https://ift.tt/uXKILfR Classify document entities using LayoutLM Model Photo by Scott Graham on Unsplash Introduction Visually-rich ...
Classify document entities using LayoutLM Model

Introduction
Visually-rich Document Understanding (VrDU) aims to extract structured information from the business documents (scanned images or PDFs). This is essential for a variety of applications:
- Utilising the current invoice template while onboarding to the new financial application
- Auto-filling customer and product meta data from digital documents (scanned image or PDF) during onboarding to the new financial application
- Creating a transaction in the financial application using a digital document (scanned image or PDF)
The goal of this task is to understand the invoice and extract necessary information. To put it simply, this is similar to the text tokenisation problem in NLP. However, if we approach this as an NLP problem, we will be ignoring the visual and layout features. Hence, we need a framework which can leverage multi-modalities like text, visual and layout.
Recent developments in the multimodal deep learning field have made it possible by incorporating text, layout and image features in their architecture. In this blog we will introduce one such model, LayoutLM and its versions.
Problem Statement:
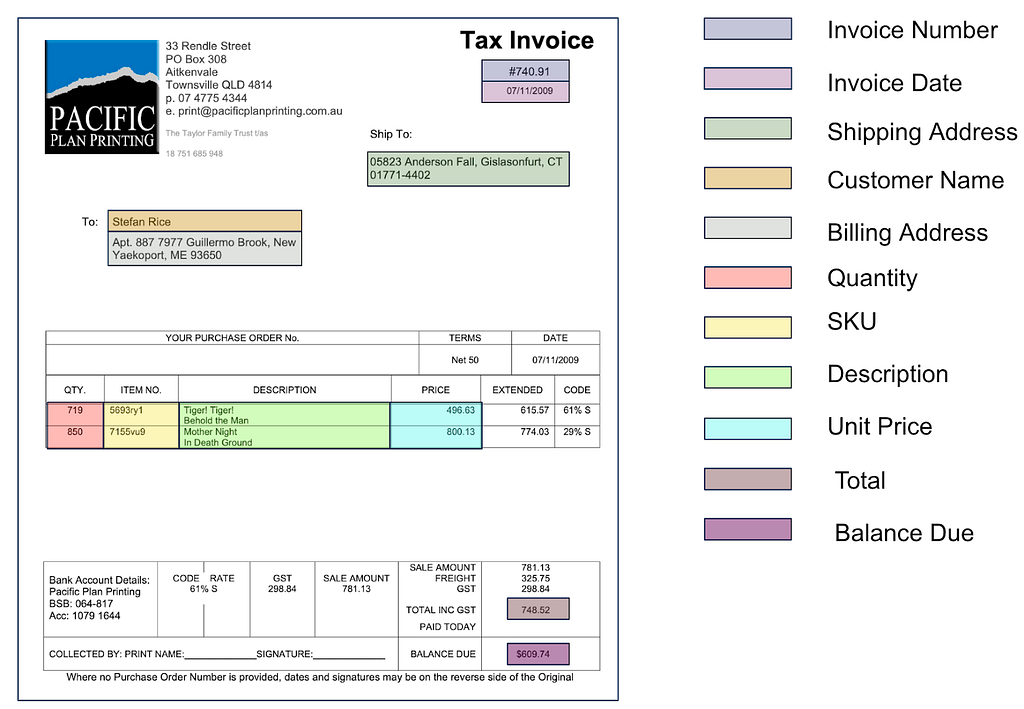
Given an Invoice (scanned image or PDF), extract structured information like invoice number, invoice date, shipping address, etc.
LayoutLMv1 Model:
There are three main building blocks in the LayoutLM model architecture:
- Text: Bi-directional Encoder Representation from Transformers (BERT)
- Layout: 2-D Positional Embeddings
- Image: Faster R-CNN (Regional Based Convolutional Neural Network)
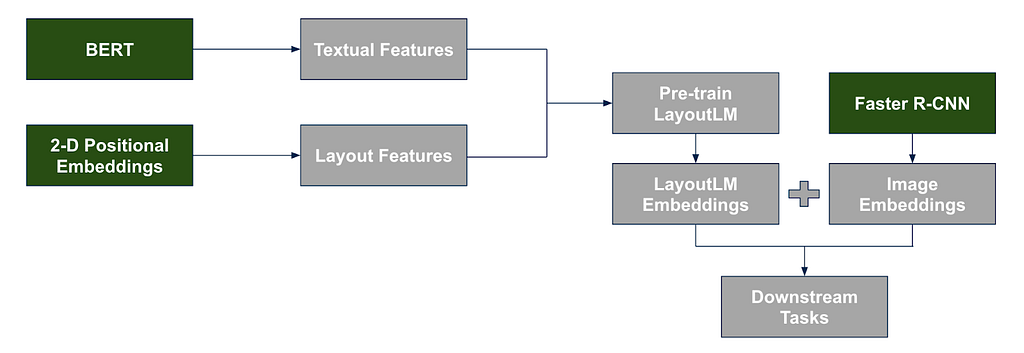
This is the first model which leverages both text and layout information during the pre-training phase. Also, image features combined with the pre-trained embeddings to fine-tune the downstream tasks. LayoutLM uses the masked visual language model, inspired by the masked language model of BERT and multi-label document classification as objectives for pre-training.
