https://ift.tt/urYeECk How to compare ML models reliably We often hear or read that modern Machine Learning (ML) research lacks scientifi...
How to compare ML models reliably
We often hear or read that modern Machine Learning (ML) research lacks scientific rigor. After a few years conducting research in ML and reviewing papers for conferences and journals, I now think that I have a good understanding of how to assess rigorously the effectiveness of an ML approach. This post is intended as a simple guide to help ML researchers and developers to design proper experiments and analyses to evaluate their work. Hopefully, after reading this post, you should never struggle again to know how to evaluate reliably the performance of your ML models. For junior ML researchers, this post will also help you understand what experiments are expected to convince reviewers that your work deserves to be accepted to your dream conference.
Different flavors of Machine Learning research
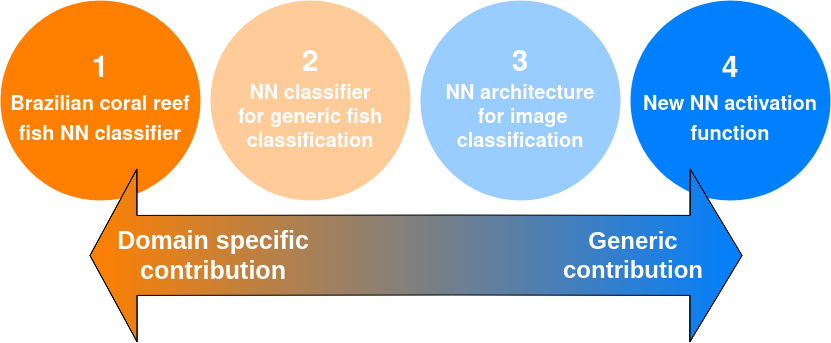
First, it is essential to underline that there are different ways to contribute to the broad field of ML, which do not require the same kind of experimental analyses. On the one hand, some applied works might use ML to solve domain-specific tasks. On the other, some researchers are interested in developing generic ML techniques that can be used to address any kind of data-related problem. Obviously, this classification of ML research topics is not binary, but rather a continuum. Let’s discuss some concrete examples to illustrate this specificity-genericity spectrum:
- We want to build a neural network that can accurately classify images of fish in the coral reefs in northeast Brazil — product placement for my own research.
- We want to find a good neural network architecture for the classification of fish images.
- We want to design a good neural network architecture for image classification.
- We want to introduce a new activation function that would be good to use in any neural network, independently of the input data format.
Each of these works can be meaningful and impactful, but we can easily understand that they have different levels of genericity, as displayed in the figure below.
Depending on the level of genericity of the research topic, different kinds of experiments and analyses are expected, which might be confusing sometimes. So let’s try to clarify what proper ML evaluation should look like, depending on the kind of approach discussed.
Evaluation of a domain-specific ML approach
Let’s start with example 1, a very specific image classification problem. Here, the goal is to build a good ML model (probably a neural network), that can correctly classify images of fish in the coral reefs in northeast Brazil. This model will be used by ecologists studying this precise ecosystem in order to accelerate their research. If we want to solve this problem, we can collect images of fish from the ecosystem of interest and label them with species information to build a dataset (or we can use an existing dataset, if available).
First, we need to pay attention that the dataset used is representative of the application domain, i.e., what will be encountered during inference. In our example, this can be done by making sure that several locations from the study area are present in the dataset, and that all possible local species are represented. Then, if we want to compare two ML models (X and Y) on this dataset, we need to
- Choose our favorite evaluation metric — usually accuracy for classification, but it can also be precision or recall if we want to understand performance for rare species. More information about classification metrics: here.
- Conduct a proper cross-validation scheme, or at least a train-test split evaluation if our dataset is large and training is slow. More information about cross-validation testing: here. We just need to be careful that the dataset is randomized properly before splitting, and that the train and test splits do not contain very similar images such as consecutive video frames, which would bias the evaluation.
In this context, it is perfectly fine and rigorous to do this relatively simple evaluation and to claim that the best model is the one with the best test values for the chosen metric. However, let’s be careful and not jump to hasty, unfounded conclusions. We just showed that X is better than Y at the specific task studied (classifying fish in northeast Brazilian reefs), and nothing more. No generic conclusion can be drawn about the superiority of X over Y for image classification, or even generic fish classification.
Evaluation of a generic ML technique
At the other end of the spectrum, let’s now discuss how to evaluate highly generic ML approaches, such as example 4. Here, our goal is to show that using our new shiny activation function is good for any neural network design, independently of the application domain. In this case, the expected efforts to spend on evaluation are different. We should use a pool of datasets comprising diverse types of data, from various domains (e.g., images, text, audio, etc.) and tasks (e.g., classification, regression). Then, we can compute proper test metrics for each of these datasets. Many ML papers actually stop here and report huge tables comparing their approach against other techniques from the literature on various datasets. This is insufficient and often the reason for these “lack of rigor in ML” complaints. Indeed, the reader should not be expected to look at all these independent results and draw conclusions about which approach is the best.
