your job.
But then the rest of it definitely is selling it, saying to people, okay, this is worth investing in. And in order to do that, you need to explain it. Well, you need to attract people. And it’s not always the case that you need to do that as a data scientist, sometimes you have managers that do that for you — that abstract those things away from you because there are a lot of technical data scientists out there that don’t necessarily want to be focused on a lot of meetings and a lot of presentations and things like that, which is fair. But then there still needs to be someone who does all of the well selling, essentially.
Seth: Learning how to deal with all the different types of stakeholders from a non-technical person to the CEO, to the head of product, to another data scientist, it’s so important and understanding who your audience is and the best way of getting your learnings across.
To get into the Learning from Machine Learning.
Maarten: Awesome name, by the way. That’s great.
Seth: Yeah. Thank you. I appreciate it. What’s one piece of advice that you’ve received that has helped you in your machine learning journey?
Maarten: Yeah, for me I don’t necessarily know who I’ve gotten this advice from, but understanding the problem truly is a solution.
I’m gonna say that over and over and over again. If you really don’t know the problem that you’re trying to solve, there’s no way you’re gonna get a good solution. And it seems really simple, but it’s not. This is one of the most difficult things that you can do. And there are so few people that can actually truly try or truly understand the problem that they’re working with.
I’m gonna say that over and over and over again. If you really don’t know the problem that you’re trying to solve, there’s no way you’re gonna get a good solution. And it seems really simple, but it’s not. This is one of the most difficult things that you can do. And there are so few people that can actually truly try or truly understand the problem that they’re working with.
I’m working now, for example, in cancer research and I have a lot of amazing colleagues, and there’s one of them that really dives into the issue before coding, right? Takes weeks before really, you know, he still codes and still looks at, at what a potential solution might be, but spends weeks just trying to figure out what exactly is happening here.
How the data looks like, what is the context in which it’s being used, what are the difficulties, the connection with legal, for example — which makes coding so much easier because you have done all of the groundwork, right? And then you know exactly, but exactly what you want to program, what you want to predict once you want to solve.
But that’s immensely difficult because it’s more than just a technical problem. It often also relates to, okay, how is the data being generated at all. You know, in most cases, not always, there is some sort of psychological component to it, or there’s some issue with the data, which is always the case.
There’s always some sort of, you know a dirty data out there.
Seth: Peculiar artifact, right? Like something’s going on.
Maarten: Exactly, exactly. And that really depends on the process. So you need to understand the process of data generation. But then if you’re going to devise a solution, who are you devising it for?
And why do they want that solution? Because what often happens is that people ask for solution, and they might actually mean something entirely different. It’s not their fault because they try to communicate it, but because you are our technical person and you know what the possibilities are, you might say, okay, but then you might need to focus more on this and this direction.
And that might happen that if you don’t do all of this, that eventually you push out a model where people say, “Ah, that’s not really what we’re looking for.” And then what you also often see happening is that the one who created the solution say “Oh, but you should have told me that before.” That’s not the way we should communicate, right?
It’s a two-way street. And you cannot just tell somebody, okay, you need to tell me exactly what you need as if you were a data scientist. It doesn’t work that way. We need to help each other. And understanding the process, understanding the problem really is I think the best way to spend your time in data science.
Seth: 100 percent. Sometimes just a pen and paper right. Before you get into the code.
Maarten: Yep, definitely.
Seth: And then also, just to add on, I would say, Revisiting the problem, right? Like yeah. Maybe even after you start working on a little bit, then you start to realize, oh, you know, all the requirements weren’t quite addressed just yet.
You know, .
Maarten: No, that’s perfect. That’s amazing because, you know, it starts from the problem and as you mentioned, going back frequently to see, okay, I’m still on track with what I perceive to be the problem at first might change later on when you start devising the solution.
Seth: Yeah. The tricky thing about this sort of iterative process in data science is once you do kind of pick a solution at some point. It starts to narrow your vision field a little bit, right?
Maarten: Sure.
Seth: So that’s why you always have to, you always have to go back — understanding and figuring out what’s this from a business standpoint, what’s this from the data standpoint? Yeah, exactly.
Maarten: Yeah. And it’s okay if it becomes a little bit narrower over time. Of course. You start broad now trying to explore everything that’s out there and eventually a solution. So it has to become narrow. But as you mentioned, not too fast it should take some time and it should, you know, it’s, it’s like reinforcement learning.
There should be a balance between exploration and exploitation, right? You know, we’re gonna devise a solution, but we still gonna keep some room for some exploration of some different things to see if that still works or if that’s still relevant or whatever.
Seth: Right. That, that upfront time can save you so much time.
Maarten: So much time. Yes.
Seth: What advice would you give to someone who is just starting out in machine learning or natural language processing?
Maarten: So I would really start doing projects as much as possible, and it’s yeah, I’m really okay if it’s just a Titanic data set or housing regression prices.