Architecture:
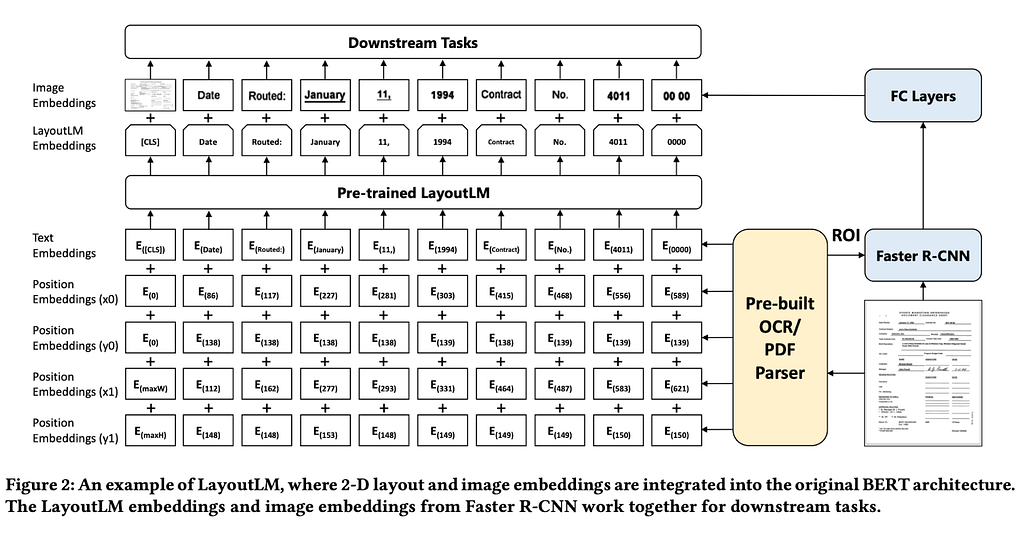
Let’s dig deeper into this architecture to understand each layer.
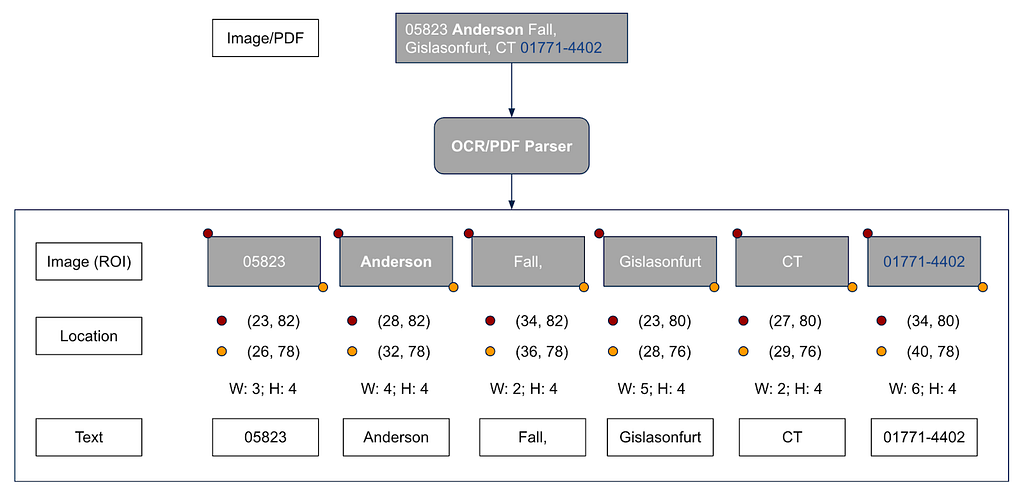
- Initially, scanned image/PDF processed through OCR/PDF parser to get the text tokens, text image, and the bounding boxes
2. LayoutLM models the relative spatial position in a document using 2-D position embeddings. The location of a text can be represented with left top and right bottom coordinates, say (x0, y0, x1, y1). Four position embedding layers added to the architecture with two embedding tables, one for each dimension.
