https://ift.tt/niRVfxL Image by Dall-E 2. Don’t forget these topics when building AI systems Using sensitive data, discrimination based...

Don’t forget these topics when building AI systems
Using sensitive data, discrimination based on personal information, model outputs that affect peoples lives… There are many different ways harm can be done with a data product or machine learning model. Unfortunately, there are many examples where it did go wrong. On the other hand, many projects are innocent: no sensitive data is used and the projects only improve processes or automate boring tasks. When there is a possibility they can do harm, you should invest time at the topics of this post.
Yes, ethics in data isn’t the most exciting subject you can think of. But if you want to use data in a responsible way, you might be interested in different ways to ensure this. This post contains six important ethics topics and ways to investigate how your model is doing. There are practical tools available to help you with this. Besides the harm that can be done to individuals, another important reason to take responsibility is that ethical considerations can impact trust and credibility in technology. If technology is not seen as trustworthy and transparent, it may harm its adoption and impact its effectiveness. People lose their trust and don’t want to use AI products anymore.
Governance
The first topic to mention is AI governance. The governance aspects of data science and AI include the regulation, ethical guidelines, and best practices that are being developed to ensure that these technologies are used in an ethical and responsible manner.
Governance is a high level term and contains all the following topics, and more. The exact definition can be different across organizations and institutions. Large companies often use a framework to define all the aspects of AI governance. Here is an example from Meta. There are complete research teams dedicated to responsible AI, like this team from Google.
AI governance is work in progress. The upcoming topics are the basics and a good AI governance framework should at least contain these topics.

Fairness
Fairness in machine learning refers to the idea that the model’s predictions should not be unfairly biased against certain groups of people. This is an important consideration when deploying models in real-world applications, particularly in sensitive areas such as healthcare and criminal justice. Unfortunately, there are many examples where it did go wrong, like with COMPAS, chatbot Tay from Microsoft and in job and mortgage applications.
Actually, it’s one of the main ethical concerns in machine learning: the possibility of bias being introduced into the model through the training data. It is important to address the ways in which bias can be introduced and the steps that can be taken to mitigate it.
There are different ways to increase the fairness of a model and reduce bias. It starts with diverse training data. Using a diverse and representative training data set to ensure that the model is not biased towards a particular group or outcome is the first step to a fair AI system.
Different tools are developed to increase fairness:
- IBM 360 degree toolkit
This toolkit comes with a comprehensive set of metrics to test for fairness and algorithms to mitigate bias. Here is a demo. Every metric is explained and it is a nice place to start. Examples of bias mitigation algorithms are reweighing samples and optimizing preprocessing (changes preprocessing), adversarial debiasing (changes modeling) and reject option based classification (changes predictions). - Fairlearn
An open source project with the goal to help data scientists improve fairness of AI systems. They provide example notebooks and a comprehensive user guide.
Transparency & Explainability
Transparency in data science and artificial intelligence refers to the ability for stakeholders to understand how a model works and how it is making its predictions. It is important to discuss the importance of transparency in building trust with users of the model and its significance in auditing the model. Some models are easy to understand, like decision trees (that are not too deep) and linear or logistic regression models. You can directly interpret the weights of the model or walk through the decision tree.
Transparent models have a downside: they usually perform worse than black box models like random forests, boosted trees or neural networks. Often, there is a trade off between understanding the workings of the model and the performance. It’s a good practice to discuss with stakeholders how transparent the model needs to be. If you know from the beginning that a model should be interpretable and fully transparent, you should stay away from black box models.
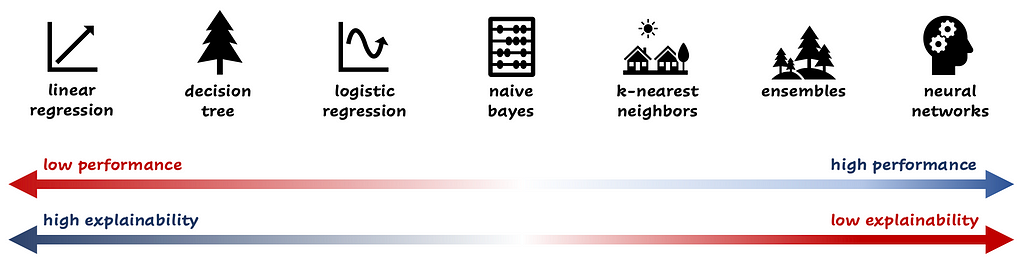
Closely related to transparency is explainability. With the increasing use of complex machine learning models, it is becoming more difficult to understand how the model is making a prediction. This is where explainability of models comes into play. As model owner you want to be able to explain predictions. Even for black box models, there are different ways to explain a prediction, e.g. with LIME, SHAP or global surrogate models. This post explains these methods in depth.
Robustness
Robustness refers to the ability of an AI system to maintain its performance and functionality even when facing unexpected or adversarial situations, such as inputs that are significantly different from what the system was trained on, or attempts to manipulate the system for malicious purposes. A robust AI system should be able to handle such situations correctly, without causing significant errors or harm. Robustness is important for ensuring the reliable and safe deployment of AI systems in real-world scenarios, where the conditions may differ from the idealized scenarios used during training and testing. A robust AI system can increase trust in the technology, reduce the risk of harm, and help to ensure that the system is aligned with ethical and legal principles.
Robustness can be handled in different ways, like:
- Adversarial training, this can be done by training the system on a diverse range of inputs, including ones that are adversarial or intentionally designed to challenge the system. Defense against adversarial attacks should be build in, such as input validation and monitoring for abnormal behavior.
- Regular testing and validation, also with inputs that are significantly different from the ones it was trained on, to ensure it is functioning as intended.
- Human oversight mechanisms, such as the ability for human users to review and approve decisions, or to intervene if the system makes an error.
Another important part is to update and monitor the model on a regular basis (or automatically). This can help to address any potential vulnerabilities or limitations that may be discovered over time.
Privacy
Data science and artificial intelligence often rely on large amounts of personal data, which raises concerns about privacy. Companies should discuss the ways in which data can be used responsibly and the measures that can be taken to protect individuals’ personal information. The EU data protection law, GDPR, might be the most famous privacy and security law in the world. It’s a big document, luckily there are good summaries and checklists available. In short, the GDPR demands that companies who handle personal data of EU citizens ask for consent, notify security breaches, are transparent in how they use the data and follow Privacy by Design principles. The right to be forgotten is another important concept. A company that violates the GDPR can risk a huge penalty, up to 4% of the annual global revenue generated by the company.
All the major cloud providers offer ways to ensure that sensitive and personal data is protected and used in a responsible and ethical manner. The tools are Google Cloud DLP, Microsoft Purview Information Protection, and Amazon Macie. There are other tools available.

