https://ift.tt/hVt4MWA There’s no I in Governance 🙃 As we all know, we’re in the golden era of the modern data stack. It’s never been so ...
There’s no I in Governance 🙃
As we all know, we’re in the golden era of the modern data stack. It’s never been so fast and easy to plug and play with highly flexible and scalable data tools. We’re agile! We’re data-driven! We’re living the self-serve, democratized-data dream!

But with every upside, there’s a downside: the easier it is to produce and consume data across an ever-growing set of systems, the faster our beloved modern data stack becomes a tangled web of complex interdependencies. We become less agile and, instead, spend more and more time tending to an ever-growing backlog of broken pipelines, transformation logic, dashboards, and more. Self-serve resources begin producing conflicting results, frustrating our core stakeholders and planting seeds of doubt in our ability to make data-driven decisions.
Inevitably, this turns into conversations around data ownership, documentation, tagging, classifying, and more; data governance becomes the silver bullet that can fix it all! But where do we even start? Who is responsible, and for what?
Sounds daunting, right? It doesn’t have to be! Let’s work through an iterative framework to introduce data governance within your organization.
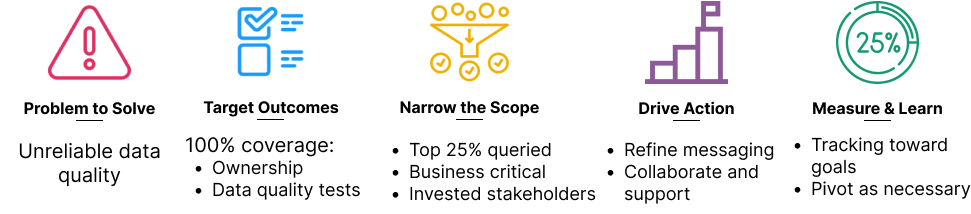
Step 1. Identify the problem(s) to solve
First and foremost, take the time to clearly define what problem(s) you’re seeking to solve that may be addressed by data governance practices. For example:
- Adherence to evolving compliance/regulatory requirements requires time-intensive and redundant manual auditing of data sources. We don’t have a standard definition of data sensitivity, so the outcomes vary based on who performs the audit.
- Our monthly data storage and processing costs are out of hand. We need to cut costs as soon as possible, but we don’t know who owns what or how it’s leveraged within the organization.
- Our team spends 20% of dev time fixing broken pipelines due to unreliable data quality of upstream data sources. Data quality issues should be detected at the source and resolved by the team that owns the data source.
Let’s hone in on the third problem as we walk through the framework:

Step 2. Set clear goals
Now that you’ve identified the targeted problem to solve and have an idea of how to address it, it’s time to set some concrete goals to work toward.
Take the time to think through the problem at hand: what action can others take to resolve the issue? What goals can you set for others to work toward? If all goes as planned, what measurable impact will this effort have?
Let’s continue with our unreliable data quality example, where we want data quality issues to be detected at source and resolved by the appropriate team. This means we’re targeting two goals: 1) assign data ownership and 2) build data quality test coverage for all assets. As a result, we expect to see a decrease in time spent resolving broken data pipelines.

Easy peasy, right? We know what problem to solve, how to solve it, and how to measure the impact. Let’s keep movin’ along.
Step 3. Start small before you go big
You know that solution we just came up with in Step 2? Resist the urge to roll it out to all data assets, all at once. This is especially important when you’re starting with thousands (or hundreds of thousands!) of resources and delegating out to 10’s or 100’s of individuals.
🤦🏼♀️PSA: It is a bad idea to dump 180k column names into a Google sheet and expect an entire Engineering Organization to agree to add documentation just because you asked nicely. They will laugh you out of the room and you will cringe every time you think about it for years to come. 🙃🙃
Instead, start with a subset of high-impact, low-complexity data resources and highly-invested stakeholders to team up with you — this is where we start making data governance a team sport!
Let’s go back to our poor data quality example: we set a very lofty goal of assigning ownership and data quality tests to 100% of data entities. We’ll refrain from trying to hit that big goal all at once, and instead we’ll start with a narrow subset of resources that are:
- Owned by highly-invested stakeholders
- Queried with a high frequency
- Leveraged in business-critical pipelines, models, reports, etc.

By keeping a narrow scope of data entities, you’ll be able to focus more on designing repeatable, cross-team data governance workflows.
Step 4. Drive incremental action
You’ve done the work to define what problem to solve, the targeted outcomes, and which resources to tackle; now it’s time to enable others to take action. This is the opportunity to work closely with your initial stakeholder group to test-drive the initiative to inform a larger-scale roll-out in the future.
Here are some questions to keep in mind as you’re enabling others to take action:
- Is it obvious? “The Why” should be obvious to them; it should be clear why this work is worthwhile and impactful
- Is it easy? “The What” should be clearly defined so they can focus on execution
- Is it collaborative? Don’t overprescribe “The How”; focus on the mutual end goal and encourage them to build a process/solution that fits into their existing workflows
Last but not least, create rapid feedback loops and proactively solicit feedback. Where are your stakeholders missing context? Which actions are difficult for them to take? What type of ongoing support will they need?
Jumping back to our unreliable data quality example, we’ve asked our highly-invested stakeholders to officially take ownership of, and add data quality tests to, their top 25% most-queried, buisness critical data assets. During this step, we should be focused on making sure they:
- Understand that the lack of data quality tests has a large impact on downstream resources
- Understand our expectations of data owners
- Can easily create and monitor data quality tests on in-scope resources

Step 5. Measure progress and learn
Now that you have a cross-team data governance workflow up and running, it’s time to measure progress and determine what’s working and what’s not:
- Are you making progress towards your stated goals?
- Are the goals still the right ones?
- Are your stakeholders supportive of the initiative?
- What do you need to change/alter before rolling out to an additional set of stakeholders?
Step 6. Iterate!
You’ve made it to the final step! Now it’s time to start over from the beginning, apply what you have learned, and refine these workflows as you go.
A couple of parting thoughts
Don’t let perfection be the enemy of good — just because you can’t perfectly govern every single data entity within your stack doesn’t mean it isn’t worth governing a subset. Focus on impact, not perfection.
Get comfortable with reevaluating your goals/target outcomes and helping your stakeholders pivot as needed. Listen to their feedback. Remember you’re asking them to take on additional work, so do your best to make it worth their time (and not because we set a goal that one time, so we may as well do it.)
I’d love to hear how you are tackling data governance in your organization — let’s iterate on this framework together! You can contact me any time via DataHub Slack — I can’t wait to hear from you!
Data Governance, but Make It a Team Sport was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/data-governance-but-make-it-a-team-sport-30dc0164fb7c?source=rss----7f60cf5620c9---4
via RiYo Analytics







No comments