- Visual features capture style and the colour of the text
- Bounding boxes capture the 2-D location within the document and also the size of the text box
- Uses WordPiece tokenisation algorithm to build the vocabulary from the raw text tokens
- Considers each of the text image box as a ROI (Region Of Interest) and used Faster R-CNN to get the visual features for each text image box
3. LayoutLM models the relative spatial position in a document using 2-D. position embeddings. The location of a text can be represented with left top and right bottom coordinates, say (x0, y0, x1, y1). Four position embedding layers added to the architecture with two embedding tables, one for each dimension
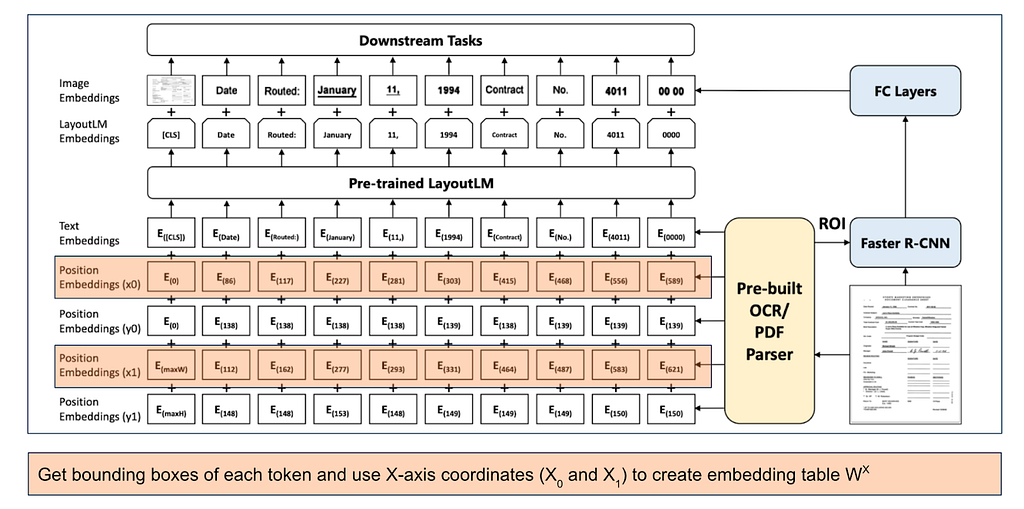
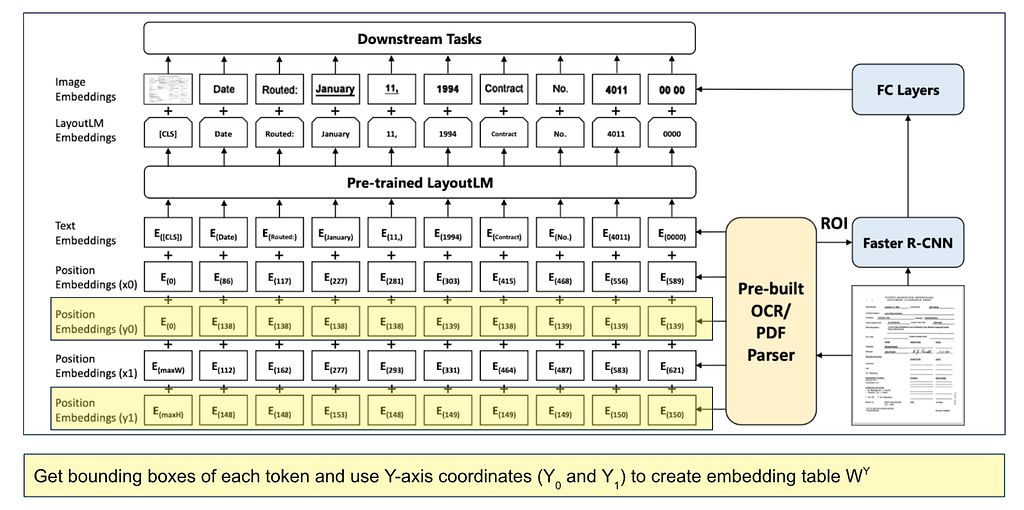
- Text sequence starts with the [CLS] token
- X1 and Y1 position embeddings uses maximum width and maximum height of all the bounding boxes corresponding to [CLS]
- X0 and Y0 position embeddings uses zero vector corresponding to [CLS]
- Authors have added embedding layers for width and height too (This is missing in the above architecture)
4. Utilized WordPiece tokenization to get the vocabulary and an embedding layer added to represent the tokens. Additionally, a 1-D position embedding layer was added to take the position of the token within the segment into consideration (This is missing in the above architecture)
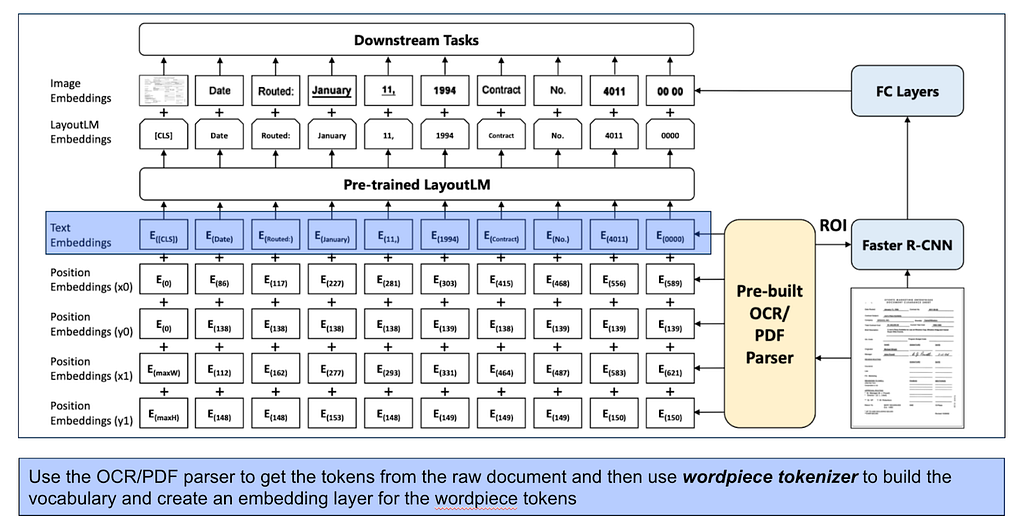
Let me take a de-route here to explain what an embedding layer is. Model cannot directly consume bounding box coordinates and raw text tokens. Hence, we need a numerical representation of these things, which are called embeddings.