I think that’s one. And sure there are a lot of people who’ve already done that, but getting your hands dirty is exceedingly important in data science because at some point you develop an intuition about certain things. You see a problem, you don’t know exactly why, but you feel like, okay, this should be the solution.
And that happens because, I mean, you are also a predictive model in a way. You know that gut feeling — That’s because you learned something before with the previous project where you found something to be working well or something that’s very similar to what you’re doing right now.
And that happens because, I mean, you are also a predictive model in a way. You know that gut feeling — That’s because you learned something before with the previous project where you found something to be working well or something that’s very similar to what you’re doing right now.
And by doing all of these projects and by just getting your hands dirty and analyzing stuff, gathering your own data, cleaning your own data, applying these algorithms going into depth that helps you really understand the field, gets that intuition about when something is working and when something isn’t working.
A famous example is what most people say when they’re starting out, is if you see a model that has a 99% accuracy. Exactly. There’s going to be something wrong.
Seth: Oh, no
Maarten: That doesn’t happen. Generally it doesn’t happen. So that’s an intuition that you develop. At some point, and this is a famous one of course but a lot more of these are out there. There’s a lot of these that have been implemented eventually into BERTopic because there were a lot of things I felt like, oh, there’s something weird going on here.
I’m not entirely sure, but I feel like I should look there and there. Yeah. Now, the only reason why I would do that is because I’ve had a lot of experience with a lot of these projects and it would know immediately where to look, even though it wasn’t something I had already done before. I think if you’re starting out, just do the work,
Seth: Right. That real world or the real project experience can sort of give you an idea maybe where there might be a pitfall, where there might be a pothole and that experience can help you navigate a little bit better.
Maarten: Yeah, definitely. And if you’re really starting out, don’t be scared of people saying, don’t use the Titanic dataset and don’t use housing dataset.
Everybody has to start somewhere, and it’s okay to start with perfectly clean data. It really is. And then you can slowly build your way up to less clean data, gathering your own data and stuff like that.
Seth: Right. So in a similar direction, what advice would you give yourself when you were starting out?
Maarten: Oh, that’s an awesome question. Oh, I really have to think about that.
Oh, that’s tricky because I’m drawing from my own experience of course. Maybe start in the field a little bit earlier. And what I mean with that is I transitioned of course, and because of that I started in the field relatively late. There were a lot of people my age who already had four or five years of experience, and although doing a master’s is nice and definitely recommended.
Experience brings you a little bit further I think, Ah, maybe not a little bit further, but it’s, it’s just as valuable. So if you can do both, that’s amazing of course.
And I think what I never really, truly had is a mentor in my years of data science, not somebody I could always look up to and ask questions about the things that I’m dealing with. I had to discover everything for myself and that has it’s pros, but the main con it slows down some of the learning processes tremendously.
So the advice I would’ve given myself is maybe focus a little bit less on academics during that time and a little bit more on getting that experience.
Seth: It’s still good advice and I like the advisor or mentor idea of that.
I think that that’s something that people tend to shy away from, but I don’t think they should. It’s an important thing that can help you along in your journey. Sometimes it’s nice to do everything sort of on your own, right? And you kind of face the learning pains and you get that real strong sense of accomplishment when you get it done.
Maarten: Exactly.
Seth: But it would definitely Speed things up if you have someone, even just a sounding board to talk to.
Maarten: Exactly. And, a mentor can even do that, right? A good mentor sometimes will say, go figure it out yourself. Because a good mentor will know your capabilities and will know how persistent you are and what you can and cannot do.
A good mentor sometimes will say, go figure it out yourself. Because a good mentor will know your capabilities and will know how persistent you are and what you can and cannot do.
So, he or she will know at some point, okay, if you spend a few more hours, I’m, I’m sure you will solve it, right? And if, by then it’s not possible, okay, I will nudge you in the right direction. Right? But that’s all you get. Right. A nudge. So yeah, that’s something that, would have made a huge difference for me, I think.
A mentor.
Seth: That’s what a good teacher or a good mentor can provide. So to get a little philosophical or bigger picture what has a career in machine learning? Taught you about life?
Maarten: Difficult questions you make me think here. No, but really for me machine learning has come at the same point in my life, roughly as chronic pain.
And, dealing with that was quite difficult. So finding a balance between a healthy life and the thing I really enjoyed most — machine learning at the time. That for me has been quite difficult finding a nice balance between those two, because the chronic pain makes it, for me, difficult to type 10 hours a day for example.
I really have to balance the way and the amount that I work. And that’s tricky, right? So when you switch careers, that’s already quite difficult. But then when you finally find something that you think, okay, that’s it, that’s what I want to do. And then at the same freaking time, you get chronic pain.
That’s not something that makes you that happy. So for me, that has been something that has been very difficult, but it’s been, in hindsight, a very valuable learning experience. Really truly knowing what I stand for, what is important to me, what I want to focus on to take a step back at times.
Because that’s also the field of machine learning — It goes fast, it goes so extremely fast, and there’s nobody that can keep up with everything that’s happening there. But the fear of missing out Yeah. Becomes tremendous. Becomes huge. When things like stable diffusion and chat GPT and all of these things get released on I would almost say on a daily basis it feels at times.