Accountability
Accountability in AI refers to the responsibility of individuals, organizations, or systems to explain and justify their actions, decisions, and outcomes generated by AI systems. Organizations need to ensure that the AI system is functioning properly.
Someone needs to be responsible when the AI makes wrong decisions. The opinions among developers differ, like you can see in this StackOverflow questionnaire. Almost 60% of the developers say that management is most accountable for unethical implications of code. But in the same questionnaire, almost 80% thinks that developers should consider ethical implications of their code.
The one thing everyone seems to agree on is: people are responsible for AI systems, and should take this responsibility. If you want to read more about accountability related to AI, this paper is a great start. It mentions barriers for AI accountability like that often many people work on deploying an algorithm, and that bugs are accepted and expected. This makes it a difficult topic in AI governance.
Conclusion
As machine learning becomes increasingly prevalent in our lives, it is crucial to design and deploy these systems in a manner that aligns with societal values and ethics. This involves factors such as privacy, transparency, and fairness. Organizations and individuals should adopt best practices, such as collecting and processing data in a manner that upholds privacy, designing algorithms that are transparent and interpretable, and examining systems to prevent discrimination against certain groups. By taking these ethical considerations into account, machine learning technology can earn trust and minimize negative impacts, benefiting all.
Related
- Detecting Data Drift with Machine Learning
- Model-Agnostic Methods for Interpreting any Machine Learning Model
- Interpretable Machine Learning Models
Ethical Considerations In Machine Learning Projects was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/ethical-considerations-in-machine-learning-projects-e17cb283e072?source=rss----7f60cf5620c9---4
via RiYo Analytics









No comments