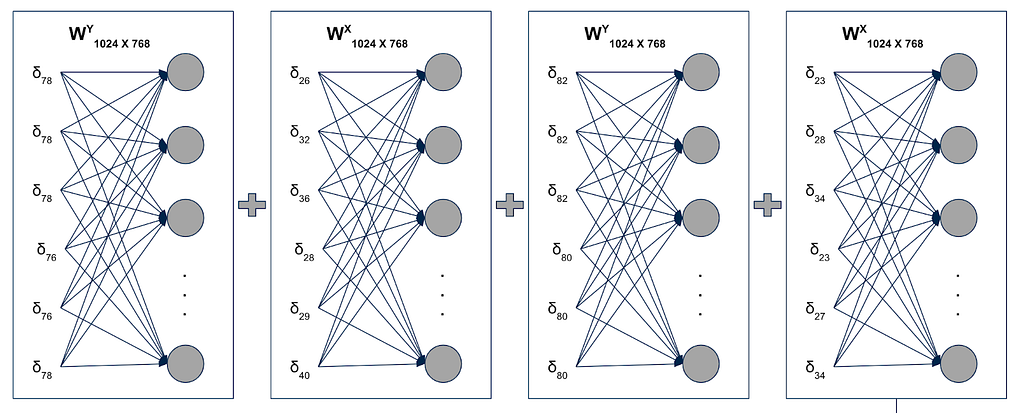
Note: Authors rescaled the bounding boxes to [0, 1000] but they represented positions with 1024 vector, last 24 values are unused
Where, δx is the one-hot vector of size 1024 with one at index x and rest all zeros. Similarly there will be three more embedding layers for width, height and 1-D positions
Pre-training LayoutLMv1:
LayoutLM model is pre-trained on the IIT-CDIP test collection 1.0, which contains more than 6 million documents, with more than 11 million document images. It also has the document labels (multi-label)
Masked Language Model (MLM):
It is inspired by the Masked Language Model (MLM) task from BERT. MLM proposes to mask (replace with [MASK] token) 15% of the tokens randomly.The model is trying to predict the words it hasn’t seen while taking into account all the context around it, which reduces overfitting. However, this approach learns to predict good probabilities only for [MASK] tokens and we won’t be having [MASK] tokens during prediction or fine-tuning time. As a result, it won’t be able to predict good contextual embeddings using training data.
Researchers proposed masking 80% of the randomly selected 15% tokens and replacing some random token for the remaining 20% to solve this issue. It performs better than the aforementioned method since it also calculates the loss for the non-masked tokens. However, the model learns the default pattern that every random token is mapped to a different token.
To solve this problem, researchers proposed masking 80% of the randomly selected 15% tokens, replacing some random token for the 10%, and not changing the token for the remaining 10% of them.
Masked Visual Language Model (MVLM):
LayoutLMv1 randomly masks tokens as explained above but it keeps the corresponding 2-D position embeddings to predict the masked word during pre-training. It bridges the gap between the visual and language modalities by utilizing the 2-D position embeddings to predict the masked tokens.
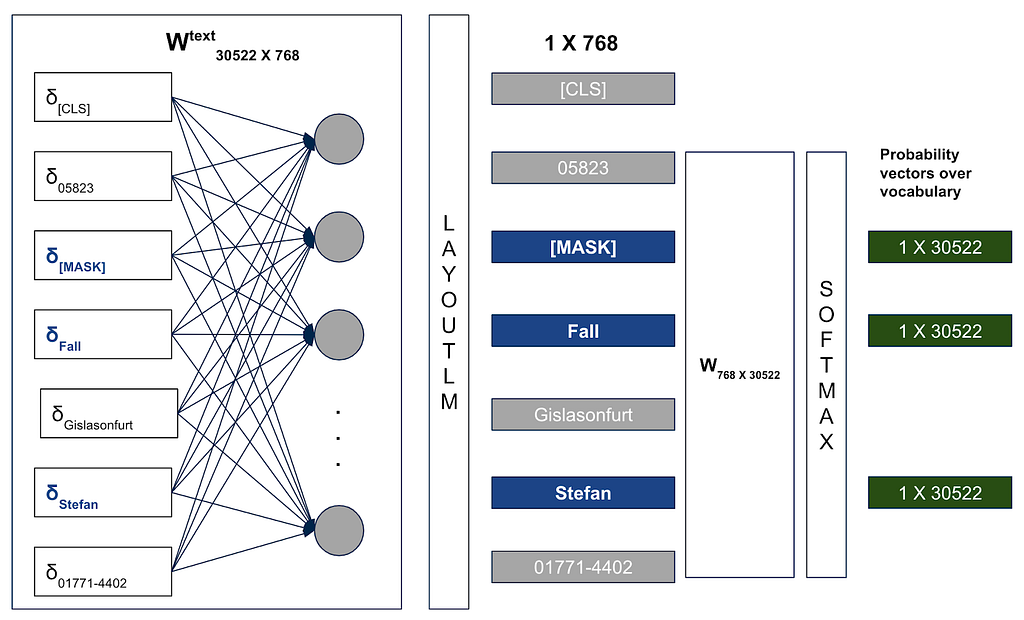
Note: Token embeddings in the above architecture has pre-added with 2-D positional, 1-D positional, width and height embeddings
Masked Anderson token in our previous example; Replaced CT token with Stefan; The Fall token was left unchanged
Default vocabulary size set to 30,522. Where δt is the one-hot vector of size 30,522 with one at token t’s index (each of the token in the vocabulary is assigned an integer index between [1, 30,522])
Note: The text embeddings in the above architecture were summed up with the 2-D position, width, height, and 1-D position embeddings before passing it to the LayoutLM
- The sole difference between the LayoutLMv1 layer in the above design and the BERT architecture is that it also takes into account 2-D position, width, and height embeddings in addition to text embeddings. Here is an excellent blog to understand BERT
- LayoutLM produces 1 X 768 numerical vector for each of the token, which is then passed through a fully connected hidden layer with a size of 30,522
- Soft-max layer was used to obtain the probability distribution over the vocabulary
- Training loss computed only for the randomly chosen 15% tokens
Visual features extracted from each of the token’s images added to the respective token embeddings and features extracted from the entire image added to the [CLS] token embedding. Final embeddings are utilised in numerous downstream tasks, including form understanding, receipt understanding, and document classification.