Instead, if we see that our approach X is often better than Y, we must prove it by using proper statistical testing, in order to verify that the superior results could not have happened by chance. Generally, a good choice to compare two ML models over multiple datasets is to conduct a Wilcoxon signed-rank test, but I won’t go over the details here (let me know if I should cover it in a later post).
Different from domain-specific ML approaches, less care can be taken to ensure that each individual dataset is relevant for its own application domain. However, if we want to show that an approach is good for a specific kind of problem (e.g., image classification), then our pool of evaluation datasets must be representative of the domain.
Is my approach specific or generic?
So far, we’ve discussed the extreme cases of our specificity-genericity spectrum. However, sometimes it is not so easy to decide whether a research topic is specific or generic. For example, should we consider that example 2 is specific to the domain of fish classification, and build a large dataset containing images of fish from all around the world? Or should we consider that it is a generic fish classifier and verify if it works on several fish images datasets from different ecosystems? Likewise, for example 3, should we consider that our new architecture is specific to images or a generic image classifier?
The answer to these questions is the famous: “it depends”, but I will still try to provide some elements to respond. The idea here is to ask ourselves: what is the intended use of the proposed approach?
- If we think that our model can be used directly to solve real-world tasks without retraining, then it should be treated as a domain-specific approach. For example, a fish classifier that works for any ecosystem, without fine-tuning.
- If we think that our approach is more of a methodology on how to train efficient models on specific subdomain datasets, then it can be considered a generic approach.
Link between specific and generic results
We all agree that the results obtained on a domain-specific dataset should not be used to claim the superiority of an approach in a broader, generic context. However, specific results can still be useful to reach generic conclusions in the future if they are used in meta-analysis studies.
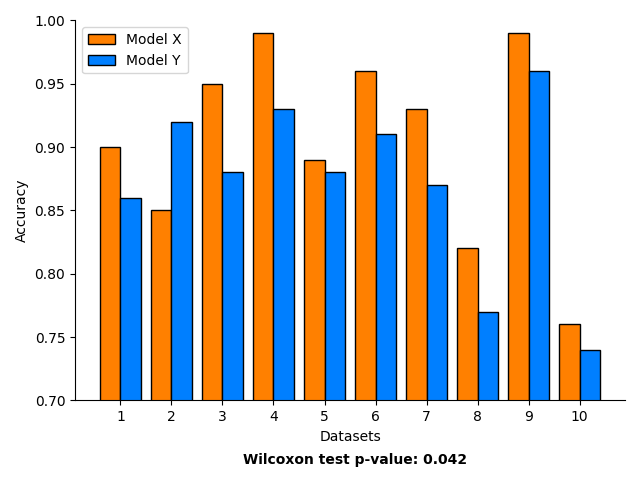
What is less obvious is that the opposite is also true: good generic results should not be used to justify deploying an approach on a specific context. If an approach is shown to be good for image classification, we might be tempted to use it for our specific image classification problem without further validation. However, we should be very careful here, because even if it is proven that an approach is good on average for a wide variety of tasks, it does not mean that it is good at every single specific task. For example, in the figure below, X is provably better than Y in general (p value < 0.05), but if we are interested in solving the task corresponding to Dataset 2, we should rather use Y. Generic results should be used as development guidelines about what is likely to work and what to try first for your specific task.
Practical limitations
Once we have identified all the necessary experiments to evaluate our new approach, it is sometimes hard to actually conduct them all (time and budget constraints, unavailable datasets). It is often fine not to do everything perfectly, but at least when you discuss your results, you should be aware of what you did not do. This way, you can adjust your claims and conclusions accordingly. There is no correct or wrong way to conduct ML evaluation in general, we simply need to avoid claims that are not backed up by experiments.
Conclusion
Designing rigorous ML experiments might seem overwhelming, but it is actually not so hard. One just need to:
- Identify precisely the kind of ML approach he is trying to evaluate: specific or generic.
- For domain-specific ML models: collect a representative dataset, choose a relevant evaluation metric and apply a proper cross-validation scheme.
- For generic ML techniques: collect a set of representative datasets, compute the evaluation metric for each of these datasets, apply a proper statistical test to confirm intuitive conclusions.
If you found this post useful, please consider following me on Medium to be notified of my future posts about ML research, and on Twitter if you want to know more about my research work.
All the images used in this post were created by the author.
A Quick Guide to Design Rigorous Machine Learning Experiments was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/a-quick-guide-to-designing-rigorous-machine-learning-experiments-21b19f067703?source=rss----7f60cf5620c9---4
via RiYo Analytics







ليست هناك تعليقات