But I’ve really learned to then take that step back and to view the broader picture. You don’t have to know everything. There are a few things that are more or less important than others that you can follow, but eventually you will catch up with whatever is happening.
But I’ve really learned to then take that step back and to view the broader picture. You don’t have to know everything. There are a few things that are more or less important than others that you can follow, but eventually you will catch up with whatever is happening.
I mean, it’s great that ChatGPT is doing so well, but I wouldn’t have to have known it from day one if I weren’t making some sort of business out of the model. There’s no need for me to know it then, so I can give myself a little bit more space to find that balance. , although with BERTopic and writing and KeyBERT, it’s still difficult.
Seth: Yeah. I’m not sure how you find the time to maintain such incredible libraries and keep a day job
Maarten: I have no clue. I try my best. I’m not sure my wife is always that happy, but no, I’ll make sure to find a balance between that. But you’re right in saying, you know, the day job combined with open source and writing is difficult.
So maybe somewhere in the future I would love to combine that. But you know, that depends. It’s open source, right? Maybe if at some point there’s an organization that says, okay, we’re gonna support that fully, then maybe that’s something that’s interesting to me at some point. But for now, I’ve amazing job.
I get a lot of freedom to also work around the chronic pain, which is awesome because there are not many organizations that provide that. And still work on the things that I think are important.
Seth: Well, your work is greatly appreciated by this machine learning scientist, and I’m sure many, many others out there.
So just to conclude, if there are people who are interested in either reaching out to you or learning more about you, are there any places where they could go?
Maarten: You can go on Twitter, on LinkedIn. Those are the main sources for me where you can find me. I have a website.
It’s maartengrootendorst.com, which only Dutch people can understand. It’s just my name, but it’s the way you pronounce it. It’s not the easiest thing to translate into English. But no Twitter and LinkedIn, mostly LinkedIn. You can reach me there quite well. Yeah.
Seth: Awesome. Maarten, it has been such a pleasure talking with you.
Thank you. Thank you so much.
Maarten: Thank you for having me. It was a great interview. I love those questions. Really, most of them are really technical, right? That’s what you do mostly if you have something like KeyBERT or BERTopic. But focusing a little bit more on the philosophical, psychological aspects of it is truly appreciated.
Seth: Absolutely. Thank you so much.
Maarten: Thank you.
Resources
Learn more about Maarten Grootendorst and his work:
- Maarten Grootendorst’s Blog
- BERTopic: BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions.
- KeyBERT: KeyBERT is a minimal and easy-to-use keyword extraction technique that leverages BERT embeddings to create keywords and keyphrases that are most similar to a document.
- Medium
Resources to learn more about Learning from Machine Learning:
- Subscribe on Youtube
- Learning from Machine Learning on LinkedIn
- Reach out to me on LinkedIn
- Follow me on Medium
Contents
- 00:00 Learning from Machine Learning Intro
- 00:20 Maarten Grootendorst Introduction
- 00:54 Career Background
- 02:21 Background in Psychology
- 04:07 What attracted you to machine learning?
- 05:18 What were the first skills you needed to learn?
- 07:12 What is BERTopic? What is the power of Topic Modeling?
- 09:38 What was the goal of the initial package and how has it changed?
- 12:41 Benefits of BERTopic
- 13:18 Why is it so difficult to evaluate a topic model?
- 16:06 The challenge of assigning ground truth
- 16:44 What are some of the most unique use-cases of BERTopic?
- 18:38 What are the techniques to find new clusters over time?
- 19:29 What was one of the most challenging things you faced developing BERTopic?
- 24:13 What is the psychology of APIs?
- 29:04 What’s an important question that you believe remains unanswered in Machine Learning?
- 31:22 Exciting year for natural language processing
- 32:00 How has the field changed since you started working in the industry?
- 34:22 How can generative models effect Topic Modeling and BERTopic?
- 37:00 Is there a gap between the hype and reality of these generative models?
- 39:15 ChatGPT
- 41:30 Interaction between Humans and Machines
- 43:18 Are there any people in the field that inspire you?
- 47:10 Sharing your Data Science work with others
- 50:48 Learning from Machine Learning
- 51:00 What’s one piece of advice that you have received that have helped you in your ML Journey?
- 54:30 Revisiting the problem
- 56:30 What advice would you give someone just starting out in the field?
- 59:36 What advice would you give yourself when starting out?
- 1:02:35 What has a career in machine learning taught you about life?
- 1:06:30 Wrap-up
- 1:06:48 How to reach Maarten Grootendorst
- 1:07:20 Conclusion
Learning from Machine Learning | Maarten Grootendorst: BERTopic, Data Science, Psychology was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/learning-from-machine-learning-maarten-grootendorst-bertopic-data-science-psychology-9ed9b9b2921?source=rss----7f60cf5620c9---4
via RiYo Analytics







ليست هناك تعليقات