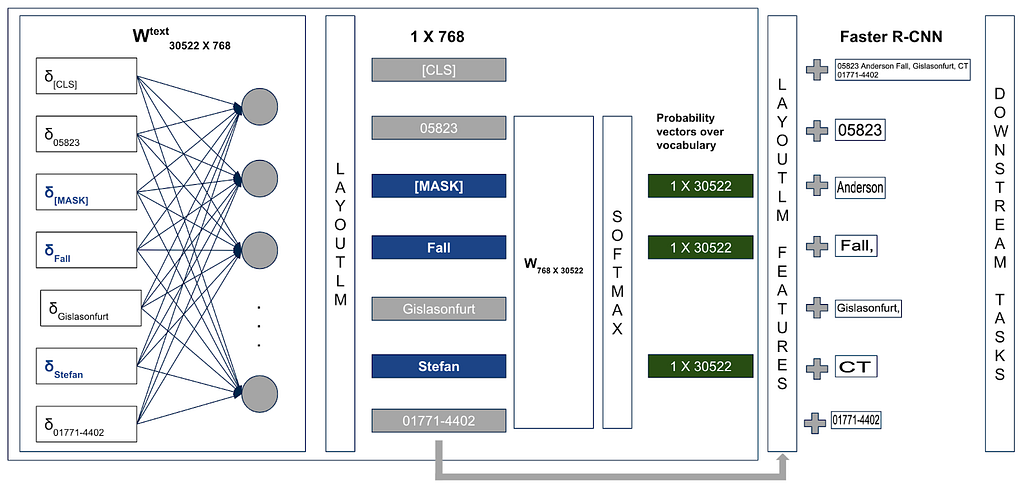
Multi-label Document Classification (Optional):
Document-level representations are useful for many document image understanding tasks. The IIT-CDIP collection contains multiple tags for each of the document. Researchers used Multi-label Document Classification (MDC) loss during pre-training to get the meaningful document-level representations. [CLS] embeddings added to the entire document image features used to pre-train the classifier.
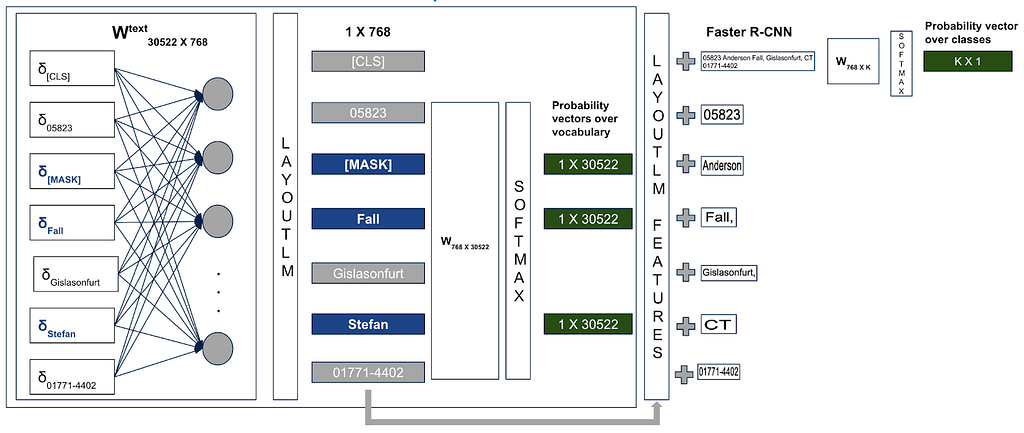
Since this pre-training task requires labels for very large datasets, researchers set this as an optional for any future pre-training tasks
LayoutLMv2 Model:
MVLM in LayoutLMv1 pre-trained on textual and layout features, it doesn’t leverage image features while pre-training. LayoutLMv2 proposes incorporating image features during the pre-training phase itself.
Changes in v2:
- Visual features combined during pre-training stage to learn the cross-modality interaction between text and visual information
- Proposed spatial-aware self-attention mechanism to model relative position information explicitly
- Text-image alignment strategy, which aligns text lines and the corresponding image regions
- Text-image matching strategy to learn whether document image and textual content are correlated
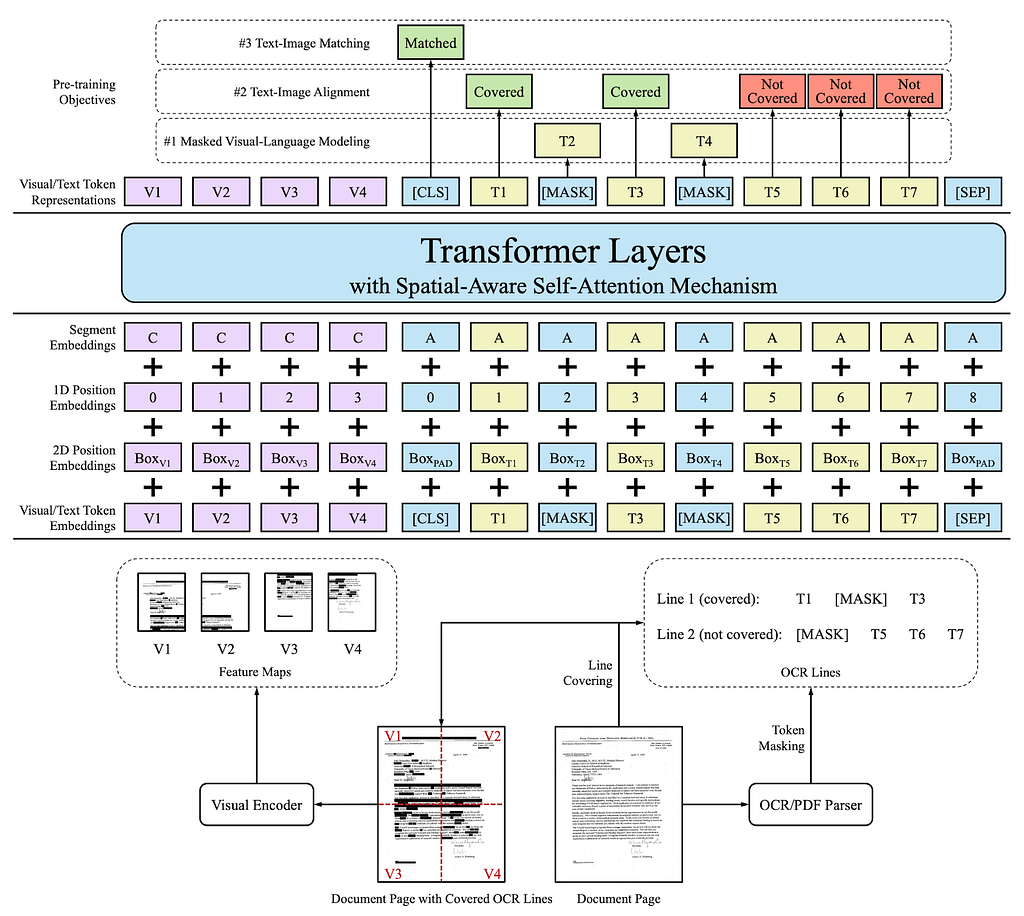
During the pre-training phase LayoutLMv2 uses text embeddings, layout embeddings and visual embeddings
Embeddings:
Text embeddings:
It uses WordPeice to tokenise the text and assigns each token to a segment (analogous to sentence), also adds [CLS] token at the beginning of the text sequence and [SEP] token between two segments. To ensure all of the segments are of the same length, it truncates the longer sequences at max sequence length and adds [PAD] token to shorter sequences. The final text embedding is a sum of three embeddings: token embedding, 1-D position embedding, segment embedding
Visual Embeddings:
Leverages output feature maps of a CNN-based visual encoder to transform a document image into a fixed-length sequence as shown in the above architecture. Resizes a document image to 224 X 224 and feds it to the visual backbone. After that, the output feature map is average-pooled to fixed size width W and height H. A linear projection is applied on feature maps to get the same dimension as text embeddings. Since CNN-based visual backbone cannot capture the position information, added 1D position embedding to the visual embeddings. Also, assigning all of the visual tokens to segment [C] to train the segment embeddings
Layout Embeddings:
In the v2 model, normalised and discretised all the bounding boxes to integers in the range [0, 1000]. Trains two embedding layers, one for x-axis and width and other for y-axis and height. The final layout embedding of a token is the concatenation of all six embeddings (x0, x1, width, y0, y1, height). An empty bounding box (0, 0, 0, 0, 0, 0) is assigned to special tokens [CLS], [SEP] and [PAD].
Spatial-Aware Self-Attention Mechanism:
Self-Attention Mechanism:
Traditional NLP methods like bag of words and Tf-Idf are able to quantify the importance of a token using term frequency and/or inverse document frequency in the corpus. Sequential deep learning models like RNN, LSTM and GRU are successful in capturing long term dependencies but are not able to quantify the importance of tokens. To get the best out of both worlds researchers introduced self-attention mechanism in deep learning models to focus more on the important tokens.
Let’s understand the self-attention using an example:
“FIFA World Cup was held in Qatar”
In the above sentence, Qatar was mentioned in the FIFA world cup context. If we use W2V models (skip-gram or continuous bag of words) to get the vector representation for the above words it won’t be able to capture the context within the representation. Objective of the self-attention mechanism is to get contextual based representations for the tokens.
To more precisely, if we have two sentences as below:
“FIFA World Cup was held in Qatar. The capital of Qatar is Doha.”
The contextual representation of Qatar in the first sentence is different from the representation in the second sentence
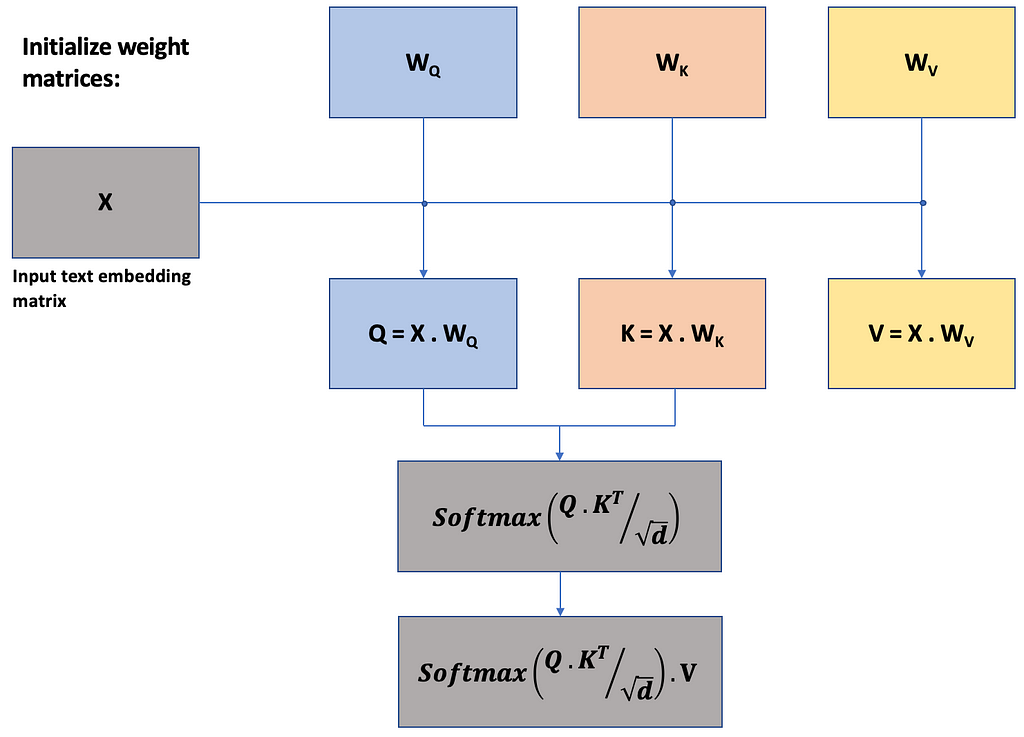
Self-attention mechanism focuses on computing attention scores and weighted sum of the value matrix, it has nothing to do with the position of the token within the segment and location of the token within the document. Authors proposed spatial-awareness, which adds learnable parameters for 1-D position within the segment, width and height of the bounding box
Self-attention explained in vectorised format by passing entire input text embedding at once. For a better understanding splitting the above example into token level
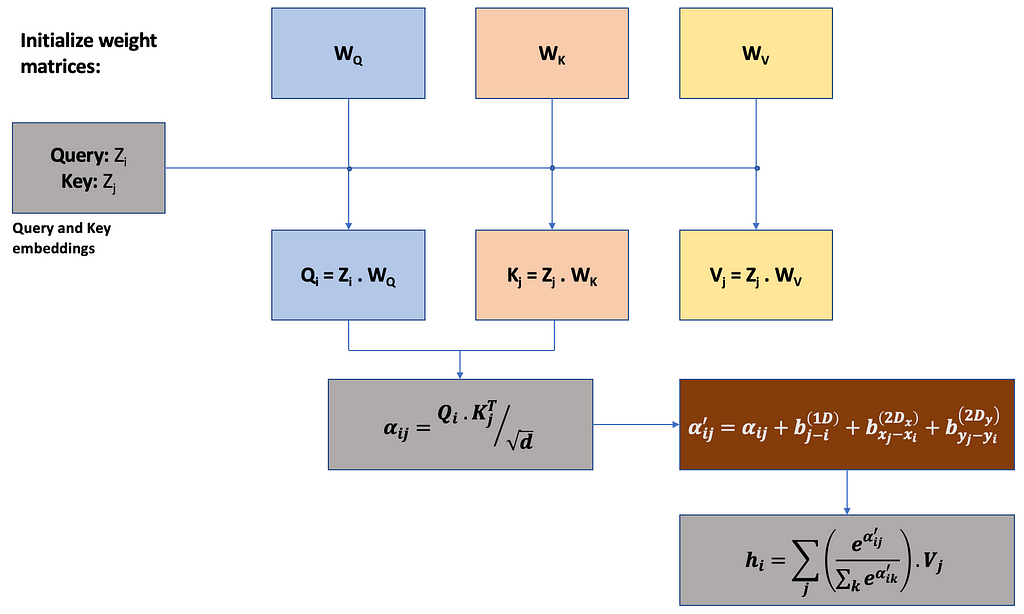
where, (xᵢ, yᵢ) is the left-top coordinate of the ith bounding box;
b_(j-i)^((1D) ) learns the positional distance between query and key;
b_(x_j-x_i)^((2D_x ) ) and b_(y_j-y_i)^((2D_y ) ) learns location distance between query and key
Pre-training LayoutLMv2:
Task 1 — Masked Visual Language Modelling (MVLM):
Similar to LayoutLMv1, v2 also uses the MVLM pre-training task. It randomly masks some text tokens and train model to predict them, while the layout information is unmasked. In addition to this, to avoid visual clue leakage authors masked image regions corresponding to masked tokens on the raw image.
Task 2 — Text to Image Alignment (TIA):
MVLM helps in learning cross-modalities between text and layout by considering the layout information to predict the masked tokens. Whereas, TIA aims to learn the spatial location correspondence between image and co-ordinates of bounding box. It randomly covers the entire line in the document and a classification layer added above the encoder layer to predict whether a token is covered or not. Please note that, authors used [COVER] just to avoid the confusion with [MASK] operation. Reason for covering the entire line instead of token is that, some tokens like signs and bars may look like a covered text regions, hence the task of predicting token level cover can be noisy.
Task 3 — Text to Image Matching (TIM):
TIM aims to learn the correspondence between the document image and textual content. Output representation at [CLS] fed into a classifier to predict whether the image and textual content are from the same document or not. Usual inputs are positive, to generate negative examples an image is either replaced by other document’s image or dropped.
Each of the aforementioned techniques trying to learn cross-modality interaction between modalities. Summarising the same in the below table:
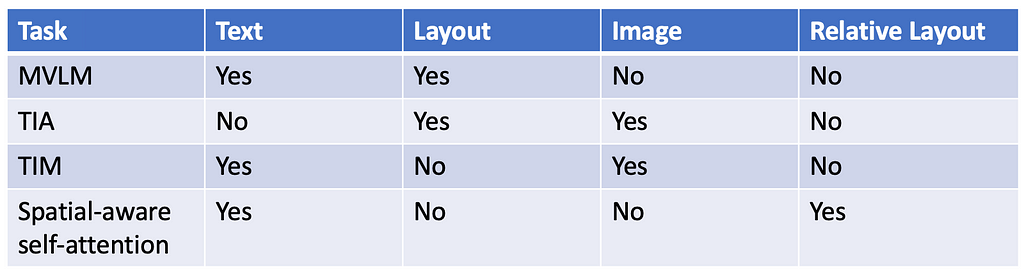
Fine-tuning LayoutLM:
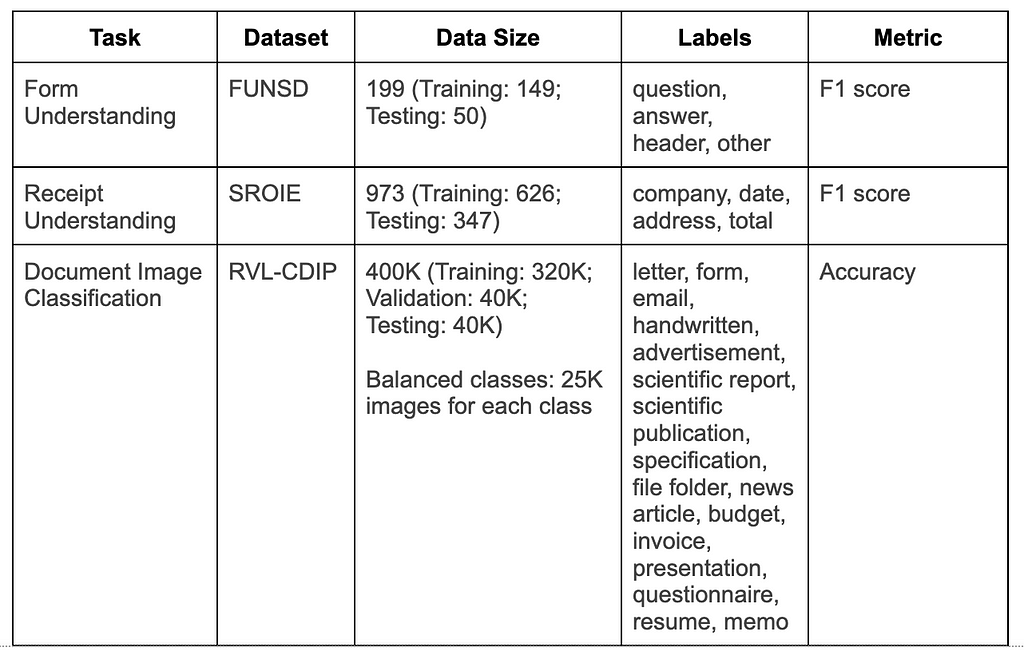
Advantages of LayoutLM:
- Existing document understanding models rely on the limited labeled data, while ignoring the massive unlabelled data. Pre-training LayoutLMv1 (with only MVLM) does not require any labeled data
- Most of the existing models leverage pre-trained CV models or NLP models but do not consider joint pre-training of text and layout. LayoutLMv1 is the first model, which jointly pre-train both text and layout modalities
In both v1 and v2 authors used MVLM to get text embeddings and Faster R-CNN to get visual embeddings. LayoutLMv3 introduces Masked Image Modelling (MIM) to get visual embeddings and uses Masked Language Modelling (MLM) to get the text embeddings. Authors also introduced Word-Patch Alignment (WPA) to learn the alignment between text and image modalities.
I will talk more about v3 model in my next blog. Thanks for reading till here!!! Your feedback and comments are invaluable for my upcoming blogs.
Business Document Understanding was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/invoice-understanding-468885c9c322?source=rss----7f60cf5620c9---4
via RiYo Analytics






No comments